
The twice-annual ranking of distributed computing systems based on the Linpack parallel Fortran benchmark, a widely used and sometimes maligned test, is as much a history lesson as it is an expectation always looking forward, with anticipation, to the next performance milestones in high performance computing. As we have pointed out before, history is not a line, but a spiral, widening out and going through familiar territory again and again, but always just a little bit different just to keep it interesting.
The architectures embodied by the most powerful systems in the world sometimes cascade down to broader use in the wider HPC market, and sometimes they do not because these upper echelon technologies don’t scale down as well as they scale up – both technically and economically. Sometimes, only the richest companies or best funded government or academic supercomputing centers in the world can afford a novel architecture, but every now and then one of these technologies breaks out and goes mainstream, and sometimes from the bottom of the market, not the top. This is exciting to see when it happens, such as when Linux clusters took off in the late 1990s with the powerful combination of the Message Passing Interface (MPI) protocol for sharing work across nodes in a cluster and the OpenMP parallelism layer to help spread out work within the nodes. This utterly transformed HPC.
Many people want such a convergence once again, because it was wonderful and easy and radically changed the economics of HPC for the better compared to federated RISC/Unix NUMA systems that ran out of scalability and cost way too much. But the odds are that we will see multiple and varied architectures, mixing a variety of compute engines, for the foreseeable future for political as well as economic and technical reasons. In some cases, organizations will stick with parallel CPU nodes that are fairly skinny and others will go with fewer numbers of very fat CPUs crammed to the air slots with accelerators. Or a mix of the two within a single cluster. The details of the machines may change, but the general feel of the architectural choices will not because HPC application pegs do not all fit in the same holes.
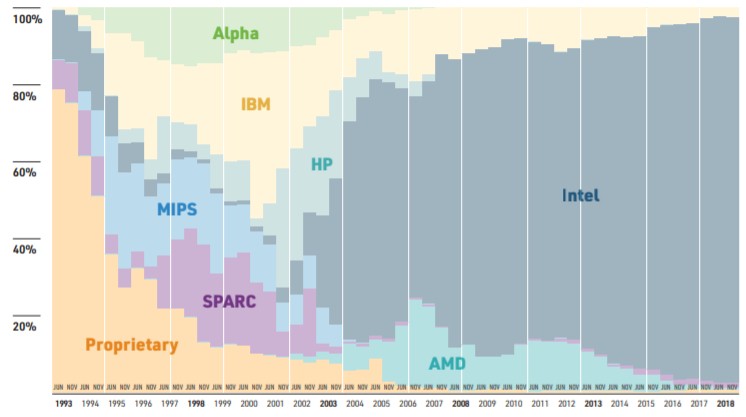
For now, Intel’s Xeons are the CPUs of choice, with a 476 of the 500 machines on the November 2018 Top 500 rankings (95.2 percent share of installed machines), and of those 137 machines that are accelerated, 98.5 percent of them have Nvidia Tesla GPU accelerators as the main floating point processing engines; the remaining 1.5 percent are older Intel “Knights Corner” parallel X86 accelerators that predate the host versions of the Knights family. We could split hairs and say, for instance, that the Sunway SW26010 processor installed in the TaihuLight system in China, which was the most powerful machine in the world for two years as ranked by Linpack, really embodies a hybrid processor-accelerator approach, but does so within the confines of a single piece of silicon. The Knights Landing Xeon Phi chip from Intel, which has been discontinued and replaced by dual-chip Xeon modules that are looming, kept the accelerator and tossed the Xeon host CPU away. What do you call that? Apparently a boomerang, because the CPU came flying back . . . .
Suffice it to say, Intel and Nvidia are kings of their respective CPU and GPU domains at this point in the history of supercomputing.
