

If it’s the SC18 supercomputing conference, then there must be lists. Lots of them.
The twice-yearly show is most famous for the Top500 list of the world’s fastest supercomputers that use the Linpack parallel Fortan benchmark, a list that helps the industry gauge progress in performance, the growing influence of new technologies like GPU accelerators from Nvidia and AMD and the rise of new architectures, as marked this year by the introduction of the first supercomputer on the list powered by Arm-based processors. The “Astra” supercomputer, built by Hewlett Packard Enterprise and deployed at the Sandia National Laboratories, runs on 125,328 Cavium ThunderX2 cores and now sits in the number 205 slot.
The list also helps fuel the ongoing global competition for supercomputer supremacy, with the United States this year finally retaking the top spot from China’s Sunway TaihuLight in July with the Summit system based on IBM Power9 and Nvidia Volta compute engines, and then Sierra, a similarly architected machine, taking the number-two slot at this week’s SC18 show in Dallas, pushing TaihuLight to number-three. However, China now claims 227 systems – or about 45 percent of the total number – on the Top500 list, with the United States dropping to an all-time low of 109, or 22 percent.
The Green500 ranks supercomputers based on power efficiency. The Shoubu System B, a Japanese cluster built by Pezy Computing, retain the number-one spot this year.
Also on the list of lists is the Graph500, which ranks systems based on how they run the fast-growing data-intensive workloads using graph analytics algorithms. The number of such supercomputer applications are growing as the amount of data being generated continues to pile up, and some in the industry believed that benchmarks traditionally used to rank HPC systems for such work as 3D physics simulations were unsuitable for data-intensive workloads.
“I don’t think it’s a leap to convince anyone today that this is of importance because frankly the market for data analytics has overgrown HPC by an order of magnitude,” Anton Korzh, a system architect at Micron Technology and a member of the Graph500 executive committee, said during the event at the show this week to release the 17th version of the list. The first one came out in November 2010.
The Graph500 addresses two application kernels, concurrent search marked by breadth-first search (BFS) and optimization, or single-source shortest path (SSSP). Plans are underway for a third kernel for edge-oriented, or maximal independent set, Korzh said. The list addresses five graph-related business areas of cybersecurity, medical informatics, data enrichment, social networks and symbolic networks.
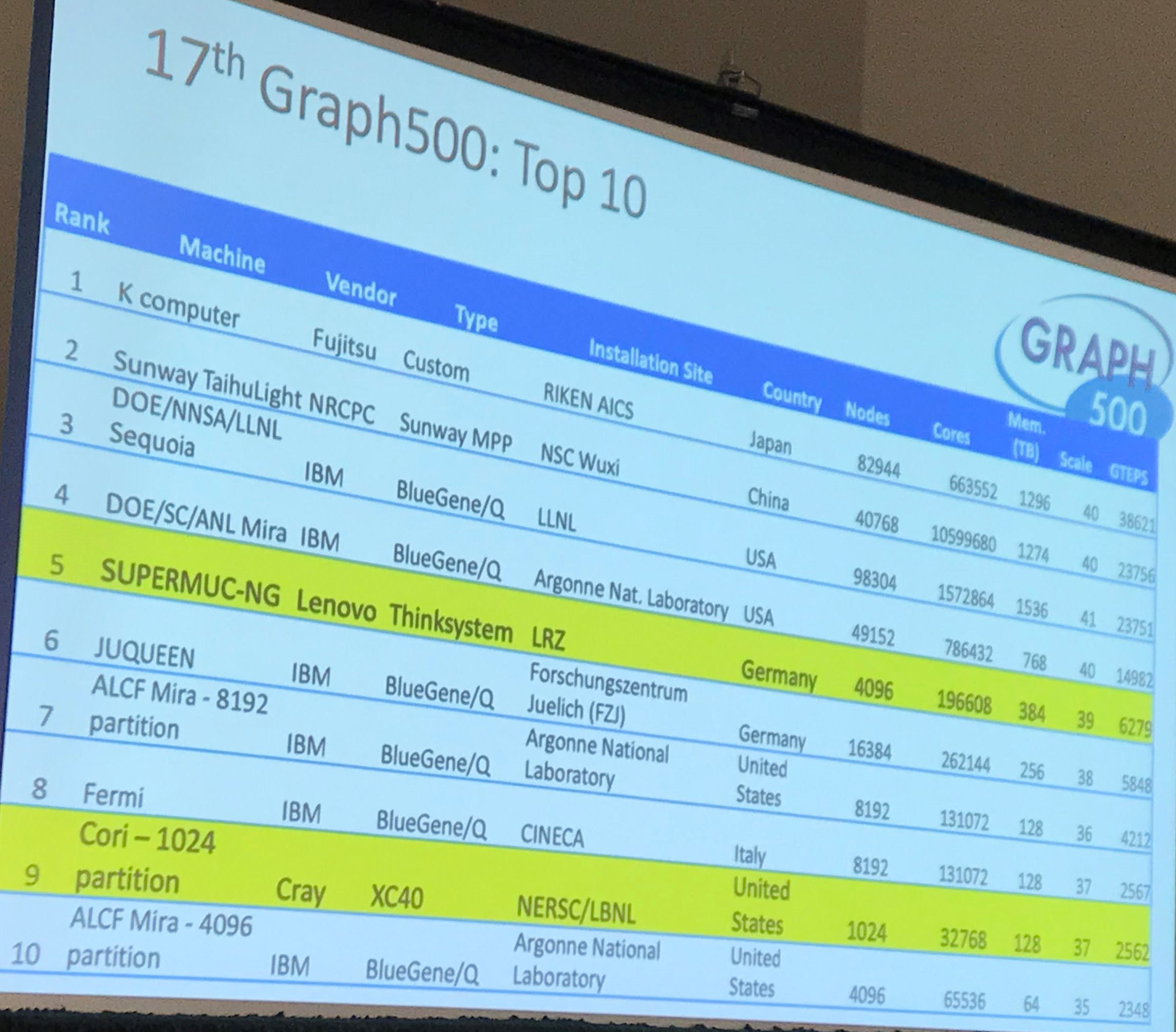
The number of submissions has grown from eight in the first year to 48 for the current list, which includes two new entries into the top ten and once again had the giant K computer in Japan and built by Fujitsu sitting in the top spot with 38,621.4 GTEPS, or giga-traversed edges per second, the metric used by the Graph500. The seven-year-old K computer sports 82,944 nodes and 663,552 Sparc64-XIIIfx cores. The Sunway TaihuLight came in second, followed by Sequoia and Mira – both IBM BlueGene/Q systems running in US national laboratories – and SuperMUC-NG, a Lenovo cluster housed in Germany.
But as the Graph500 committee celebrated the release of the latest list, Roger Pearce, a computer scientist in the Center for Applied Scientific Computing (CASC) at Lawrence Livermore National Laboratory – home to both “Sequoia” BlueGene/Q system made by IBM as well as the shiny new Sierra system – said the changes were needed for the Graph500 to remain relevant. Pearce spoke during the event about the lab’s approach to using NVRAM (non-volatile random-access memory) in Sierra when it comes to analytics for performance and scaling.
