
The in-person GPU Technical Conference held annually in San Jose may have been canceled in March thanks to the coronavirus pandemic, but behind the scenes Nvidia kept on pace with the rollout of its much-awaited “Ampere” GA100 GPU, which is finally being unveiled today. All of the feeds and speeds and architectural twists and tweaks have not yet been divulged, but we will tell you what we know and do a deep architecture dive next week when that data is available.
Here is the most important bit, right off the bat. The Ampere chip is the successor not only to the “Volta” GV100 GPU that was used in the Tesla V100 accelerator announced in May 2017 (aimed at both HPC and machine learning training workloads) but, as it turns out, the chip is also the successor to the “Turing” TU102 GPU used in the Tesla T4 accelerator launched in September 2018 (aimed at graphics and machine learning inference workloads). That’s right. Nvidia has created a single GPU that can not only run HPC simulation and modeling workloads considerably faster than Volta, but also converges the new-fangled machine learning inference based on Tensor Cores onto one device. But wait, that’s not all you get. With the Ampere chip, Nvidia has also announced that it has been working with the Spark community to accelerate that in-memory, data analytics platform with GPUs for the past several years, and it is now also ready. And thus, now the massive amount of preprocessing as well as the machine learning training and the machine learning inference can now be done all on the same accelerated platforms.
There are still CPUs in these systems, but they are relegated to handling serial processes in the code and managing large blocks of main memory. The bulk of the computing in this AI workflow is being done by the GPUs, and we will show the dramatic impact of this in a separate story detailing the new Nvidia DGX, HGX, and EGX systems based on the Ampere chips after we go through the technical details we have gathered about the new Ampere GPUs.
Let’s start with what we know about the Ampere GA100 GPU. The chip is etched in the 7 nanometer processes of Taiwan Semiconductor Manufacturing Corp, and the device weighs in at 54.2 billion transistors and comes in at a reticle-stretching 826 square millimeters of area.
The “Pascal” GP100 GPU announced in April 2016 was etched with 16 nanometer processes by TSMC, weighed in at 15.3 billion transistors, and had an area of 610 square millimeters. This was a ground-breaking chip at the time, and it seems to lack heft by comparison. The Volta GP100 from three years ago, etched in 12 nanometer processes, was almost as large at 815 square millimeters with 21.1 billion transistors. Ampere has 2.6X as many transistors packed into an area that is 1.4 percent bigger, and what we all want to know is how those transistors were arranged to yield a massive boost in performance.
Figuring out the double precision floating point performance boost moving from Volta to Ampere is easy enough. Paresh Kharya, director of product management for datacenter and cloud platforms, said in a prebriefing ahead of the keynote address by Nvidia co-founder and chief executive officer Jensen Huang announcing Ampere that peak FP64 performance for Ampere was 19.5 teraflops (using Tensor Cores), 2.5X larger than for Volta. So you might be thinking that the FP64 unit counts scaled with the increase of the transistor density, more or less. But actually, the performance of the raw FP64 units in the Ampere GPU only hits 9.7 teraflops, half the amount running through the Tensor Cores (which did not support 64-bit processing in Volta.)
We will be doing a detailed architectural dive, of course, but in the meantime, here are the basic feeds and speeds of the device, and it is just absolutely jammed packed with all kinds of compute engines in its 108 streaming multiprocessors (also known as SXMs):
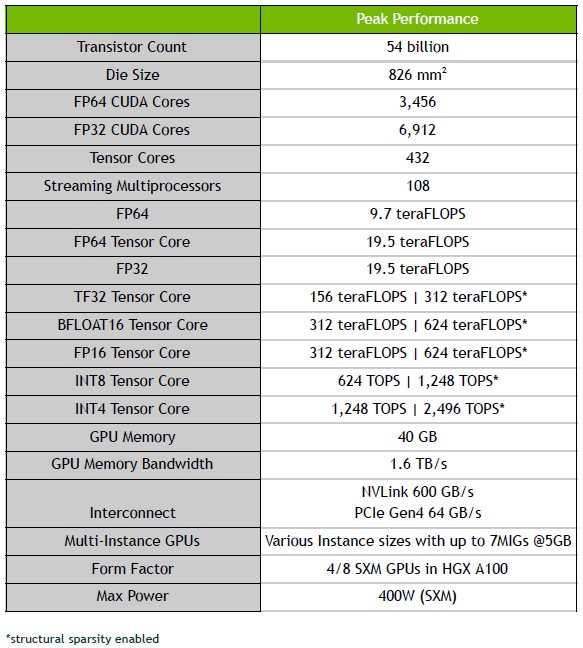
On single precision floating point (FP32) machine learning training and eight-bit integer (INT8) machine learning inference, the performance jump from Volta to Ampere is an astounding 20X. The FP32 engines on the Ampere GV100 GPU weigh in at a total of 312 teraflops and the integer engines weigh in at 1,248 teraops. Obviously, 20X is a very big leap – the kind that comes from clever architecture, like the addition of Tensor Cores did for Volta.
