

Among all of the hardware and software that is in a datacenter, the database – whether it is SQL, NoSQL, NewSQL or some other contraption in which to pour data and ask questions about it – is probably the stickiest. Companies can and do change server, storage, or networking hardware, and they change operating systems and even applications, but they are loath to mess with repository of the information that is used to run the company.
This is understandably so, given the risk of inadvertently altering or losing that vital data. Ironically, this is one reason why databases proliferate at enterprises. If companies had it their way, they would have one giant database and they could run transactions that bring in money and pay the bills on the same systems in which they do more complex queries against larger and mixed datasets to try to gain insight into the business and try to run it better. But, for performance reasons, it has not been a good idea to let a bunch of business analysts loose on an operational database going complex SQL queries against live data; these queries stress systems so hard sometimes that they dim the lights. And so data warehouses were invented, offloading this complex query work. Every company – even Google and Facebook – has this split between transaction processing and warehousing.
This split is not going away any time soon, but there is, perhaps, a way emerging that can cushion the blow a little bit. Columnar and in-memory extensions added to traditional relational databases like Oracle 12c, IBM Db2, or Microsoft SQL certainly sped up queries, and SAP even launched itself into the database business proper with its in-memory HANA database. But there is another approach, and one that we expect to see more often in the market, and that is to use GPUs to accelerate databases. GPU accelerated databases have been around for a number of years now, but they are by and large standalone products that are different from standard and familiar SQL products, or they are heavily customized implementations of open source relational databases as happened during the initial data warehouse wave.
Back then, Netezza, Greenplum, Vertica, Aster Data, and a slew of others created data warehousing platforms that could chew through complex queries atop the open source PostgreSQL database, essentially replacing the core PostgreSQL engine with a massively parallel back-end that could significantly speed up complex queries against large datasets. The Redshift datastore at Amazon Web Services is a cloudy version of such a scale out PostgreSQL implementation. In these cases, the work is distributed across dozens to hundreds of servers, housing petabytes of data and speeding up queries to a certain extent, but it was still largely a batch operation that took time given the dataset size and the complexity of the queries.
With GPU databases, the object is often speed, and the goal is to do very complex queries against a subset of the data rather than the entire historical dataset. You want responses in milliseconds to seconds, not hours to days, in this case. Kinetica, formerly known as GPUdb, is the oldest of the GPU-accelerated companies and wrote its GPU accelerated database from scratch, but MapD is the upstart that is carving out its own piece of this new market, and actually got to market ahead of Kinetica. So did Sqream Technologies, which we will be profiling soon. BlazingDB, Blazegraph, and PG-Strom have also fielded products, which will also be taking a gander at in the coming weeks. But another upstart, called Brytlyt, might be able to jump out ahead of the pack with some moves that it made this week.
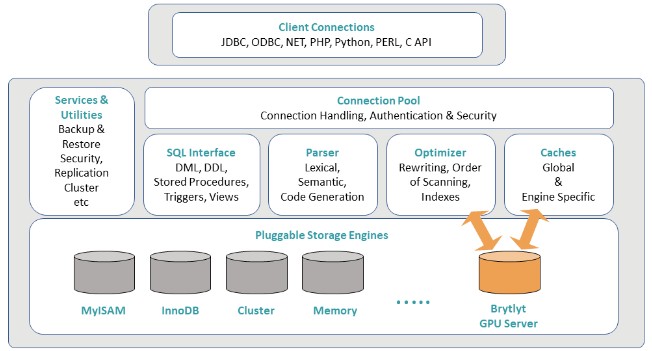
Brytlyt originally created two releases based on the PostgreSQL relational database, allowing for databases to be sharded and spread across GPU memory and processed very quickly thanks to the parallel oomph of the GPUs. But now, Brytlyt has rearchitected the GPU database to be a storage engine that sits underneath MariaDB, the fork of the MySQL database that is controlled by its original creator, Monty Widenius. And Brytlyt is also open sourcing a substantial part of its GPU database engine so it can play nicely with the MySQL community, and perhaps become the way that many relational databases get GPU acceleration.