However, at the end of his presentation, Pearce urged that changes be made to keep the list being an important indicator in the industry. It needs to evolve or it will no longer be relevant. One thing that has to change is the continued use of vertex labels 0, N.
“Vertex labels from 0 to N are just not realistic,” he said. “If we want to try to be in a realistic mode, we need to deal with hyper-sparse labels – 64-bit hashes, maybe even higher than that – specifically with unknown cardinality. We don’t really know how many vertices there are, because with really large vertex sets, it’s really expensive to remap these to N. This is a real challenge. It’s not something that’s even tracked by the Graph500. For all the talk that we need a streaming Graph500, this is like a baby step to doing that. If you can’t do this, you certainly can’t do streaming graph analytics. In my view, the healing will begin when we move away from stone-age static data CSR/CSC.”
Pearce had a similar view of BSD.
“A decade of breadth-first search is enough. It’s too simple to catch the memory/communication intensity and parallelism of many important analytics and many of the current optimizations do not transfer to many important analytics like Betweeness Centrality. I don’t know about you, but I often get asked, ‘Why are there thousands of papers on breadth-first search?’ And I say, ‘It’s a simple answer: the Graph500.’ We’ve got to figure out what we’re trying to capture.”
It’s not to say that the past eight years of work have been for naught. There have been significant advances in distributed memory graph algorithms because of the Graph500’s efforts, he said. “If you remember back to the early days, there was enormous skepticism that distributed memory graph analytics would work at all. They used to say, ‘BlueGenes would never do well on the Graph500,’ and now they’ve dominated it for five or six years.”
His list of proposals for the Graph500 for 2020 is moving on from 0, N graphing and “split inputted edges into k bins, like timesteps – 64, 16, I don’t know what k should be. Incrementally append each edge bin into the graph and re-compute some analytic, maybe count duplicates so it forces people to add indexes to their hedge lists and things like that, that are powerful for the analytics. Finally, the output would be like, k results for every edge or vertex given your analytic.”
The analytics should be anything but BFS, with possibilities being alternatives like Betweeness Centrality and full K-core decomposition. Lastly, he said, given how difficult it is to validate these higher-level algorithms, validation should use small unit-tests graphs with pre-computed ground truth.
After Pearce spoke, Peter Kogge, a professor of computer science and engineering at Notre Dame and also Graph500 executive committee member, seconded the suggestions and added some of his own, including using multiple classes of vertices. Korzh said Pearce made fair points that should be considered.


Unified Memory: The Final Piece Of The GPU Programming Puzzle
Support for unified memory across CPUs and GPUs in accelerated computing systems is the final piece of a programming puzzle that we have been assembling for about ten years now. Unified memory has a profound impact on data management for GPU parallel programming, particularly in the areas of productivity and …
Burying The OpenMP Versus OpenACC Hatchet
I have been frequently asked when the OpenMP and OpenACC directive APIs for parallel programming will merge, or when will one of them (usually OpenMP) will replace the other. I doubt the two APIs will or can merge, and whether one replaces the other depends more on whether users abandon …

Two Thirds of The Way Home With Exascale Programming
To effectively make use of the level of concurrency in forthcoming exascale systems – hundreds of thousands of compute elements with millions of threads – requires some new thinking, both by programmers and in development tools. On the path from petascale to exascale, from pre-CORAL “Jaguar” to CORAL 2 “Frontier,” …
Be the first to comment