

As server chips have evolved from simple processors into complex, heterogeneous SoCs, it has become a lot more challenging to optimize the software running on them. When these SoCs are deployed in web-scale clouds and datacenter-sized supercomputers, these challenges are magnified. UltraSoC, a Cambridge UK-based startup, has come up with a novel way to help users figure out what’s going in the dark recesses of the servers in such environments, namely put the monitoring tools directly on the silicon.
To do this, UltraSoC offers logic modules for things like performance monitoring, debugging, and security services that can be embedded onto SoCs. These IP blocks can be licensed by chip vendors and etched into their SoCs alongside the processors, memory controllers, accelerators, network interfaces, and so on. The logic then becomes available to collect all the relevant runtime information as data zips around the chip.
The technology applies to virtually any computing environment: on-board automotive systems, mobile phones, telecom base stations, storage controllers, and, of course, servers. Here we’re mostly interested in the UltraSoC tools that look at performance behavior, given its central importance to the hyperscale and HPC crowd.
Because of the vast scale of what the Googles and Facebooks of the world do, even a single percent of performance means that they can purchase one percent fewer servers. That might not seem like much, but if total public cloud infrastructure spending is $65.2 billion, as IDC projected would be the case for 2018, then that one percent would have saved the industry $652 million last year alone, not counting the operational expense of running that equipment. Other performance problems can impact latency, and thus the interactive experience of web users, which can translate into lost advertising revenue
According to UltraSoC chief executive officer Rupert Baines, the extent of silicon development within some of these hyperscale and public cloud businesses is impressive. As most readers of this publication already know, that’s especially true with regard to custom chips first for machine learning and now for general purpose compute, but that’s not the only area where these companies are trying to squeeze performance out of their silicon.
Coming from the embedded computing space, Baines hadn’t really appreciated the business drivers for these companies around performance until more recently. “The effort and investment that people put in ongoing software optimization, tuning, and performance is really astonishing,” Baines tells The Next Platform. “And I think that’s an area that we will get a lot of success in.”
For supercomputers, squeezing out one percent performance better performance perhaps doesn’t have quite the same economic incentive as it does for the web giants. But once you get up into the 5 percent to 10 percent range, better job turnaround time and greater capacity becomes noticeable to both the purveyors of HPC machinery and their clients.
UltraSoC’s makes its money by charging chipmakers a standard license fee for the logic modules they want to incorporate, plus a royalty fee per unit. The company also licenses their own analytics software to end user customers.
According to Baines, the value proposition for the technology is based on the fact that their performance monitoring is done in hardware rather than software. As a result, it has visibility to essentially everything that goes on inside the server. It can peak into cache and translation lookaside buffers as easily at it can track network and bus traffic. Traditional software-based performance profilers and debuggers typically don’t look at these low-level components, or when they do, often the act of prodding them changes the runtime behavior of the application. This can lead to the well-known Heisenbug phenomenon, where an attempt to examine a particular bug makes it disappear.
In this case, developers are more interested in “performance bugs,” although the term itself is something of a misnomer. What most performance-minded users are really looking to uncover here are pieces of code or algorithms that are not executing optimally in an otherwise correctly-behaved application – for example, things like inefficient use of cache lines, processing that is stalled for too long waiting for memory or I/O, or the presence of choke points in bus traffic.
Since the data is captured at wire-speed on the chip itself, the UltraSoC’s performance monitoring logic is 100 percent non-intrusive, says Baines. In contrast, a software-based performance profiler tool usually ends up affecting the applications runtime behavior, even if it only samples a small subset of transactions. (Capturing all the transaction points with software would cause the system to run too slowly.) For example, running iPerf, a network performance profiler, can result in a 10 percent to 15 percent performance hit.