One of the clever bits in the Ampere architecture this time around is a new numerical format that is called Tensor Float32, which is a hybrid between single precision FP32 and half precision FP16 and that is distinct from the Bfloat16 format that Google has created for its Tensor Processor Unit (TPU) and that many CPU vendors are adding to their math units because of the advantages it offers in boosting AI throughput. Every floating point number starts with a sign for negative or positive and then has a certain number of bits that signify the exponent, which gives the format its dynamic range, and then another set of bits that are the signifcand or mantissa, which gives the format its precision. Here is how Nvidia stacked them up when talking about Ampere:

The IEEE FP64 format is not shown, but it has an 11-bit exponent plus a 52-bit mantissa and it has a range of ~2.2e-308 to ~1.8e308. The IEEE FP32 single precision format has an 8-bit exponent plus a 23-but mantissa and it has a smaller range of ~1e-38 to ~3e38. The half precision FP16 format has a 5-bit exponent and a 10-bit mantissa with a range of ~5.96e-8 to 65,504. Obviously that truncated range at the high end of FP16 means you have to be careful how you use it. Google’s Bfloat16 has an 8-bit exponent, so it has the same range as FP32, but it has a shorter 7-bit mantissa, so it has less precision than FP16. With The Tensor Float32 format, Nvidia did something that looks obvious in hindsight: It took the exponent of FP32 at eight bits, so it has the same range as either FP32 or Bfloat16, and then it added 10 bits for the mantissa, which gives it the same precision as FP16 instead of less as Bfloat16 has. The new Tensor Cores supporting this format can input data in FP32 format and accumulate in FP32 format, and they will speed up machine learning training without any change in coding, according to Kharya. Incidentally, the Ampere GPUs will support the Bfloat16 format as well as FP64, FP32, FP16, INT4, and INT8 – the latter two being popular for inference workloads, of course.
Another big architectural change with the Ampere GPU is that the Tensor Cores have been optimized to deal with the sparse matrix math that is common in AI and some HPC workloads and not the dense matrix math that the prior Volta and Turing generations of Tensor Cores employed. This spare tensor ops acceleration is available with Tensor Float 32 (TF32), Bfloat16, FP16, INT4, and INT8 formats, and Kharya says that this feature speeds up sparse matrix math execution by a factor of 2X. We are not sure where all of the 20X speedup cited for single-precision and integer performance comes from, but these are part of it.
Another big change with the Ampere GA100 GPU is that it is really seven different baby GPUs, each with their own memory controllers and caches and such, and these can be ganged up to look like a big winking AI training chip or a collection of smaller inference chips without running into memory and cache bottlenecks like the Volta chips had when trying to do inference work well. This is called the Multi Instance GPU, or MIG, part of the architecture.
The Chip Is Not By Itself The Accelerator
The Ampere GA100 GPU is, of course, part of the Tesla A100 GPU accelerator, which is shown below:

The Tesla A100 GPU accelerator looks like it plugs into the same SXM2 slot as the Volta V100 GPU did, but there are no doubt some changes. The Ampere package comes with six banks of HBM2 memory, presumably with four stacks, with 40 GB of memory capacity. That is 2.5X more memory than the initial Volta V100 accelerator cards that came out three years ago, and 25 percent more HBM2 memory than the 32 GB that the enhanced V100s eventually got. While the memory increase is modest, the memory bandwidth boost is perhaps more important, rising to 1.6 TB/sec across the six HBM2 banks on the Tesla A100 package, up 78 percent from the 900 GB/sec of the Tesla V100. So many workloads in HPC and AI are memory bandwidth constrained, and considering that a CPU is lucky to get more than 100 GB/sec of bandwidth per socket, this Tesla A100 accelerator is a bandwidth beast, indeed.
The 40 GB HBM2 capacity across six banks are both weird numbers, just like the number of MIGs, at 7 per GA100 chip, is also weird. We would have expected eight MIGs and 48 GB of capacity because we believe in multiples of 2, so maybe there is some yield improvement by ignoring some dud portions on the GA100 chip and the other components in the Tesla A100 package. That’s what we would do if we were Nvidia. That also means, if we are right, there are more than 108 SXMs on the chip – 128 is a good base 2 number – and probably eight MIGs, each with 16 SXMs on them. The point is – again if we are right – that means there is another 15 percent or so of compute capacity and another 20 percent of memory capacity possibly inherent in the Tesla A100 device, which can be productized as yields improve at TSMC.
The Tesla A100 accelerator is going to support the new PCI-Express 4.0 peripheral slot, which has twice the bandwidth as the PCI-Express 3.0 interface used in the Tesla V100 variants based on PCI-Express, as well as the NVLink 3.0 interconnect, which runs at 600 GB/sec across what we presume are six NVLink 3.0 ports that come off the Ampere GPU. That’s twice the bandwidth per GPU and into an NVSwitch interconnect ASIC, which Nvidia unveiled back in April 2018, and it looks like there is not an update to NVSwitch since the DGX and HGX servers that Nvidia has designed have only eight Ampere GPUs compared to sixteen GPUs with the Volta generation.