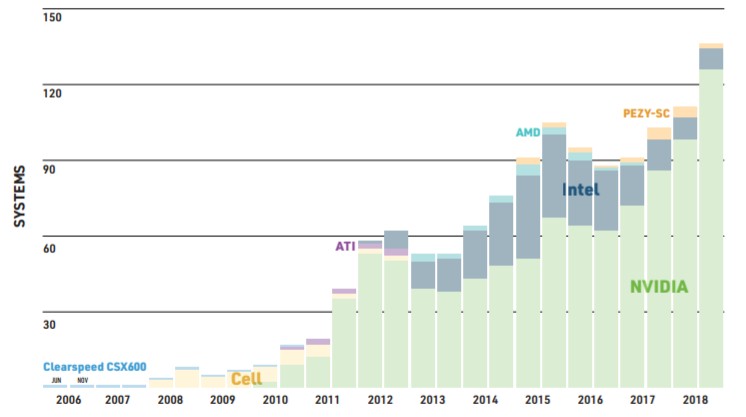
Nvidia has fulfilled its own goals and our expectation, from way back in 2010, that more and more of the aggregate double precision floating point computing power on the Top 500 list would come from accelerators. On the current November 2018 ranking, of the 1.41 exaflops of combined performance on the list, 702 petaflops of that is coming from accelerators, and 506 petaflops comes from Nvidia GPUs. That is a factor of 12X growth in GPU flops on the Top 500 list in five years 6X growth in two years, and 3.5X that of the November 2017 list – thanks in large part in the past year to the addition of the “Summit” system at Oak Ridge National Laboratory – ranked number one on the current list with 143.5 sustained petaflops on Linpack versus 200.8 petaflops peak – and the “Sierra” system at Lawrence Livermore National Laboratory – ranked number two with 94.6 petaflops sustained against 125.7 petaflops peak. Both Summit and Sierra are based on the combination of IBM Power9 processors, Nvidia Tesla V100 GPU accelerators, and NVLink interconnect on the nodes and Mellanox Technology 100 Gb/sec EDR InfiniBand linking between the nodes. Here is the interesting statistic: Of the 152 new machines on the November 2018 rankings, 52 of them are hybrid CPU-GPU systems and 100 of them are straight CPU clusters. So while the installed base shows GPUs on only 27.4 percent of the systems, GPUs are present on 34.2 percent of new machines. Half of the Top 10 machines have Nvidia GPUs as their main compute engines.
We have complained about the shortcomings of the way the Top 500 list is gathered, ignoring very powerful machines that are clearly supercomputers running real HPC workloads and accepting data from hordes of machines installed at hyperscalers and telcos that don’t do real HPC and therefore, in our estimation, should not be on the Top 500 list if it is indeed supposed to be a ranking of the most powerful machines for simulation and modeling workloads in the world. To be truly complete, there should be some mechanism to make sure tested machines have real HPC as their day jobs, and moreover, the list should include the feeds and speeds of systems that have not been tested, the most famous of which being the Cray “Blue Waters” system at the University of Illinois. While we are dreaming out loud, we might as well add in all of those classified machines that really are doing HPC that we can’t see and never will.
Our point is, the actual world of supercomputing, as we think about it as including both traditional HPC simulation and modeling workloads as the main course with a growing second course of machine learning workloads that either run side-by-side or in the same workflow as these traditional HPC applications, could be a lot different from the list that the good people behind the Top 500 are able to get approval to run from the centers that do official Linpack tests to rank their machines. Or maybe the architectures would not change all that much and the trend lines would be pushed further up the Y axis.
The positive way to look at this is that if at least some people didn’t want or need to brag, we would know even less than we do, and there would be no trend lines to motivate us and push the envelope on technology. If the Top 500 does anything well, it certainly does that. And it will continue to do that in the years ahead.
The one thing that will change for sure in the years ahead, though, is not the architectural choices we outlined above so much as the option to use a wider variety of CPU and GPU compute as well as interconnects to lash together machines into supercomputers.
AMD is back in the field with its Epyc processors and Radeon Instinct GPU accelerators and is looking ahead to a brand new lineup with the “Rome” Epyc CPUs and the “Vega 20” Radeon Instinct GPUs in 2019, and AMD’s downstream OEMs and ODMs will start winning deals in HPC. AMD will take a bite out of Intel’s CPU share, and it may even garner the 20 percent to 25 percent share that it enjoyed on the Top 500 list at the peak of the Opteron X86 server chip run for the datacenter a little more than a decade ago. But AMD may not slow down Nvidia so much as help expand the market for GPU acceleration for those classes of workloads that don’t need the Tensor Core matrix multiply accumulate units that AMD has not, as yet, had an answer to. We will have to see on that one.
