

Many programs have a tough time spanning across high levels of concurrency, but if they are cleverly coded, databases can make great use of massively parallel compute based in hardware to radically speed up the time it takes to run complex queries against large datasets. Given this, it is a wonder that databases were not ported to GPUs long before the parallel portions of either HPC simulation and modeling or machine learning training were lifted off CPUs and coerced to run on glorified graphics cards.
Databases are making their way to GPUs just the same, just as many commercial relational databases have adopted columnar data formats and in-memory processing. But GPU accelerated databases are a little different in that the incumbent relational database suppliers – Oracle with its eponymous database, Microsoft with SQL Server, and IBM with Db2 (why the little d all of a sudden, Big Blue?) and the upstart in-memory database players like SAP with HANA – have not as yet figured out how to port their databases to these massively parallel computing engines with their high bandwidth memory and screaming performance. Perhaps they do not want to embrace the GPU as an accelerator since it will upset their whole pricing model on CPU-only systems.
No matter. There are a slew of upstarts who have put GPU databases into the field, and they are making headway against both those who peddled data warehouse systems and those who sell real-time databases, shooting the gap between the two and allowing companies to search larger datasets with faster query responses than they are used to.
SQream Technologies is one of those upstarts, and it has been gradually building momentum for its SQream DB database, which uses GPUs to reduce the query time by many orders of magnitude for databases that can measure hundreds of terabytes in size and hundreds of billions of rows of structured data.
What constitutes a large database, of course, is subject to interpretation and plenty of people have the mistaken impression that to be considered large, a database has to be tens or hundreds of petabytes in size. But in the real world, production relational databases range in size from hundreds of megabytes to tens of terabytes, on average and in the enterprise there is usually a shift from production online transaction processing systems to adjacent data warehousing systems once you start breaking above tens of terabytes. Enterprises do not have large databases so much as they have many of them, and when they try to create a single repository of truth – a data warehouse like Teradata pioneered decades ago or a data lake like all of the commercial Hadoop distributors have been selling for the past few years – it takes a lot of iron to run transactions against it and a lot of effort to extract that data from production databases and consolidate it into some form that complex queries that drive business insight can be run against.
As transactional data is mixed with other types of information that companies are hoarding these days, the size of data warehouses has been on the rise, too, Arnon Shimoni, a developer who helped create SQream DB when SQream Technologies was founded back in 2010 and who is now product marketing manager at the company, tells The Next Platform. Before SQream was founded, a big dataset was on the order of 1 TB to 4 TB in a large enterprise, but around the time the company started work on SQream DB (formerly known as the Analytics Engine) that had growth to around 10 TB. These days, we are operating in the realm if tens to hundreds of terabytes with many terabytes added per day to large datasets, and much as HPC and machine learning needed the parallel processing inherent in the GPU to solve their number crunching and memory bandwidth problems, so does the relational database.
GPU acceleration has come in to save the day, and now NVLink ports between CPUs and GPUs, which thus far are only available on IBM’s Power8+ and Power9 systems, are pushing performance even further.
“When we started back in 2010, GPUs inside of servers was quite uncommon,” says Shimoni. “There were not very many vendors offering GPUs at all for their servers and you had to retrofit them to see if it would work. Today, this is less of a big question.”
By definition, SQream DB is designed to run on high throughput devices, typically an Nvidia Tesla GPU which is coupled to whatever CPU customers can to pair it with, typically a multicore Intel Xeon. “But such a system has a disadvantage in that the GPUs are connected over the PCI-Express bus, which limits the I/O that you can get to these GPU cards a little bit,” Shimoni explains. “If we are talking about 12 GB to 16 GB or even 32 GB with the latest GPUs, that is not a problem – you copy all of your data over to the GPU, do your processing, and you don’t really need anything else. But for SQream DB, we are typically talking about much larger datasets – not only are they larger than GPU memory, they are larger than CPU main memory. So we rely quite heavily on all of the server buses having quite high throughput.”
