

The shenanigans with the Top 500 rankings of the world’s most powerful supercomputers continues, but there are a bunch of real supercomputers that were added to the list for the June 2018 rankings, and we are thankful, as always, to gain the insight we can glean from the Top 500 on these new machines that are clearly used for HPC workloads.
As we have been complaining about for some time, most recently with the November 2017 rankings, the list is losing accuracy even as it maintains high precision because vendors often work to get machines tested running the Linpack Fortran matrix math benchmark for political and economic reasons, even if these machines are not really running HPC workloads as their day jobs, and it is a stretch to even say they are running machine learning or analytics applications in many cases. The researchers behind the Top 500 rankings for the past 25 years have been interested in getting as many machines with as many architectures as possible tested to do comparative analysis, and this is commendable and if often useful. Particularly with regard to true HPC machines, large and small, gauging performance of various compute engines and interconnects and at various scales. This is invaluable data, no question.
But depending on the aggressiveness of countries and vendors to run the test, big swings can happen in the middle of the list, particularly with machines that come from industry rather than government labs and agencies, academic labs, and other research institutions that are unquestionably doing HPC as we know it. The thing you always have to remember with the Top 500 “supercomputer” rankings is that it is not the Top 500 systems known in the world, but rather the Top 500 systems that ran the test for that particular June or November ranking. There are many actual HPC machines and an even larger number of clusters that are larger than anything on this list – Google’s average cluster is 10,000 to 50,000 nodes – that never run Linpack and therefore are not ranked. Let us remind you of something once again: Google could carve up its base of several million servers, run Linpack on its clusters, and wipe every machine on this list clean off. And then have enough left over to rule the Top 1,000 “supercomputers.”
Let that sink in for a moment.
This is why we think that the people who create the Top 500 should have never started letting anyone who ran the test onto the list – they should have to demonstrate that they are real HPC machines. Moreover, there might be as much real HPC that is off the list in blackops at the security agencies and militaries of the world as is on the list. We just wish there was a better way to gauge what is actually happening in HPC. As it turns out, Linpack and other tests like HPCG do drive architectures and provide competitive pressures between vendors and across countries that does in fact stimulate spending on HPC and innovation within HPC. So this is the good that comes from this incomplete information that is offered to the Top 500 organizers. Don’t think we are not grateful.
Now that we have gotten that out of the way and cleared the air, let’s talk about the 50th list, which is being announced this morning at the International Supercomputing 2018 conference in Frankfurt, Germany.
Much will be made of the United States getting back into the upper echelons of supercomputing, with the “Summit” hybrid IBM Power9-Nvidia Tesla V100 system at Oak Ridge National Laboratory and its slightly differently configured “Sierra” companion at Lawrence Livermore National Laboratory coming onto the list at number 1 and 3 after years of anticipation.
The portion of the Summit machine that was tested has 4,356 nodes, each with a pair of 22 core Power9 processors and six Nvidia Volta GPU accelerators. We were under the impression from IBM and Oak Ridge that this machine would have a peak performance of 207 petaflops, and as far as we know, Summit has 4,608 nodes, all of which were installed. We will be drilling down into the Summit machine separately, but 95 percent of the 187.7 petaflops of peak theoretical performance of the 4,356 nodes of Summit for Linpack comes from the double precision math units on the Volta GPUs, which obviously have single precision, integer, and Tensor Core units that can have work dispatched to them, too. The Power9 CPUs can also so useful work. The Summit machine has 2.28 million cores and streaming multiprocessors (clusters of CUDA cores, with 80 active per Volta chip) and the Power Systems AC922 nodes are linked to each other on a dual-rail 100 Gb/sec InfiniBand network from Mellanox Technologies. On the Linpack test, the Summit machine deliver 122.3 petaflops of oomph, which is a computational efficiency of 65.2 percent – not bad for a new machine, and clearly this will improve over time.
The number two machine on the list, which was ranked in first place for two years, is the Sunway TaihuLight system at the National Supercomputing Center in Wuxi, China, which is comprised of 10.65 million cores based on the homegrown SW26010 260 core processor and that, importantly, has a computational efficiency of 74.2 percent running Linpack to hit its 93 petaflops sustained, but it takes 15.37 megawatts to do it, compared to only 8.81 megawatts for the 122.3 petaflops of the Summit system. China will be pushing the power envelope down, no doubt, with its next generation of pre-exascale systems even as it pushes up the performance, so the United States and China will be playing leapfrog.
This is good for the HPC industry, and arguably good to spur continuing investment and to engage in a little friendly competition that has not turned into anything like a trade war.
