
For the past decade, flash has been used as a kind of storage accelerator, sprinkled into systems here and crammed into bigger chunks there, often with hierarchical tiering software to make it all work as a go-between that sits between slower storage (or sometimes no other tier of storage) and either CPU DRAM or GPU HBM or GDDR memory.
With chunks of HBM2 memory stacked up right next to the “Pascal” and “Volta” Tesla GPU accelerators and plenty of DRAM memory in the Xeon processors, you might not think that an all-flash array based on NVM-Express interconnects would do much to accelerate the performance of GPU accelerated databases, but as it turns out, in many cases it does help, particularly when datasets bust out beyond that GPU memory and transactions have a lot of I/O contention.
That is the conclusion that DataDirect Networks, which is well known in the media and content distribution business as well as in HPC centers for having very fast storage, came to after running some tests on the SQream DB GPU database from SQream Technologies. What applied to SQream DB probably applies in varying degrees to GPU accelerated databases from Kinetica, OmniSci (formerly known as MapD), and Brytlyt, which we have profiled behind those links. DDN has a partnership with Nvidia and its DGX-1 and DGX-2 resellers to pair up its AI200 NVM-Express flash arrays with those GPU accelerated machines, and also a partnership with SQream to sell its databases atop that iron to try to expand out into this nascent market, and its techies got together with their peers from SQream to run some benchmark tests on data warehousing workloads to try to gauge the effect of putting fast flash as an offload tier for the GPU main memory to try to run larger workloads on the SQream DB GPU database.

In most cases, given the nature of the AI workloads that are often running alongside of GPU databases and the relatively limited internal storage capacity of the DGX machines from Nvidia, it stands to reason that companies buying these systems – or clones of them from Nvidia’s system partners or alternatives such as the Power AC922 servers from IBM that are part of the “Summit” and “Sierra” supercomputers built for the US Department of Energy – are going to need adjunct storage, and they are going to probably splurge on all flash arrays. You don’t put tricycle tires in a Tesla, after all. Pure Storage has a bundle of its FlashBlade all flash arrays and Nvidia DGX systems, called AI Ready Infrastructure, or AIRI for short, that it debuted this time last year. DDN has been pairing up its AI200 series arrays, which have a single socket “Skylake” Xeon SP processor driving a bunch of NVM-Express flash drives, with Nvidia DGX-1 systems and Hewlett Packard Enterprise Apollo 6500 systems – both stuffed with Volta Tesla GPU accelerators – to create its similar A3I hardware stacks.