This is why SQream, which has just come out with v3.0 of its GPU database last month, is so excited about the port of its database from Xeon processors to IBM’s Power9 processors. The six NVLink 2.0 ports on the Power9 processor linking out to a pair of “Volta” Tesla V100 accelerators can deliver 300 GB/sec of aggregate bi-directional bandwidth between the CPU and the pair of GPUs, which Shimoni says is nearly 9.5X the bi-directional bandwidth of a pair of PCI-Express 3.0 x16 slots linking out to two GPU cards from a “Skylake” Xeon SP processor. A system with two Power9 chips and four Tesla V100s can have very fast interconnects between the processing and memory across both the CPU and the GPU, like this:
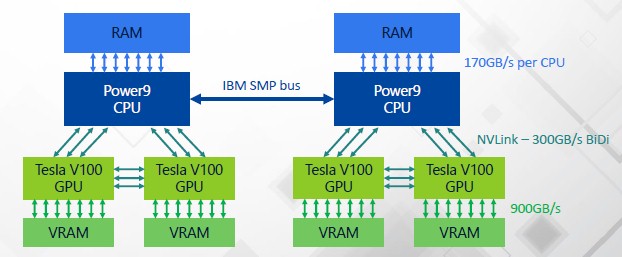
In this configuration, there is almost as much bandwidth between the Power9 chip and each GPU as there is between the Power9 and its main memory – 150 GB/sec versus 170 GB/sec – and of course the bandwidth between the GPU and its local HBM2 memory is much higher at 900 GB/sec.
“This is important because in the past, we would have to do all of these tricks with the I/O on the Xeons, and they are great and they work fantastically, but with Power8 with NVLink 1.0 and Power9 with faster NVLink 2.0, we do not need to do so many tricks to get high throughput up to the CPU,’ explains Shimoni. “As for the Volta GPU, it can deliver 900 GB/sec of bandwidth and there are not many devices that can do that.”
(We note that the “Aurora” vector engines from NEC can hit 1.2 TB/sec, but that’s about it from the competition at this point.)
By the way, there is nothing, in theory, that prevents SQream DB from running on any other kind of parallel or streaming processor, and it could run on those Aurora vector engines provided the data formats matched the math units. But what really has made SQream DB possible is Nvidia’s CUDA programming environment.
“The CUDA platform that Nvidia has built around its Tesla GPUs, with frameworks like Thrust, Cub, and Modern GPU, cuBLAS, that have made it a lot more straightforward to program for GPUs. That said, the system we have created is flexible enough that we could move it to another architecture without making huge, sweeping changes to it. Practically, we are using everything that the GPUs have to offer, and we rely very heavily on Nvidia’s CUDA framework. Nvidia made it very easy to write very high performance code. We almost did not have to write any of our own sorting techniques because very smart people at Nvidia had already done the work for us. Where we did have to write our own code was with data compression and hashing, where we found our own is better.”
The port to IBM’s Power architecture was a long time coming, and was delayed not because of CUDA issues or the availability of Power iron, but rather because a substantial portion of the SQream DB database was coded in Haskell. The first prototype built back in 2010 was pure Haskell with OpenCL kernels for the parsers, just to show it would work, and the latest version of the database is about a third Haskell with the remain lines of code being done in C++ and CUDA. When SQream tried to do the port to Power8+ back in 2015, the Haskell toolchain would not compile on Power, and it took IBM, SQream, and the Haskell community a few years to work through all of the issues. Now, SQream can compile the GPU database down to X86 or Power from the same code base and it can use NVLink on Power9 to drive sales.
Tearing The Covers Off SQream DB
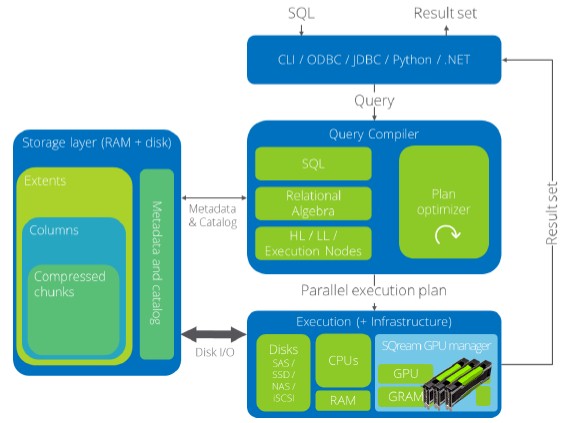
Before getting into the relative performance of the Xeon SP and Power9 variants of SQream DB running in conjunction with Volta Tesla accelerators, it makes sense to talk a little about how SQream DB works.
