
The irony, of course, is that there is never a summit when it comes to supercomputing. The tectonic forces of Moore’s Law, voracious appetites for compute, and government budgets that somehow pay the ever-larger bill keep pushing up the mountain ranges, higher and higher, starting with megaflops in most of our memories and, some years from now, surpassing exaflops and heading on up to any number of as-yet undecided Greek prefixes to denote big.
Even though the big photo op with Rick Perry, secretary of the US Department of Energy, which paid for the current world’s fastest supercomputer, called “Summit” and installed at Oak Ridge National Laboratory, was a few weeks ago, we have been chronicling its evolving and gradually revealed configuration for years as well as for its similar sibling, the “Sierra” supercomputer at Lawrence Livermore National Laboratory, also a DOE machine and one that doesn’t just do science, but helps manage the stockpile of nuclear weapons that the US military has amassed. Both machines are based on a combination of “Nimbus” Power9 processors from IBM, “Volta” Tesla GPU accelerators from Nvidia, and “Switch-IB 2” 100 Gb/sec InfiniBand switches from Mellanox Technologies.
As readers of The Next Platform well know, we like feeds and speeds more than just about anybody, but we wanted to be able to say something more about where the rubber hits the road. We will talk about the hardware now, and do a deeper dive on what Summit will do to drive the state of the art in simulation and push us on up towards exascale applications in a follow-up story. The hardware, though terribly challenging, is the easy part – once you can get funding to buy it, of course.
To be blunt, we were waiting to see the Top 500 list and the Linpack, HPCG, and Green 500 ratings of this new Summit machine and its Sierra companion, to do a walk through the Summit system.
The goal with Summit was to provide somewhere between 5X and 10X the performance of the prior generation and still running “Titan” hybrid CPU-GPU system – a Cray XK7 with a “Gemini” 3D torus interconnect with a node injection bandwidth of 6.4 GB/sec – installed at Oak Ridge back in 2013.
The Titan machine spent its time at the apex of supercomputing, filling 200 cabinets with tons (literally) of compute. The XK7 had 18,688 of AMD’s 16-core Opterons, for a total of 299,008 cores, with 32 GB of main memory per node. Each Opteron processor was paired with a Tesla K20X GPU, based on the Nvidia GK110 GPU, which has 2,688 CUDA cores that can do double precision math and 6 GB of GDDR5 frame buffer memory. Those CUDA cores are organized into 14 streaming multiprocessors, and for the purposes of the Top 500 rankings, each streaming multiprocessor is counted as a core with lots of threads – in this case, 192 threads running at 732 MHz. The GDDR5 memory clocks in at 2.6 GHz and delivers 250 GB/sec of bandwidth per GPU. For external storage, Titan had a 32 PB Lustre file system that had a bandwidth of 1 TB/sec.
Add it all up and Titan has 560,640 “cores” that deliver a peak theoretical performance of 27.1 petaflops and a sustained Linpack performance of 17.59 petaflops, all within an 8.21 megawatt thermal envelope. That’s a computational efficiency of 64.9 percent, which is about as good as most hybrid CPU-GPU machines are doing. (It is a shame that this number is not higher.) Despite its age, Titan is still ranked number 7 on the June 2018 Top 500 list. On the High Performance Conjugate Gradients benchmark, which really stresses out supercomputers, Titan is rated at 322.32 teraflops against that sustained 17.59 petaflops rating on Linpack, or a mere 1.8 percent. And this is a pretty good HPCG rating, giving it number 11 position on the HPCG rankings. On the Green 500 list, which measures the energy efficiency of systems, however, Titan is ranked number 110, with only 2.143 gigaflops per watt running Linpack. The electric bill obsoletes machines faster than Moore’s Law improvements do. (They are, of course, coupled phenomena.)

That brings us to Summit. With Summit, the nodes are a lot fatter, with six GPUs per CPU, but more importantly, the GPUs are a lot denser, with the Volta GV100 GPUs deliver 80 streaming multiprocessors compared to 14 for the GK100 used in the Tesla K20X accelerator in Titan. As revealed three years ago with around 4,600 nodes – this was pretty close to what happened – Summit node was expected to have more than 40 teraflops of double precision compute, up from 1.4 teraflops with the CPU-GPU pair in the Titan. The Power9 chips used in Summit have 22 cores running at 3.1 GHz, and there are a pair of them in each node for a total of 202,752 cores across those 4,608 nodes. There are six Volta GPU accelerators on the machine, for a total of 2.21 million SMs. Add it all up, and there are 2.41 million “cores” as the Linpack folk count them in the Summit machine. That is a factor of 4.3X more concurrency compared to Titan. By the way, this node count is 35 percent higher than what IBM and DOE thought would be needed back in 2014, which is another way of saying that the double precision performance of the Power9 and Volta chips is lower than expected and it had to be made up by scaling out.
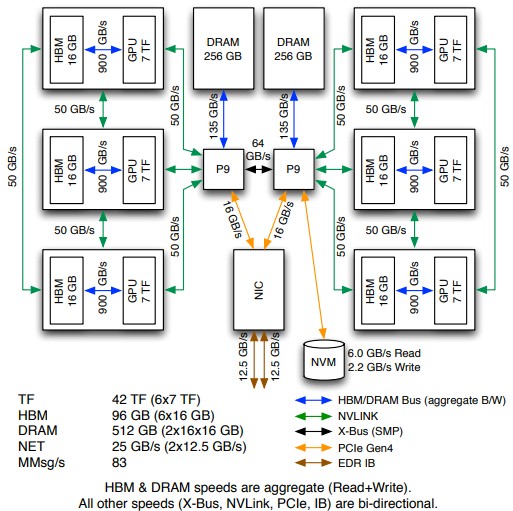
The idea with Summit was to have a lot of memory on the Power9 system and have coherency between it and the GPU memory, and the actual configuration on Summit is 512 GB of memory on the CPU side and 16 GB per accelerator on the GPU side for a total of 128 GB. There is another 800 GB of flash memory on the “Newell” Power AC922 nodes. The GPUs link to the CPUs directly with NVLink ports, which are faster than a PCI-Express switch would be. There is a dual rail, non-blocking fat tree network linking all of the nodes, and it was not clear if it would be 100 Gb/sec (with a node injection bandwidth of 23 GB/sec) or 200 Gb/sec (with a node injection bandwidth of 48 GB/sec), but due to timing issues, Oak Ridge went with the slower 100 Gb/sec EDR network. (There was a possibility that the 200 Gb/sec HDR network might be available.)