The Sierra machine comes onto the June 2018 rankings at number three, and is made up of 4,320 nodes with two of those 22 core Power9 chips plus four of the Volta GPU accelerators. LLNL told us back in October last year that this machine would be rated at a peak of 125 petaflops and consume around 12 megawatts, but on the Top 500 rankings, this machine is showing a peak of 119.2 petaflops and delivers 71.6 petaflops sustained on Linpack, for a computational efficiency of 60.1 percent; official power consumption figures were not added to the Top 500 list at press time for the Sierra machine.
The number 4 machine on the June 2018 list is the Tianhe-2A system at the National Supercomputer Center in Guangzhou, China, which has replaced a mix of Xeon Phi coprocessors from Intel with its homegrown Matrix-2000 DSP accelerators, boosting its peak theoretical performance by 54.5 percent to 100.7 petaflops. The Tianhe-2A machine using the Xeon Phi coprocessors had a computational efficiency of 61.7 percent, and with the Matrix-2000 accelerators, it remains at 61 percent.
At number 5 on the list is a new machine, which we have covered before, called the AI Bridging Cloud Infrastructure, or ABCI, supercomputer at National Institute of Advanced Industrial Science and Technology in Japan and built by Fujitsu using a mix of Intel Xeon SP processors and Nvidia Volta GPU accelerators. This system is very energy efficient, burning only 1.65 megawatts to deliver 32.6 petaflops peak and 19.9 petaflops sustained on Linpack, again that 61 percent computational efficiency. No surprises. This is a hybrid CPU-GPU machine with 100 Gb/sec InfiniBand interconnect between its nodes.
The other five machines in the June 2018 Top 500 are existing systems, some of them looking a little long in the tooth:
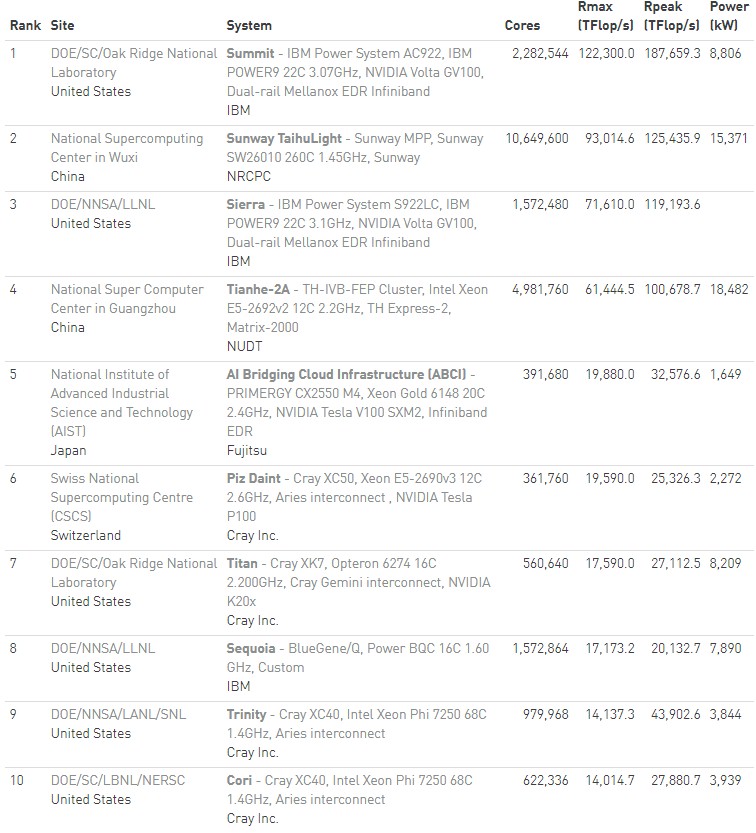
Now, let’s get into some generalizations. In terms of processor architecture, the Intel Xeon utterly dominates the list in terms of the architecture of the CPU of the systems in a cluster. Take a look:
IBM and AMD could see a resurgence in the coming years with their respective Power and Epyc processors, and Arm server chips, particularly from Cavium, could carve out a slice, too. But even with that, the Intel Xeon will continue to dominate on the CPU side.