The great thing about databases is that they are inherently parallel. If you break a dataset into any number of pieces and throw compute at each piece, SQL statements can run against each piece to extract data with specific relationships and then this information can be joined together to give a cumulative answer. The smaller you break the dataset and the more compute you throw at it, the faster the speedup – although this is not free parallelization because of data movement and SQL overhead – relative to doing it on a compute engine with brawnier cores and probably proportionately more cache and main memory behind it.
Some of the same techniques that have been employed on multicore and multithreaded processors to speed up databases are also used with SQream DB.
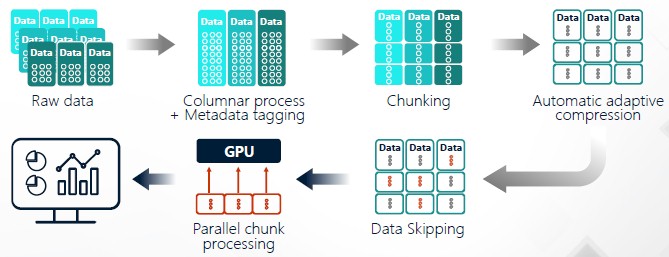
Raw data stored in many different tables with various relationships across those tables are transformed into columnar formats where the relationships – customers, geography, sales, whatever – are explicitly outlined in each column. Columnar data allows for subsets of the data to be pulled into main memory for processing in one fell swoop instead of scanning through a row-based database one row at a time or by zipping down an index to pull out the relevant pieces. Compression ratios tend to be higher in columnar database formats, too, because like information is stored next to like information. Because columnar databases are fast and in this case is running on chunks of data spread out through the GPU memory and affiliated with thousands of GPU cores, there is no need to do indexing or views as is the case when trying to boost the performance of row-based relational databases.
The database doesn’t just reside in GPU memory, but can be spread across flash and disk storage in the system, which is called chunking, and this chunking is done on many different dimensions of the data to speed up processing from many different angles. Chunking is done automagically as data is ingested, and by the way, the first version of SQream DB could ingest at 2 TB/sec on a single GPU and now with v3.0 it can do about 3 TB/sec. This makes Hadoop look like a sloth. In addition to chunking, the database includes what SQream calls smart metadata, which allows for segments of the column store to be segmented off if it is not necessary for the query to run – a technique called data skipping. Add compression to the mix, and these approaches can compress a relational database that weighs in at 100 TB down to about 20 TB plus a few gigabytes of metadata on top of that and also save 80 percent in the I/O hit to manipulate data.
With so many engines chewing on smaller chunks of data, companies can see many orders of magnitude speedup over traditional data warehouses based on massively parallel relational databases such as those sold by Teradata, IBM (Netezza), and Dell Pivotal (Greenplum).
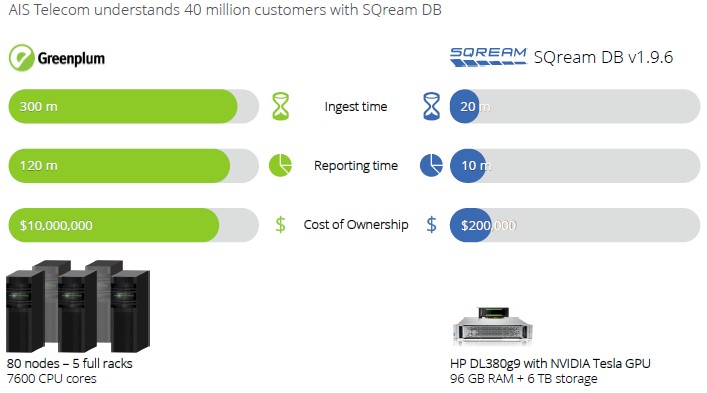
Here is how SQream stacks itself up against a Greenplum data warehouse:
And here is how it reckons it compares to an IBM Netezza data warehouse (yes, this is also a PostgreSQL database that has been parallelized but also accelerated by FPGAs):
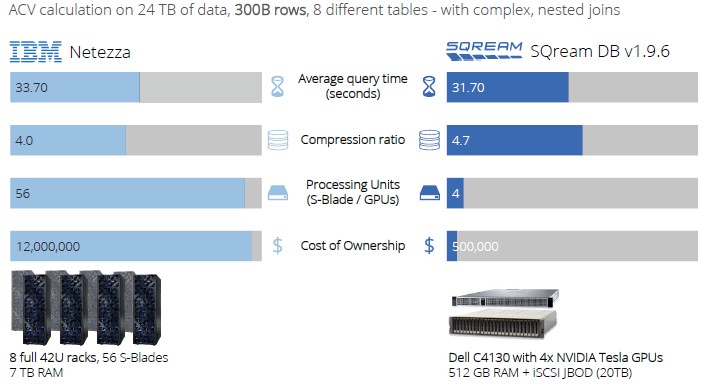
These are interesting comparisons, but they are also a bit dated. We don’t think of Netezza or Greenplum being modern data warehouses, and we think that it is far more likely that companies today will dump all of their information in a data lake based on Hadoop or some other cheap (or fast) storage and try to do some accelerated or in-memory database to chew on pools of data drawn from that lake to do interactive (rather than batch) ad hoc queries to drive the business. The comparisons are good for showing architectural differences and price/performance differences, for sure. The pricing approach is a lot different, too, with SQream charging $10,000 per TB of raw data per year for a database license. In general, compared across all of these different approaches, Shimoni says that customers deploying SQream see an average of a 20X increase in the size of their data warehouses when they move to its GPU accelerated database, queries run on average 60X faster, and the resulting system costs about one-tenth as much.
