

Hardware accelerated databases are not new things. More than twenty years ago, Netezza was founded and created a hybrid hardware architecture that ran PostgreSQL on a big, wonking NUMA server running Linux and accelerated certain functions with adjunct accelerators that were themselves hybrid CPU-FPGA server blades that also stored the data.
Netezza was interesting, and inasmuch was acquired by IBM for $1.7 billion in 2010 and was basically mothballed a year ago for reasons Big Blue never explained. While Netezza data warehouse appliances were elegant devices, no one would call them mainstream. But the idea of accelerating databases with GPUs, FPGAs, and perhaps even other kinds of compute engines is catching on, and the market is expanding as companies wrestle with larger amounts of data and need to do analytics against their databases with faster and faster response times to run their businesses.
SQream Technologies, which was founded in 2010, is a case in point. We covered the company way back in 2014 when it uncloaked from stealth mode, and then did an update in October 2018 as it was gaining traction, and then followed up in February 2019 as flash arrays helped to boost the performance of its SQream DB analytical database. SQream DB formats data in a columnar fashion and cuts out indexes and then uses additional data chunking, data skipping, data compression, and parallel chunk processing methods to radically compress data – on the order of 20X – and also speeding up transactions by a factor of 60X compared to other parallel database architectures.
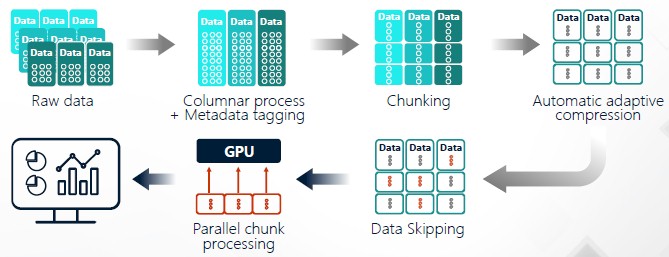
The SQL queries in GPU accelerated databases are split up across tens of thousands of cores in each GPU, and often across multiple GPUs, that can chew through data with SQL queries a lot faster than CPUs can do. There are other examples of GPU database acceleration, including OmniSci (formerly MapD), Kinetica, and Brytlyt, which we have done deep dives on in the past.
That detailed report back in October 2018 was when SQream Technologies had just ported its eponymous database to IBM Power9 servers, which have native NVLink ports on the processors and IBM was looking for something to replace its Netezza line, which had gotten long in the tooth from neglect. The difference between the two platforms is stunning:
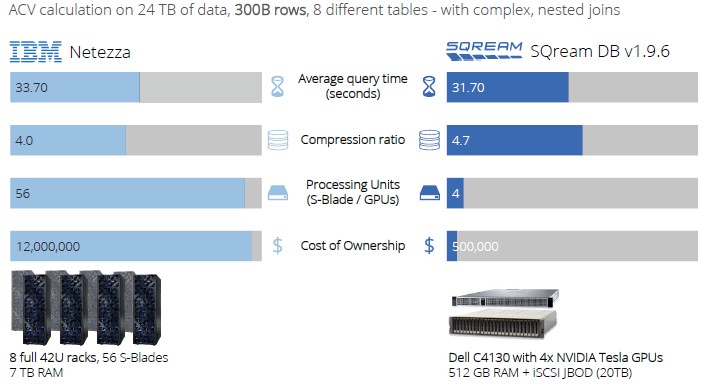
To get the same level of compression and about the same query response on a Netezza appliance and a SQream DB machine, it took 14X as many compute acceleration blades and 24X as much money to build a Netezza appliance – albeit with technology that could have been upgraded some with faster CPUs and FPGAs – as it did a modest two-socket server equipped with two Xeon SP processors and four Nvidia Volta V100 GPU accelerators.