Next up, we will talk about the systems using the new Ampere GPU and what kind of performance and value they will bring to the datacenter.


Nvidia Entangled in Quantum Simulators
Quantum simulators are a strange breed of systems for purposes that might seem a bit nebulous from the outset. These are often HPC clusters with fast interconnects and powerful server processors (although not usually equipped with accelerators) that run a literal simulation of how various quantum circuits function for design …
Hope Springs Eternal For Arm Servers
IT organizations are funny creatures, indeed. On the one paw, they are eternally optimistic about the prospects for new technologies, and on the other paw, they are extremely resistant to change because of the economic and technical risks that change requires. For more than a decade now, the people who …

Oak Ridge Trials Arm-GPU Combo On HPC Testbed
The GPU has become a standard platform for accelerating high performance computing workloads, at least for those that have had their code tweaked to support acceleration at all. Up until recently though, the majority of that acceleration has taken place on host systems using Intel Xeon or IBM Power processors. …
Is there any expectation of Ampere successor to T4 (with similar price and power requirements) being available in 2020?
To my knowledge, A100 is the successor to T4 and V100, as the story was themed around. No more different GPUs for inference and training. But, there will probably be something Turing-like for graphics, and whether or not people use that for inference — with or without Nvidia’s permission — remains to be seen.
There is an entire family of Ampere products expected to rollout in the coming months/years for different work loads and price points. A100 provides the DNA if you will.
According to the NVIDIA website, the full GA100 does indeed have 128 SMs and 12 memory controllers. 20 SMs and 2 memory controllers are disabled. And they are calling the new mezzanine connection SXM-4.
The 20x speedups come as a result of Volta Tensor Cores not having support for INT 8 or FP32. Therefore you have the 8x speedup from Tensor Core acceleration (for FP32 you must use TF32 to get the acceleration), 2x speedup for sparsity, and 1.25x speedup because the A100 GPU has 1.25x more base compute than the V100.
One interesting architectural feature that I haven’t found an explanation for is that on GA100 standard FP16 FMA is 4x the throughput of standard FP32 FMA. Standard BFLOAT16 FMA is 2x the throughput of standard FP32 FMA, as expected. For Tensor Cores, though, BFLOAT16 and FP16 throughput is the same, and is twice TF32 Tensor Core throughput.
The GA100 Tensor Cores apparently also support binary acceleration at 4x the INT4 acceleration, although without any special sparse matrix support.
Finally, a minor correction: In the fifth paragraph it says “The Volta GP100 from three years ago” whereas it should say “GV100”. Also, the abbreviation NVIDIA uses for the streaming multiprocessor is SM, not SXM.
Yeah, none of this data was out as I was writing, and we were told it would not come out until Tuesday.
SXM is a socket type.
Oh, one more thing I forgot to include. The NVLinks are split up differently now, with 12 total NVLink connections now, instead of 6. Each NVlink now had 4 lanes instead of 8. Although each lane is now twice the capacity as before, since there are half as many lanes each NVLink can carry the same bandwidth as before.
I’m interested to hear how this works out for non-training workloads. Obviously they invested a TON of transistors into making this thing a machine learning powerhouse. They had to. While GPUs became a favorite ML platform 4-5 years ago, things have started to shift to ML-specific custom hardware; Nvidia had to recapture that market. But for standard FP64 cuda programs, this is a pretty modest upgrade from volta: 9.7 vs 7.8 Tflops, mostly paid for with an extra 100watts per package. 70% more memory bandwidth sounds pretty good though.
This sounds like a fantastic accelerator for a big government or academic center. Most users will just want fp64 flops, and will love the extra memory bandwidth. A small percentage of codes will do ML training, and will love the improvement over prior generations, and these uses will stay with the lab, rather than leave for a cloud provider with custom ML-asics. I wonder, however, if the chip will be good enough to take down the ML-custom chips?
Its 19.5 FP64 TFLOPS using the FP64 Tensor cores, which I would imagine is the big selling point for HPC. WITH 54 billion transistors and 826mm² of silicon and all the AI specific features they crammed into it, I would imagine it’ll hold up nicely just like Volta has. Plus, you could do it all in one box instead of buying AI and compute specific hardware.
Hopefully the CORAL people didn’t make a mistake selecting Intel CPUs and GPUs for Aurora instead of POWER10 and Nvidia.
Especially given Intel’s rather disappointing track record with their Knight’s series, and the general stagnation of their products since Skylake launched half a decade ago. Constantly rehashing the same basic chips on the same microarchitecture for 5 years doesn’t bode well for them making a leading edge, world class system.
Especially with Cray making a Fujitsu A64FX based supercomputer, POWER10 supporting OMI DIMMs, and Ampere having all the nifty architectural features it has. I guess time will tell.
“One of the clever bits in the Ampere architecture this time around is a new numerical format that is called Tensor Float32”
Intel calls this format FP19 in their Agilex FPGAs, introduced in April,2019.
They describe it in
“Architectural Enhancements in Intel®Agilex™FPGAs” article
dl.acm.org/doi/pdf/10.1145/3373087.3375308