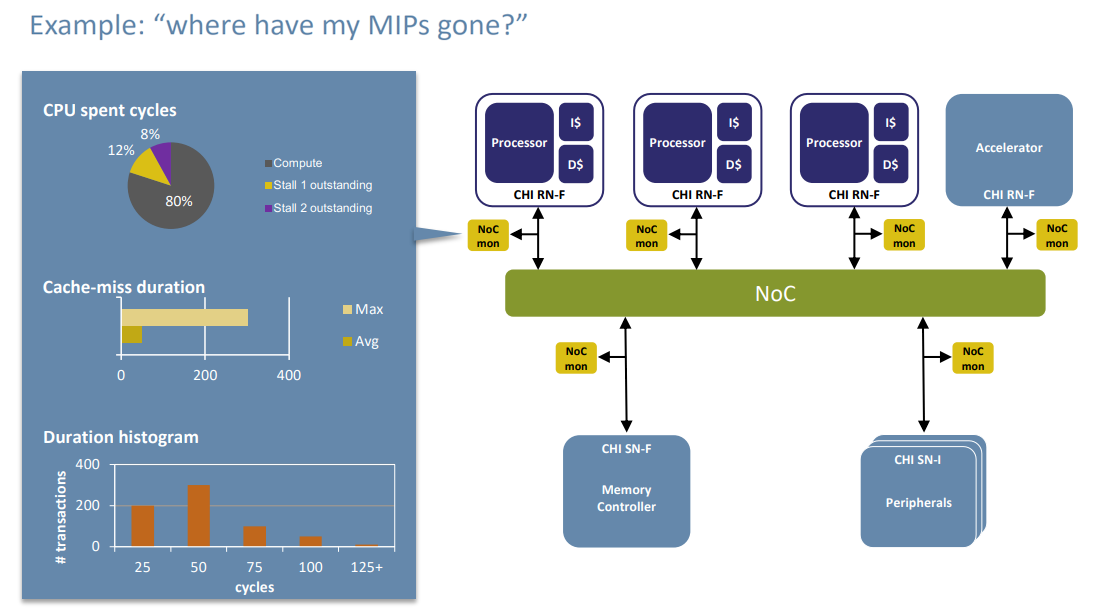
Sampling from software has another problem. Since these performance profilers let most execution go by unexamined, they can easily miss the event or combination of events causing problems. The UltraSoC approach avoids all this. “We’re completely invisible to the software,” explains Baines.
The downside is that UltraSoC has to convince chipmakers to adopt the technology and incorporate it into their own designs, which obviously has a cost impact, rather than passing on the decision to their customers to purchase third-party software tools. And in some cases, these tools are free or come with the chips that the vendor provides.
Supposedly, the extra logic needed for performance monitoring takes up just half a percent or so of an entire chip, according to Baines, so the transistor budget is not significantly impacted. And because the processing itself is not computationally demanding, the extra power required to drive the performance monitoring is negligible.
Even so, the logic UltraSoC has developed does more than just monitoring and data collection. It actually contains a modicum of intelligence and does some rudimentary analysis, such as figuring out averages and peaks of with regard to timing, as well as filtering data to look for exceptional events.
The logged data from the chip can be output through various I/O interfaces, such as USB, Ethernet, or PCI-Express, even Wi-Fi if it is available. Those results can be fed into UltraSoC-provided software tools to do more sophisticated analysis (some of which is done with the help of machine learning) that search for anomalies and interesting correlations. Baines is fairly certain that a number of their clients will develop their own analytics software to comb through the output data according to their particular needs, noting that “some of our customers are the kinds of people with very big data science teams.”
One of UltraSoC’s customers in this space, Esperanto is developing a machine learning SoC, with 4,000 or so processing elements on a single die. The chip is based on the RISC-V architecture and like many of its rival devices making their way into the market, is designed for high floating point performance and energy efficiency. The company is hoping that putting the monitor and some of the analytics on their chip will make it easier for their customers to develop more optimal software.
Besides Esperanto, most of UltraSoC’s other server-side customers are keeping the relationship under wraps, at least for the time being. At this point, UltraSoC has more than two dozen clients on their public list, including Intel, Huawei/HiSilicon, and MIPS, but none of those appear to be based SoC implementations for scale-out environments.
The company has a number of other customers using RISC-V, a platform that doesn’t have much in the way of third-party performance analyzers and debuggers. That said, Baines notes they also have Arm and MIPS customers, and since the technology is architecture-agnostic, it can be applied to any processor, even X86 chips, were Intel or AMD to be interested.
Earlier this month, UltraSoC announced a “a significant extension” to its on-chip monitoring and analytics logic, enabling customers to incorporate the technology into much larger-sized systems – up to 65,000 server nodes. “Future iterations will allow even higher numbers of processors for exascale systems,” read the press release. The capability to handle higher volumes of data and bursty traffic was also incorporated into this latest version. Baines told us the HPC and AI software optimization has been a big area of focus area for the company for a couple of years now and has moved them into a new direction.
“You’re going to be hearing a lot more about us and a lot more from us,” Baines says.

Ventana Launches Veyron V2 RISC-V Into The Datacenter
It took the X86 architecture fifteen years get an appreciable share of datacenter compute, and it took the Arm architecture about ten years to get a foothold you could measure. Perhaps it might only take five years for the RISC-V architecture to do the same because the hyperscalers and cloud …

AI Is RISC-V’s Trojan Horse into the Datacenter
If the workload-specific datacenter dominates in the near term, it could be RISC-V’s time to shine. While most often associated with embedded devices, there is a push to use RISC-V as the base for AI and targeted workloads, giving the ISA a springboard into much larger systems. So far, there …

Europe Inches Closer to Native RISC-V Reality
The European Processor Initiative (EPI) has pinned its hopes on RISC-V as the path to European semiconductor independence. The program, which began in 2015 with the goal of building a native exascale supercomputer by 2023, took longer than expected to work out the architectural plan for its RISC-V designs but …
Be the first to comment