This kind of change in the economics of data analytics is why SQream Technologies is on the rise, and why the company was able to raise $39.4 million in its latest round of funding this week. The company raised $1.9 million in a seed round back in 2011, followed by $9.3 million in Series A funding in 2015, the year after it dropped out of stealth, and raised another $26.4 million in the first portion of its Series B back in 2018, for a total $77 million to date. The funding was led by Mangrove Capital Partners and Schusterman Family Investments; other existing investors also kicking in money, and include Hanaco Venture Capital, Sistema VC, World Trade Center Ventures, Blumberg Capital, Silvertech Ventures, and Alibaba Group.
“Last year was definitely our tipping point for us,” Ami Gal, co-founder and chief executive officer of SQream Technologies, tells The Next Platform. “We are now 83 people, and that is a lot of salaries, and we are looking to add dozens of people to our research center in Tel Aviv and a similar number around the world. And the reason is that we had almost 6X growth last year in terms of the number of customers and in revenue bookings, and we expect to have dramatic growth this year as well. We are growing very fast, and that is one reason we had so much demand for our shares.”
Gal says that the total addressable market has grown like crazy since we first talked to him six years ago, going from dozens of potential customers to hundreds of customers two years ago to many thousands of customers today.
And the size of the databases against which companies want to run analytics keeps growing, too, which also drives more revenues and increases the TAM. And as GPU accelerators have become more common in datacenters, this also expands the addressable market because companies can repurpose machine used for HPC and AI workloads to also run databases and their SQL analytics, which can in turn underpin AI workloads in part.
Back when SQream was founded a decade ago, a big database was on the order of 1 TB to 4 TB. To be sure, large enterprises had plenty of smaller databases – often thousands of them, ranging in size from hundreds of megabytes to hundreds of gigabytes – but those were usually operational, not analytical, databases. By the time SQream had uncloaked in 2014 and GPUs were becoming more common, the typical large database was on the order of 10 TB. Today, says Gal, the typical SQream DB customer has databases that are tens to hundreds of terabytes in size (before all the compression tricks) and the largest SQream DB customer to date has more than 10 PB of raw data that they have moved from other platforms into the GPI accelerated database.
While most customers want to run SQream DB on premises in their own hardware, Gal says that there are customers who want to use data that is generated by applications on the cloud and store it in a SQream DB database that is also resident in the cloud, which avoids costly, slow, and painful data movement and also allows companies to mix with their data with public datasets available on the big public clouds. SQream Technologies already has a few cloud customers who have more than 1 PB up in the sky, and without getting into specifics, Gal says that the company is looking to do a better job taking on the Redshift database at Amazon Web Services and Snowflake – “the darling of Wall Street and Silicon Valley” as Gal put it – out on the public clouds. So expect some announcements there in the coming months.
The other thing to look out for is a diversification of compute acceleration by SQream Technologies, which is not wedded or welded to the GPU but is looking to be ready for future AMD Radeon Instinct and Intel Xe GPU accelerators.
“I can’t get into too much of the details right now, but we are looking into most of the known, public, new GPUs that are going to hit the market,” says Gal. And when we suggested that a massively parallel database could be accelerated by any number of devices, including a SmartNIC card with lots of oomph such as those underway from Pensando and Fungible or even FPGA accelerators from Intel and Xilinx, bringing this truly full circle in the latter examples, back to something that would look a bit like a Netezza appliance. “We are getting ready to use the next generation compute, which is not in the market yet but is coming sooner rather than later.”
Yes, that was purposefully vague. And, akin to the strategy that OmniSci has taken, there is even a chance that SQream Technologies could create a CPU-only variant that used vector engines buried in modern CPUs to accelerate the database and allow for a single platform to be used for larger transactional systems as well as for analytical clusters. SQream DB can scale across up to sixteen GPUs right now in a single image, and it is very likely that it would also run reasonably well on a cluster of CPU servers with a mix of DRAM, persistent memory, and flash. But that is just conjecture on our part.




Be the first to comment