Hewlett Packard Enterprise, working with Marvell’s Cavium unit, has put Arm server chips on the map with the “Astra” supercomputer at Sandia National Laboratories, which is based is based on 28-core ThunderX2 processors and which has a peak performance of just over 2 petaflops and delivered 1.53 petaflops of oomph on the Linpack test. This is a stake in the ground for Arm, and Fujitsu will follow some years hence with RIKEN lab with the “Post-K” Arm-based exascale supercomputer. There will be other Arm chip suppliers in the HPC realm, chasing all of that money that Intel is minting selling Xeons, which are in short supply because Intel’s manufacturing arm ramped down 14 nanometer processes to make way for 10 nanometer processes only to find its 10 nanometer etching doesn’t yield as planned. And Arm, with its Neoverse line of chip architectures and a new manufacturing roadmap to match, is eager to take a real bite out of Intel’s compute empire. NEC is doing its part for compute diversity with its “Aurora” vector processor, too.
The diversity is also coming to supercomputing interconnects, including ever-faster InfiniBand from Mellanox and Omni-Path from Intel as well as a slew of Ethernet chip suppliers that want to get some traction in HPC here and there. Proprietary interconnects still have their place, and the “Aries” interconnect created by Cray for its “Cascade” XC supercomputers will be replaced by the “Slingshot” HPC-juiced Ethernet interconnect that Cray has been cooking up for the past five years for its impending “Shasta” systems.
Shasta is perhaps exemplary in the approach that all HPC systems will have to take in that it will be agnostic about compute, interconnect, and system power and cooling, but offer lots of options on all of these fronts so customers can tune their hardware more fittingly to their HPC applications. This flexibility is one of the reasons why Berkeley Lab is the first customer for Cray’s Shasta systems, based on future “Milan” Epyc processors and the Slingshot interconnect.
Hewlett Packard Enterprise, Dell, and Lenovo have all been advocating for an open stack of hardware and software for HPC, and have embraced both Arm and AMD processors as well as Xeon Phi processors and accelerators alongside mainstream Intel Xeons, Nvidia GPUs for compute, and InfiniBand, Omni-Path, and Ethernet interconnects to lash the nodes together into a fabric. And they will adopt AMD GPU accelerators where they make sense (where raw floating point and cost are the key factors and where machine learning inference is more important than training). Perhaps most importantly, all of the key OEMs in the HPC arena are tired of basically just rebranding Intel’s HPC integrated stack– from processors and chipsets through interconnects and non-volatile memory to the evolving OpenHPC software – and giving Intel most of the margins from these HPC sales. By offering a diverse set of components to a wide set of customers, the OEMs start to have a little more leverage, and you can damned well bet they are going to use it against each other to win deals and against their suppliers to get better pricing and therefore better profits from HPC deals.
In the end, the HPC market will be more diverse and the Top 500 will reflect this increasing diversity. We look forward to seeing it happen, for the sake of the industry and for the supercomputer users who, in one way or another, are trying to enrich or secure our lives.


The Metronomic Cadence Of Chippery From AMD
Companies invest in platforms over a decade or more, and that is why architectures persist longer than we might think given technological differences and economic forces. It is unreasonable to expect a roadmap from any component supplier that spans ten years, but companies do expect to see at least two …

Ampere DGX Servers Pack A Wallop, Including AMD Epyc CPUs
A new CPU or GPU compute engine is always an exciting time for the datacenter because we get to see the results of years of work and clever thinking by hardware and software engineers who are trying to break through barriers with both their Dennard scaling and their Moore’s Law …

AMD Girds For Compute War With Xilinx Deal
The rumors were right, and AMD president and chief executive officer Lisa Su is indeed printing out a tower of stock to acquire FPGA maker Xilinx for what amounts to about $35 billion and, as it turns out, she is relinquishing her position as president to Victor Peng, chief executive …
Be the first to comment