(Side note: The My in MySQL has nothing to do with you or Widenius, but rather refers to his oldest daughter, My; MariaDB is named after his younger daughter, Maria.)
Brytlyt was founded in July 2013 by Richard Heyns, who is the company’s chief executive officer. The company is based in London and about half of its 20 employees are in a development lab in Warsaw, Poland that is headed up by Jakub Pietrzak, the lead of research and development. That team of programmers have now created two iterations of the PostgreSQL variant of the Brytlyt GPU database and in a matter of months have transformed that code so it can be a database engine plug in for MariaDB.
Aside from £306,000 in seed funding back in August 2016 to commercialize the database, the company has been self-funded. It takes a while for any new technology to take hold in the market, and since shipping the second release of its GPU database last June, which involved a substantial reworking of the PostgreSQL GPU engine to make it more horizontally scalable. Benchmark tests last June were done on a four-node cluster with eight Nvidia Tesla K80 GPU accelerators in each node (that is eight CPUs and 64 GPUs in total across the cluster), and it can scale further if need be. The Brytlyt GPU database had some initial good performance benchmarks last summer showing it could do complex queries against billions of rows of data with millisecond response times. Because of that, Brytlyt has about a dozen initial customers, and inbound queries are growing by 20 percent per month and it has a slew of large telcos, retailers, and financial services firms that are entering proofs of concept. The Brytlyt GPU database was made available on GPU instances on AWS last October and there is a lot of tire kicking here, too. The company inked a partnership with IBM last year and benchmarked the PostgreSQL version of the GPU database on five nodes of IBM’s Power8+ “Minksy” server, with each node having four “Pascal” Tesla P100 GPU accelerators, and the company has gotten its hands on the Power9 “Newell” Power AC922 systems that Big Blue launched in December for HPC and machine learning workloads and is starting to run its tests.
Thanks to the partnership with MariaDB and the opening up of its code, Brytlyt could start riding up bottom edge of the hockey stick adoption curve and quickly move towards the handle. Making Brytlyt an underlying – and invisible – part of the MariaDB database will go a long way towards spurring adoption because companies that certified for MySQL or MariaDB will be able to transparently offload from CPU processing to GPU processing in a seamless way.
Not A Transactional Database – Yet
Just because the Brytlyt GPU database presents itself as a standard PostgreSQL database or runs as a database engine inside MariaDB does not mean it is suitable as a transaction processing engine.
“We are definitely an analytic database,” Heyns tells The Next Platform. “It is just the way that GPUs are, and they are just not suited to transactional workloads. But we are developing an in-memory solution that will work hand-in-hand with the GPU database, and in-memory databases are very good at transactional work. So one could have a hybrid system where data for the transactional services resides in CPU memory and then have real-time analytics in the GPU memory. And the way that Nvidia has designed the memory management in the latest releases of CUDA and on the latest generations of its GPUs, you can synchronize CPU and GPU memory automatically, and anything that happens on CPUs is available for GPUs. So this is how we think future high transactional systems and high speed analytics will end up.”
As we discussed previously, Kinetica’s eponymous GPU database is an in-memory database that has GPU acceleration for a subset of data that resides in GPU memory. We expect for GPU databases to move in both directions over time, and to embed their own visualization engines, as MapD has done, too. Eventually, they will add their own machine learning frameworks, or partner with those who have them, to try to build a modern, complete database and machine learning platform.
The Brytlyt GPU database is written in C and C++ with the CUDA extensions, of course, and it uses Lua to stitch different elements of the software stack together. The database has been ported to run on X86, Power, and Arm architectures, but X86 and Power are the two main commercial efforts right now and Tesla GPU accelerators with NVLink interconnects between the GPUs is a big plus for performance, according to Heyns. Given that IBM has NVLink ports on its Power9 chips and coherency across the CPU and GPU memory – something that X86 server platforms cannot offer – the Power servers from IBM could have a leg up on X86 iron when running GPU databases.