Of course, it takes more than a database and aggressive pricing to make enterprises buy a database management system, of course. It takes an ecosystem, and that is why SQream made sure its database was compliant with the ANSI-92 SQL standards. This is not the latest standard, but it is also not too old so as to be irrelevant.
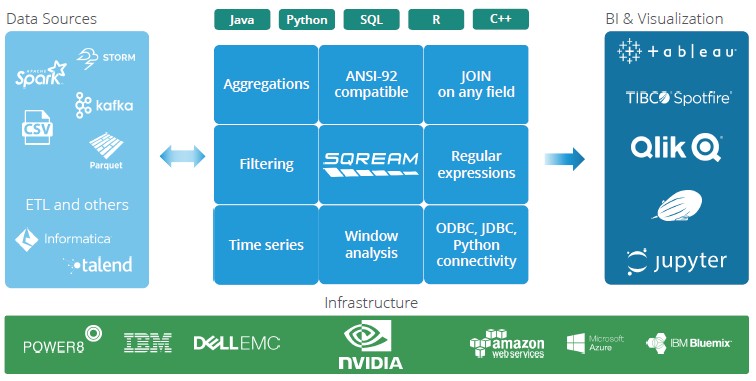
Because of this ANSI-92 compliance, a whole ecosystem of data sources can feed into SQream DB and a slew of well-established business intelligence and visualization tools can make use of its output after the queries are done.
There are a lot of different ways to store and query relatively large datasets, which range from 10 TB up through 1 PB or more. The comparison and contrast of these approaches, as Shimoni sees it, are outlined in the table below:

We are certain that suppliers of all of these alternatives would pick a fight about aspects of this chart, but it at least lays out the vectors of the competition pretty cleanly and gets the conversation moving and the blood flowing. Kinetica and MapD – now called OmniSci after a rebranding exercise this week – will probably have much to say.
This brings us all the way back around to SQream DB being certified to run on Power9 processors running the Linux operating system – Red Hat Enterprise Linux 7.5 and its CentOS clone as well as Canonical Ubuntu Server 18.04 LTS, to be precise. (SUSE Linux Enterprise Server seems to have fallen out of favor on Power recently, and we are not sure why.)
For any data warehouse to be useful, first you have to ingest the data and get it all reformatted for the database, and then you have to run some queries against it. Shimoni showed off some benchmark results for both types of workloads running on both “Skylake” Xeon SP systems and equivalent “Nimbus” Power systems.
