

What is the difference between a SmartNIC and a server processor? About three years, if you are Amazon Web Services.
The biggest news for sure to come out of the public cloud juggernaut’s re:Invent 2018 conference in its hometown of Seattle is the homegrown “Graviton” Arm server processor that its Annapurna Labs division, which it acquired back in 2015 for $350 million, has cooked up to host EC2 virtual compute instances besides the Intel Xeon and AMD Epyc instances that AWS already runs.
The fact that AWS has created its own server chip rather than deploy the ThunderX2 chip from Marvell (formerly Cavium), which is the current leader in Arm servers these days after Qualcomm dropped out with its Centriq 2400 and Applied Micro took a breather before its X-Gene was snapped up by Ampere (a new company funded by private equity firm The Carlyle Group), is significant. But it does not mean that Arm chips from Marvell and Ampere – and possibly someday Fujitsu with the 48-core, vector-juiced A64FX processor if it gets a hankering for some big-time floating point parallel processing and maybe any new entries into the Arm fold – won’t eventually get some play on the AWS public cloud.
The way we see it, AWS was already working on its “Alpine” family of dual-core and quad-core Arm chips inside Annapurna Labs to create SmartNICs for its server fleet. These SmartNICs are an integral part of that server fleet, offloading just about all functions but the operating system and applications from the Xeon, Epyc, and now Graviton processors on EC2 instances so that the compute cores in those instances are largely available to run applications. (This is called the Nitro System, and we will be exploring this separately in a future article.)
We have said it before, and we will say it again: The major hyperscalers and cloud builders are living in the SmartNIC future that HPC centers can appreciate since InfiniBand networking has an offload model, too, with intelligent NICs that can be made into what Mellanox Technology calls half-jokingly – but only half – GeniusNICs, and that enterprises will eventually get behind for the same reason that the hyperscalers and HPC centers often adopt offload: That core compute is expensive, and the offload compute is, relatively speaking, not.
Amazon and Annapurna Labs have not said much about the Alpine family of chips since their initial debut back in January 2016, when it unveiled 32-bit Armv7 and 64-bit Armv8 designs and said generally that they had “enterprise-class performance and features” such as support for DDR4 memory and 2 MB of L2 cache on their dies. Here is a list compiled for Annapurna’s Alpine chips used in network appliances (home routers and basic Ethernet switches) as well as in storage appliances. There are dual-core and quad-core 32-bit devices based on the Cortex-A15 cores from Arm Holdings that runs at 1.4 GHz for the dual-core chip and at 1.7 GHz for the quad-core chip, plus a quad-core based on the Cortex-A57 design that also runs at 1.7 GHz. These Arm Cortex cores sport both superscalar pipelines and out of order execution, but they do not have hyperthreading.
There is nothing particularly impressive about these feeds and speeds, and we can’t say much about the architecture since Amazon didn’t say hardly anything, but what we presume is impressive is how cheap these devices are for Amazon to make and how much server offload compute they can do to make the overall servers, networks, and storage at AWS more efficient. This is certainly the strategy that Mellanox is pushing with the Bluefield multicore Arm processors, that Microsoft is using with FPGAs as network accelerators and compute engines in the servers in the Azure public cloud, and Netronome is peddling with its Agilio network adapters.

While we don’t know much about the Graviton chip, it seems to be a far more substantial processor, something along the lines of a “Skylake” Xeon-D-2100 v2 from Intel, which has from 8 to 18 cores running between 1.6 GHz and 2.3 GHz. (The higher the core count, the lower the clock speeds, as usual.) If you poke around the AWS web site, you will discover a line that says that the Gravitons are based on the 64-bit Neoverse cores, which almost certainly means the “Cosmos” cores to be specific, which consist of tweaked versions of the Cortex-A72 or Cortex-A75 designs from Arm and which are meant to be implemented in 16 nanometer chip making processes, and that probably means that Taiwan Semiconductor Manufacturing Corp is the foundry of choice here. Arm, you will recall, launched the Neoverse revamping and rebranding of datacenter Arm chips launched back in October, putting them on an annual cadence with 30 percent performance improvements per year and marching down the path to 7 nanometers to 5 nanometers between now and 2021.
All AWS has said publicly about the Graviton processor we know from the EC2 A1 instance, which supports up to 16 virtual CPUs (vCPUs) and up to 32 GB of main memory, with up to 10 Gb/sec of network bandwidth coming out of its server adapter and up to 3.5 Gb/sec of Elastic Block Storage (EBS) bandwidth. AWS did not confirm which Cosmos core it was using when we pressed for more details, and it did not confirm that Graviton had 16-cores without simultaneous multithreading to present multiple virtual threads per core. (This SMT support is often added by Arm licensees and has not, as yet, been part of the base core license from Arm. That could change with the “Ares” cores that are due in 2019.) AWS did confirm to The Next Platform that these A1 instances have Graviton chips that run at 2.3 GHz. In terms of raw integer compute, the Gravitons should be able to hold their own against the Xeon-Ds and maybe the very low end of the Xeon SPs.
Here are the feeds and speeds of the different A1 instances:

That is not a lot of memory and we presume not a lot of memory bandwidth, particularly if there is only one memory controller and two channels, as we suspect. The Xeon D-2100 v2 has two memory controllers and four memory channels, topping out at 512 GB with extremely expensive 128 GB memory sticks, but even using dirt cheap 8 GB sticks it can hit 32 GB easily. It is possible that Annapurna put a lot of memory controllers on its chip, which we also presume does not support simultaneous multithreading and therefore we expect it has 16 cores on the die. A nice balance would be one memory controller for each eight cores, but maybe even four memory controllers would be better if you wanted to get compute capacity and memory bandwidth back into balance. (AWS was not bragging about this, so we suspect it has not done this.)
The A1 instances run Amazon Linux 2, the homegrown Linux that evolved from Red Hat Enterprise Linux and its CentOS clone; they can also run real RHEL and Ubuntu Server, and other operating systems – wouldn’t it be funny if Windows Server gets ported to the AWS Arm server chip? – coming in the future. The Arm-based A1 EC2 instances are available now in the US East, US East, US West, and Europe (Ireland) regions in the usual spread of On-Demand, Reserved, Spot, Dedicated, and Dedicated Host instance subscription types. AWS warns that these A1 instances are really intended for scale-out workloads that are not particularly memory bandwidth bound, such as web servers, development environments, caching servers, or containerized microservices that are not too heavy and presumably too stateful as well. AWS says that these instances can be up to 45 percent cheaper to run than equivalent X86 instances on EC2, but it is not clear what AWS is comparing there.
The big point is: Now we get to see what the appetite for Arm servers really is for basic infrastructure. There will no doubt be a lot of tire kickers for the A1 instances, and this is a good thing to help fund development of what would have very likely been the next generation of SmartNIC processor for the company anyway.
In addition to the Arm-based A1 instances, AWS fired up some other infrastructure variations on the EC2 theme. The new C5n instances sport 100 Gb/sec Ethernet networking between them, which makes them suitable for certain bandwidth-dependent HPC simulation and modeling, machine learning training, and intensive data analytics workloads. Like the C5 and C5d instances, these C5n instances are based on a two socket server node that has custom “Skylake” Xeon SP 8000 Platinum series processors, and it looks like they have 18 cores per chip running at 3 GHz.
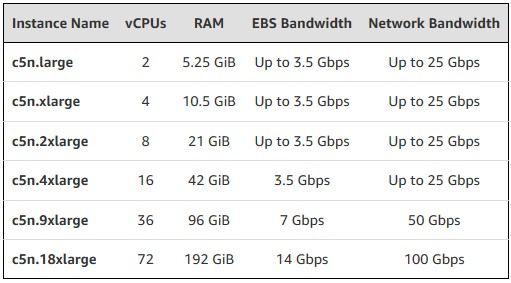
In addition to the extra bandwidth, the C5n instances have for times as many data queues as the C5 and C5d instances – 32 queues versus 8 queues in the Elastic Network Interface (which is implemented on Annapurna Labs Alpine processors sitting next to the NIC to make it smart – which helps spread out the data coming into the network adapters better across the cores in the box. That bandwidth is available in the same region (either within one availability zone or across multiple zones in the region), and can be used to cluster EC2 instances to each other as well as linking them to S3 object storage or services like Elastic MapReduce, Relational Database Service, or ElastiCache. The C5n instances are available in the same regions as the A1 instances, plus the GovCloud private cloud for the US government.
Finally, AWS is bringing 100 Gb/sec Ethernet networking to the P3 GPU-accelerated instances that were launched last October and that topped out at 25 Gb/sec server links out to the AWS network. These P3dn instances with faster networking will be available next week, and they also sport “Volta” Tesla V100 GPU accelerators that have 32 GB of HBM2 memory as opposed to the 16 GB that was included in the original Voltas and used in the original P3 instances. These instances are based on a pair of custom 24-core Xeon SP processors and have up to eight GPUs in the chassis.




Be the first to comment