“We don’t compile at runtime, which gives a bit of a performance boost, but rather we use the Thrust library in CUDA that abstracts away a lot of the dark and dirty kernel writing that you have to do in CUDA. This means that we can develop very quickly, and you have a bit of a sacrifice in performance.”
The relationship with MariaDB was announced at the M|18 conference in New York, and it will eventually see Brytlyt’s open source code being embedded in MariaDB, either at the 10.5 or 10.6 release. Back in June when we had a chat with Heyns, he was dubious about open sourcing the Brytlyt code, but after Widenius talked to him about the possibilities and talked up the open core model of software, Heyns saw the light and will be giving away a freebie version of the source code that allows for the database to run on a single GPU. Exactly when this code will be dropped into GitHub is unclear, because there is some cleanup and code separation that has to be done.
That is because Brytlyt is keeping some of the goodies, like its patent pending routines for doing sophisticated JOIN operations in SQL on the GPUs as well as some indexing and scale out functions, to be part of an enterprise edition that will come with license fees for support. It is not clear what Brytlyt will charge for the enterprise edition of the engine for MariaDB, but with the PostgreSQL version, which will still be supported and enhanced, the company was charging $1,000 per gigabyte of GPU memory per year, and allowing customers to convert that to a monthly charge if they wanted a finer-grained subscription.
In early benchmark tests done ahead of the M|18 conference, the demo was a simple query running the MyISAM engine (the default engine from way back in the day with MySQL until InnoDB became the preferred one) underneath MariaDB, and that query took 7 minutes on a server with just CPU oomph. With the Brytlyt engine underneath MariaDB, that same simple query took 100 milliseconds, which works out to a factor of 8,000X speedup.
The next logical question is what other plain vanilla SQL databases could be accelerated by a GPU engine like the one that Brytlyt has created. The Elastic Data Warehouse from Snowflake Computing, a parallel database with a homegrown heart that was created by database experts from IBM, Oracle, and Actian, is oddly enough a candidate according to Heyns. (Presumably using the engine approach that was used to slip into MariaDB.) Other MySQL variants are an option, too, obviously. And so are the Aurora and Redshift database services at AWS, which are compatible with MySQL and PostgreSQL. (Doing both at the same time, as Aurora does, is a neat trick; Redshift just speaks PostgreSQL.) Other PostgreSQL variants, such as EnterpriseDB, are obvious candidates, too. The thing about opening up the code is that Brytlyt can become an engine supplier, and sell its wares to any database maker. Including IBM with Db2 or Microsoft with SQL Server – and even Oracle with 12c and MySQL proper.
The smart thing for Brytlyt to do is to sell bullets to everyone in the database fight. Whether or not this is technically or economically feasible remains to be seen. And its competitors might see the wisdom of this approach too – MapD is already open source – and plug in GPU acceleration engines could proliferate. When this is all done, GPU acceleration could sweep through databases a whole lot faster than it did through HPC stacks. As for GPU acceleration for machine learning, there is no machine learning without the advent of GPUs, so there is no comparison.

Teaching Kubernetes To Do Fractions And Multiplication On GPUs
When any new abstraction layer comes to compute, it can only think in integers at first, and then it learns to do fractions and finally, if we are lucky – and we are not always lucky – that abstraction layer learns to do multiplication and scale out across multiple nodes …
When Push Comes To Shove, Google Invests Heavily In GPU Compute
A year ago, at its Google I/O 2022 event, Google revealed to the world that it had eight pods of TPUv4 accelerators, with a combined 32,768 of its fourth generation, homegrown matrix math accelerators, running in a machine learning hub located in its Mayes County, Oklahoma datacenter. It had another …
The HBM3 Roadmap Is Just Getting Started
To a certain extent, the only thing that really matters in a computing system is what changes in its memory, and to that extent, this is what makes computers like us. All of the computing capacity in the world, or the type of manipulation or transformation of that data, doesn’t …
Tim, you forgot about Spark / Databricks, why would not their engineers write a GPU dedicated engine to speed up SQL tasks?