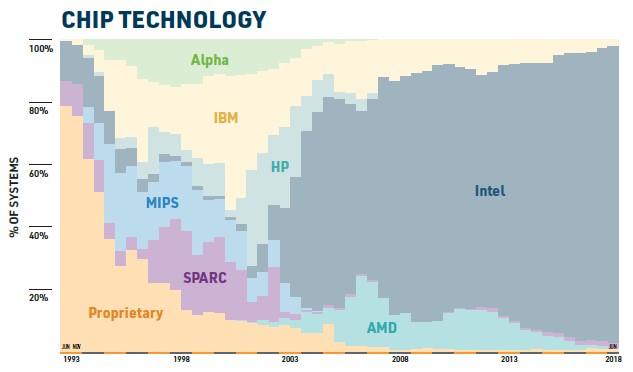
On the accelerator front, where a substantial amount of the math work is done off the CPU, and now half of the aggregate performance on the Top 500 list comes from accelerated systems of some form. These can be GPUs from Nvidia or AMD or manycore accelerators from Intel or even the special math coprocessors made by PEZY, whose future has been called into question by some legal issues in recent months. (This is sad, given how wickedly energy efficient the Zettascaler accelerators were compared to even GPUs.)
Nvidia is doing some victory laps with the June 2018 Top 500 rankings, with 56 percent of the new capacity added to the list coming from Nvidia GPUs. There were 98 GPU accelerated machines on the June 2018 list, up from 86 on the November list and including 26 new machines. (Some fell off the list because they were no longer big enough to be included.) The aggregate capacity of GPU petaflops has jumped by 260 percent in the past year.
Here’s the funny bit. Even with the advent of GPU computing, the advancement of the total capacity and the performance of the top and bottom systems on the list has not grown exponentially as expected since about 2013:
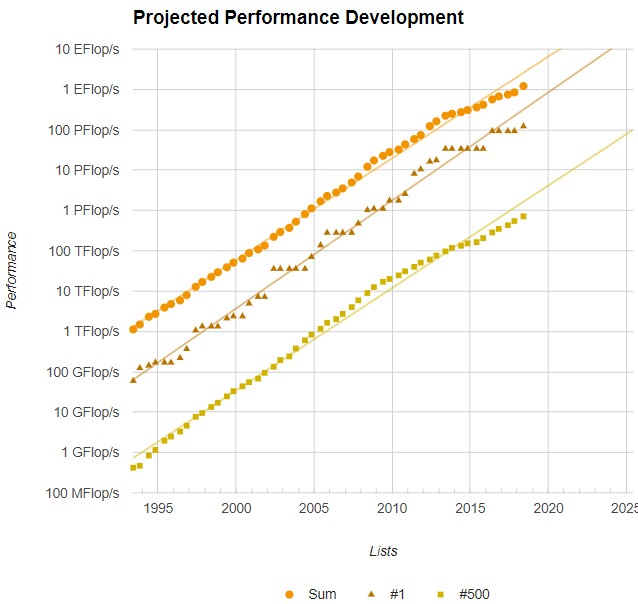
Some of this is the nature of the list changing, we think. Some of it is that it is just difficult to come up with the dough to build these massive machines. To even get onto the Top 500 list in June 2018, you need a system with at least 716 teraflops of sustained performance on Linpack, and the bottom was only 548 teraflops on the November 2017 list. Interestingly, the turnover in machines is high, but not as high as it was prior to 2013. The aggregate power of the Top 500 list continues to grow and hit 1.22 exaflops (at double precision) on the June 2018 rankings, up 44.4 percent from six months ago and up 62.9 percent from a year ago on the June 2017 list.
Another change is that there used to be a proportionately larger number of academic, classified, and research systems on the list, which you can see if you look all the way back to 1993:
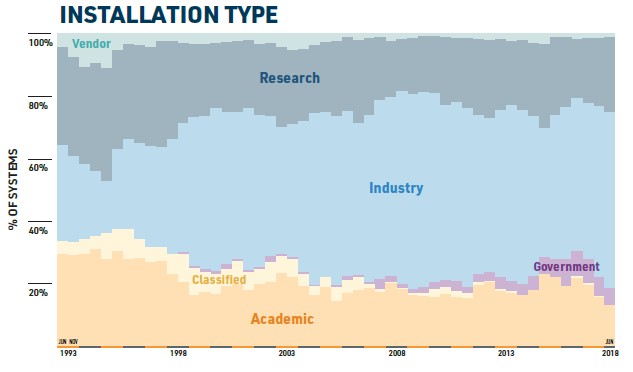
You can see the influx of telecommunications and service provider machines in that big blue wave coming out of industry in the chart above. In the past, these middle machines were largely installed by IBM and Hewlett Packard Enterprise, but now a slew of Chinese vendors are playing the game, including Lenovo (which bought IBM’s System x server business a few years ago), Sugon, and Inspur.