Let’s do the ingest workload first. SQream configured up a two-socket machine using Intel’s Xeon SP-4112 Silver processors, which have four cores each running at 2.6 GHz, equipped with 256 GB of 2.67 GHz DDR4 memory, and unspecified amount of flash storage, and four of the PCI-Express versions of the Volta Tesla V100 GPU accelerators. This machine was capable of loading at a rate of 3.5 million records per second. We think this was a pretty lightweight setup on the X86 side of the system, and would have configured it with Xeon SP-6130 Gold or Xeon SP-8153 Platinum parts, which have sixteen cores running at 2.1 GHz and 2 GHz, respectively, considering that the Power AC922 was tricked out with a pair of 16 core Power9 chips spinning at 1.8 GHz. The Power AC922 had the same memory and flash, and had four of the Tesla V100 accelerators, but they were linked directly to the CPUs as shown in the diagram way at the beginning of this story, with three NVLink 2.0 ports with 150 GB/sec of aggregate bandwidth lashing each GPU to one of the Power9 chips. This Power AC922 system could ingest data at a rate of 5.3 million records per second. The chart below shows how long it would take each system to load 6 billion records for the TPC-H ad hoc query benchmark for data warehouses:

“The interesting thing here is that without making any changes to our code and by just compiling down to Power9, we could get nearly a 2X decrease in loading time,” says Shimoni. “Loading the database, for us, is still dependent in part on the CPUs because the GPU cannot do the I/O by itself; it needs something to read data off the disks and do the parsing of the files and data formats. Without changing anything and with almost the same configuration, we were able to push nearly twice as much data through the system.”
So how does SQream DB running on Power9 with NVLink do on actual queries compared to Xeon systems with PCI-Express links out to the GPUs? About the same, not surprisingly, since a lot of GPU databases are more I/O bound than compute bound. In the chart below, SQream ran the TPC-H benchmark suite at tge 10 TB dataset scale:
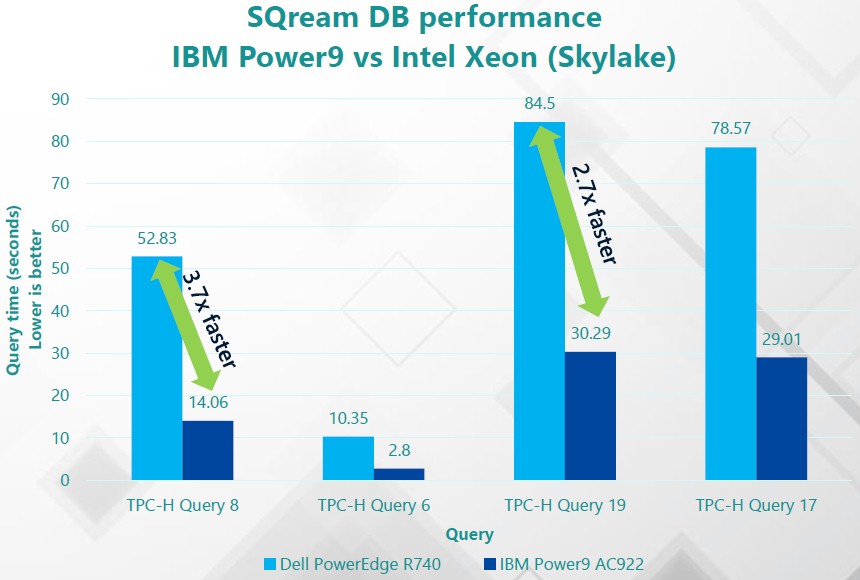
On the four queries shown above, the speedup in the TPC-H queries was between 2.7X and 3.7X faster on the Power9 machine with NVLink versus the Xeon SP machine without it. The gap is larger for any queries that are more I/O bound as data moves from the CPUs to the GPUs. (TPC-H queries 6 and 8 are good examples.) The average speedup across a wider variety of data warehousing benchmarks was a 2X improvement in query times.
With the advent of the NVSwitch interconnect and the DGX-2 system and its HGX-2 clones outside of Nvidia, one wonders about how this might be used to boost the performance of GPU accelerated databases as it obviously helps speed up machine learning training workloads and, quite possibly, even HPC applications. But Shimoni is not so sure it will help unless the six NVSwitch ports are extended back to the Power9 processors in the server.
“I have not seen that yet, but right now, IBM Power9 is the only system that can give us CPU-GPU NVLink, which is what makes this exciting,” Shimoni says. “We do not do a lot of inter-GPU communications, and we don’t find ourselves very often compute bound on the GPU at this stage, even if we did on the older GPU cards. With the modern GPUs, it is hard to saturate them one at a time with a process, so having more of them in the same box does not necessarily bring a lot of speed benefits.”