Those AI200 series NVM-Express arrays used in the A3I rack stacks are not based on the “Wolfcreek” two-socket Xeon storage servers developed by DDN, which have a fatter form factor and which are used in its high end SFA 14K and SFA 18K arrays, often used in supercomputing parallel file systems, but on a smaller system (code-name unknown) based on that single-socket motherboard with four 100 Gb/sec Ethernet or InfiniBand ports and room for two-dozen 2.5-inch NVM-Express flash drives. Coming soon in the first quarter, Kurt Kuckein, senior director of marketing at DDN, tells The Next Platform, DDN will add a two-socket Skylake Xeon SP motherboard to the system to create the AI400 array, which will have twice the read and write performance and three times the I/O operations per second coming out of the flash and through the appliance due to that extra compute and the I/O it has built in. (The AI7990 is not based on the Wolfcreek chassis either, by the way, but it does support lots and lots of disk and flash drives, as the Wolfcreek does, and it will not match the AI400 in performance. Which is what machine learning system architects care about most.)
DDN and SQream want to prove that high performance flash storage can boost the performance of GPU databases doing analytics workloads, but they also don’t want to give the wrong impression that all queries will be accelerated. To that end, the two companies grabbed the TPC-H data warehousing benchmark and ran a bunch of the underlying queries in that suite of tests against a 10,000 GB database size to see what the effect of the external AI200 flash array would be on performance compared to using the internal flash storage on the DGX-1 system that housed eight of the Volta GPU cards (presumably with 16 GB each, for a total of 128 GB of raw memory capacity to store the database. Obviously, that sized TPC-H database won’t fit in the HBM2 memory of the Volta GPU accelerators, so it has to be offloaded to something, and in this case it gets offloaded to flash devices.
Here are the performance results on four of the underlying TPC-H queries:
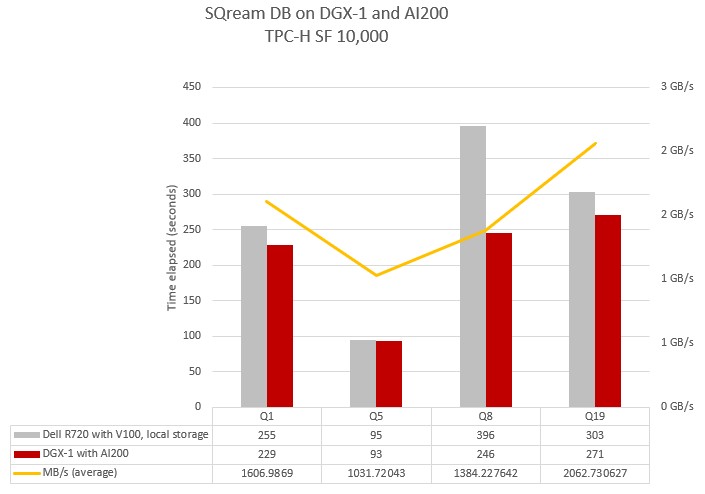
As you can see, the performance improvements can be modest when shifting to external NVM-Express arrays, as is the case on the two queries on the left of the chart, or more dramatic, as was the case with the two queries on the right of the chart.
Query 1 in the TPC-H test (Q1 in the chart) is a pricing summary request against the data warehouse, which shows the amount of business that was billed, shipped, and returned for the hypothetical business; Query 5 (Q5 in the chart) is a local supplier volume query. Kuckein says that both of these queries do not drive a lot of heavy I/O and therefore the difference between the internal storage on the DGX-1 cluster and the DGX-1 pairs with the AI200 array is not huge. Query 5 is almost the same performance either way. But with Query 8, which is the national market share query, and Query 19, which is a discounted revenue query, these are more I/O bound and the differences start to show up. “Query 19 tends to more be a lot more random in nature, so you don’t get the huge throughput advantage as you see in Query 8, but in both cases you get fairly good acceleration,” explains Kuckein.
What would be really funny to see is how a two-socket Skylake Xeon SP performed using SQL Server or Oracle without the GPU acceleration. But that is another story. . . .
Here is the point. A base AI200 loaded up with 24 NVM-Express drives with 38 TB of raw capacity costs around $60,000, and will definitely provide performance advantages for AI training workloads and HPC workloads in addition to some uptick for GPU accelerated databases like SQream DB. That is against the cost of a DGX-1, which weighs in at $119,000 list price today (it was $169,000 at launch two years ago, but Nvidia recently cut the price), and a DGX-2, which costs $399,000 at list price. Instead of putting in fat flash local storage, an NVM-Express array is probably the way to go.
At the moment, there are eight partners that are certified to sell both DGX gear from Nvidia and A3I storage from DDN. In the United States, they are E+, Groupware, Meadowgate, Microway, and World Wide Technology; outside of the United States, the partners are PNY, GDEP, and E4.
One last thing. On March 7 at 9 AM Pacific time, DDN and SQream Technologies will be hosting a webinar with the technical architects of these systems to talk about boosting GPU database performance with flash arrays. You can register at this link if you want to attend.

Accelerated Databases In The Fast Lane
Hardware accelerated databases are not new things. More than twenty years ago, Netezza was founded and created a hybrid hardware architecture that ran PostgreSQL on a big, wonking NUMA server running Linux and accelerated certain functions with adjunct accelerators that were themselves hybrid CPU-FPGA server blades that also stored the …

Boosting AI Storage With QLC Flash And Deduplication
A few years ago, DirectData Networks gave us a hint at the tectonic-like shifts that were emerging in datacenters at enterprises and high-end research institutions and were shaping the strategy of a company that had made its name in HPC with its parallel file system technology. New performance and storage …

DDN Uses Acquisitions to Grow In The Enterprise
For more than two decades, DirectData Networks has focused on HPC storage, supplying large systems to enterprises and research institutions wrestling with complex and data-laden workloads and taking on such challenges as acquiring the Lustre File System from Intel in 2018. At the ISC 19 supercomputing show in June, DDN …
Be the first to comment