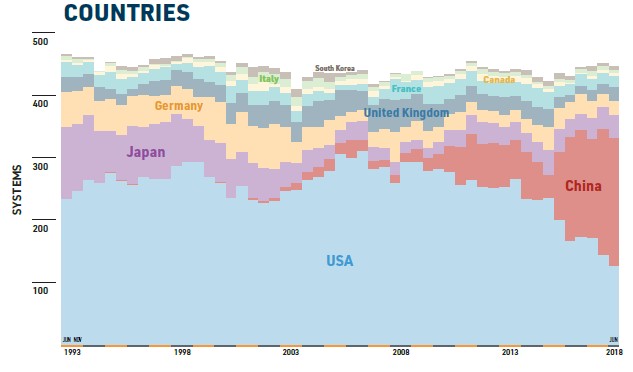
We think investment in HPC is important for business, science, and society, so if it takes political competition or economic competition to get people behind the substantial investments that are needed to push up to exascale and beyond, so be it. But we think an argument can be made without the kind of fear mongering that lead to missile buildups between the United States and Russia back in the 1960s and 1970s. The good thing about supercomputers is you can easily dismantle them, or give them away. This is frowned upon with nuclear weapons, and in fact, we have a lot of big supercomputers doing work to keep the nuclear arms stockpiles around the world ready for action. It is one of the ironies of how HPC gets funded. Were it not for the Nuclear Test Ban Treaty, supercomputing innovation might have slowed to an easier pace. Now, machine learning is driving it all forward, and more and more vendors are talking about “AI supercomputers” because the same CPU-GPU hybrid architecture that can accelerate traditional HPC workloads can also be used to do machine learning training.
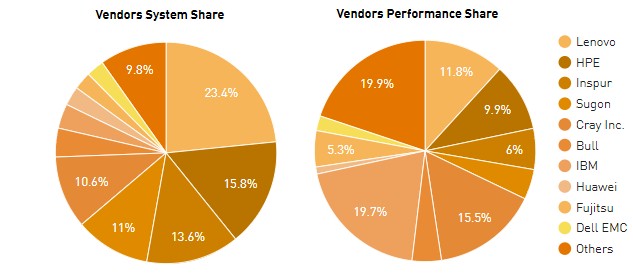
One big interesting change is that Lenovo, which does a fairly large HPC business in Europe and some in the United States (thanks to the IBM System x business) as well as a decent amount in China, was the dominant vendor on the June 2018 list. Lenovo had 119 systems on the list, up 81 systems six months ago; it has 12 percent of the aggregate exaflops on the list, up from 9.1 percent on the November 2017 list. Here is the vendor breakdown by system count and performance share:
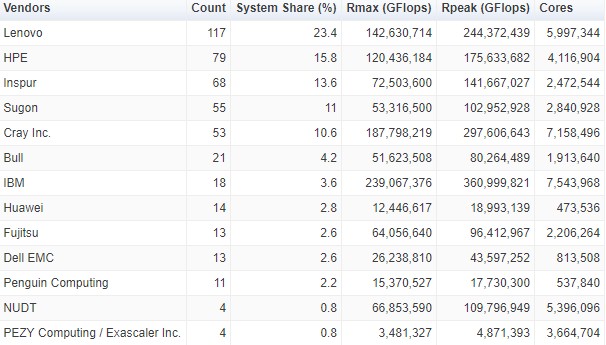
If you want to drill down into the vendor breakdown further, here is the detail on the vendor breakdown on the June 2018 list for all vendors with more than two systems on the list:
If you look at it by aggregate performance, then this time around, thanks to the addition of Summit and Sierra, Big Blue has 19.7 percent of the 1.22 exaflops on the list. Cray has 16.5 percent of the performance pie, followed by Lenovo by 11.8 percent and HPE with 9.9 percent. A lot of HPE machines were knocked off the June 2018 list as a lot of Lenovo machines came on. This is no accident. This is just how rivals play to the Top 500 list and try to use it as a weapon. This is still war, after all. Even if it is a constructive one. Mostly.




»Google could carve up its base of several million servers, run Linpack on its clusters, and wipe every machine on this list clean off. »
Do you have a source on that?
It’s just math. Google has many orders of magnitude more machines than the largest system on the list. Given the rate that Google has been buying machines, I estimate that it has close to 3 million servers. Many of them jammed packed with GPUs for machine learning training.
Tim, Do you know or can find out what percent of Google’s Machine Learning resources are access constrained for its own business vs those available for its customers to access and use for their business. Bill.
Nice article, really enjoyed it. Regarding the 3 million servers google has, aren’t the clear majority of them just servers with mid-range Xeon CPUs with no accelerators, and a few with TPUs and GPUs.
A real war will start on the supercomputer market when AMD releases EPYC2 and VEGA 20 in 7nm.