Adding GPUs to the server node running SQream DB is really about allowing more queries to be run by more users or more intense queries to be run by a smaller number of users, and the data is partitioned in such a way that the GPUs don’t need high bandwidth, low latency links between them like is increasingly important with machine learning frameworks for training. You might be able to run 50 different modest ad hoc queries simultaneously on a machine with four or eight Tesla GPU accelerators, he says.
If a workload scales beyond this, SQream has a Cluster Manager that allows for multiple nodes to be linked to each other to scale out performance and the machines can be equipped with local disk and flash too scale up database storage. Scaling up main memory on the CPU can help, and so can using fatter or faster GPU memories. Cluster Manager has a load balancer that makes sure transactions are ACID compliant and that spreads work across multiple server nodes – meaning it dispatches the SQL processing to a particular node. It has a very large potential footprint in theory — 264 server nodes, to be precise – but in practice the largest Sqream customer has ten nodes with four GPUs in each node.
“The configurations can be surprising,” says Shimoni. “The Cancer Research Institute in Israel is using Sqream DB for genomics data, and it has a 1 PB storage cluster that gets chewed on by a single CPU and a pair of GPUs and the performance is fine. But for other customers, we might have six or eight servers with four or eight GPUs inside of each one. It is very workload dependent. We size a system to one or two or three use cases, but the appetite to do more causes customers to scale up their GPU databases a lot faster than they initially think.”
This is a good thing for Sqream and for its customers, and this is exactly what typically happens with a new and useful technology, such as Hadoop a few years back when it was the hot new thing. Large enterprises started out with a few dozen nodes with one use case, then pooled data as they added new use cases and before they knew it, they had hundreds and sometimes thousands of nodes with petabytes of data. The same thing could happen with GPU accelerated data warehouses – and it very likely will.
One last thought about configuring a hybrid CPU-GPU server for running GPU accelerated databases. It seems to us that there might be a way to jack up all of the bandwidths on a Power9 system and get things humming even faster.
IBM’s four-socket “Zeppelin” Power E950, launched in August, uses the “Cumulus” twelve-core processors, which have SMT8 threading on each core. The system uses buffered memory, based on IBM’s “Centaur” buffer and L4 cache chip, which is a bit more expensive, but it allows for 32 memory sticks to hang off of each socket, twice that of the Nimbus Power9 chip and also 245 GB/sec of bandwidth per socket with memory running at a mere 1.6 GHz, still 44 percent more than what is available in the Power AC922, which has half as many memory slots running at 2.4 GHz. If each Power9 chip in a Power E950 had its own dedicated Tesla V100 GPU, you could have 245 GB/sec coming into and out of main memory, and with six NVLink ports activated on the Cumulus chip you could have 300 GB/sec linking the GPUs to the CPUs and then another 900 GB/sec linking the GPU to its HBM2 memory. Even using relatively cheap 32 GB CDIMM memory sticks, this system would have 4 TB of main memory, which is a lot.
Given the coherency available with NVLink on the Power9 chips across CPU and GPU memory and the fast NUMA links between the four Power9 processors in the Zeppelin system, this could be very interesting GPU database engine indeed. (The CPUs end up being a memory and I/O coprocessor for the GPUs, in essence.) And if the memory were water-cooled it might be able to be clocked back up to 2.4 GHz, memory bandwidth per socket could hit 368 GB/sec. (Dialing it to 2 GHz would give you 306 GB/sec.) Backed by some heavy flash, it would be a true bandwidth beast, and it might push the performance of the GPU databases like SQream even harder.

AMD Teases Details On Future MI300 Hybrid Compute Engines
We were under the distinct impression that AMD was not going to talk much about its datacenter compute engines at the Consumer Electronics Show, having just launched its “Genoa” Epyc 9004 server CPUs in November with much fanfare. But it is the week before Intel is set debut – at …
Nvidia To Build DGX Complexes In Clouds To Better Capitalize On Generative AI
GPU computing platform maker Nvidia announced its financial results for its fiscal fourth quarter ended in January, which showed the same digestion of already acquired capacity by the hyperscalers and cloud builders and the same hesitation to spend by enterprises that other compute engine makers for datacenter computing are also …

GPU Engines Are So Strategic China Will Have To Use Its Own
China is the world’s second largest economy, it has the world’s largest population, and it is only a matter of time before has a world-class technology ecosystem spanning the smallest transistors to the largest hyperscale and HPC systems. It simply has enough money, and enough time, and enough smart people, …
Be the first to comment