Summit has a 250 PB file system based on IBM’s Spectrum Scale (GPFS) and it has 2.5 PB/sec of bandwidth, an increase of 7.8X on capacity and 2.5X on bandwidth.
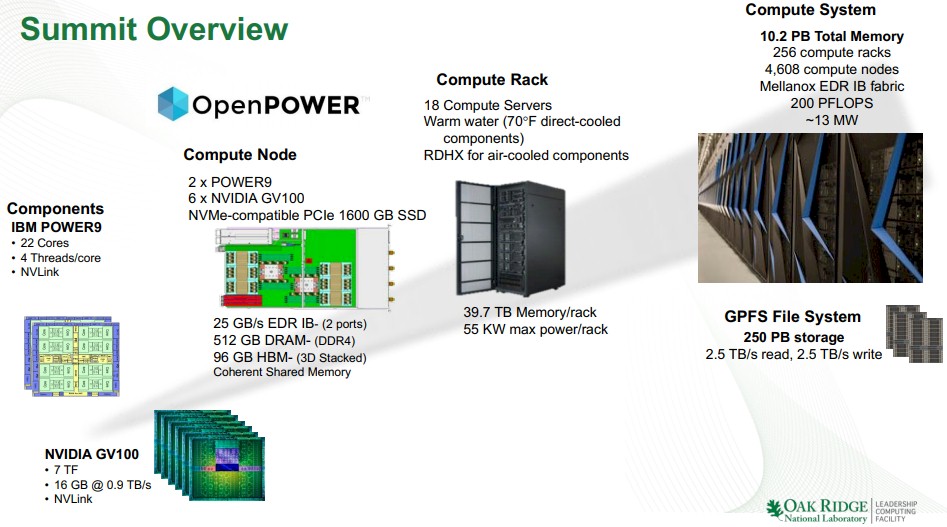
By racks, here is how Summit breaks down. There are 256 racks for compute in Summit, with 18 of the Power AC922 machine per rack and two Mellanox Switch-IB 2 switches in a rack, with power and water distribution units in there, too, for a total of 59 kilowatts per rack. There are 40 racks for storage, which includes four IBM ESS GLK4 storage servers, another 16 storage servers (we don’t know the details), and another 16 JBOD enclosures for 16.8 PB per rack at 30 kilowatts. There are 18 racks for networking, and four racks for cluster management. That’s 318 racks in total, and that is a behemoth by HPC standards. The big labs like to try to keep it all down to 200 racks if they can. But they can’t. The compute and storage density is not high enough and the thermal density is already too high.
Here are some thoughts about the networking on the Summit machine, since the IBM Power9 CPUs and Nvidia Volta GPUs often get a lot of attention. Our colleague, Paul Teich, was speaking to Craig Stunkel, principal research staff member at IBM’s TJ Watson Research Center, by email about the InfiniBand network in Summit, and he passed this information on to us. Stunkel is the network lead for the Summit and Sierra machines within IBM.
As we have pointed out in our analysis of the Power AC922 machine, the system has an on-board ConnectX-5 dual-port 100 Gb/sec network adapter, which links directly back to the Power9 processors with eight lanes each of PCI-Express. So it is one chip, but works like two dedicated adapters, one for each CPU. The top of rack switches have 36 ports and the switch has 7.2 Tb/sec (that’s bi-directional) switching capacity to deliver 100 Gb/sec to each port. These top of rack switches fan out and cross connect to a series of CS7500 director switches. Stunkel’s math is that there are 4,608 ConnectX-5 cards on the compute nodes plus 240 for the storage nodes, which is over 920 Tb/sec of bisection bandwidth on the entire Summit machine.
For the Linpack and HPCG tests, even though all 4,608 nodes have been installed, Oak Ridge only tested using 4,356 of the nodes. So if you were expecting to see the peak theoretical performance of Summit to kiss 200 petaflops, it does – but only if you use all of the nodes. No one has explained why 5.5 percent of the nodes were not used, but it drops it down to 191,664 Power9 cores and 2.09 million Volta SMs, which is where the 2.28 million cores figure in the Top 500 and HPCG rankings for June comes from.
The compute and networking portion of the full Summit machine comes in at an estimated 9.3 megawatts, with the full machine including the file system coming in at around the 13 megawatts than was expected when the system was designed. What this means is that if IBM had to build an exascale system for Oak Ridge today, it would cost about $1 billion (based on the estimated $200 million that the DOE paid for Summit) and it would burn about 46.6 megawatts for the compute and networking, and about 65 megawatts all in.
On the Linpack test, the 4,356 nodes of Summit is rated at 187.7 petaflops of peak theoretical performance and delivered 122.3 petaflops of sustained performance. If all the nodes were fired up, then Summit would be at 198.5 petaflops of oomph – close enough to 200 petaflops for government work – and would have 129.4 petaflops sustained. That is a factor of 7.3X more peak and sustained performance compared to Titan for the full Summit machine. Summit is not the most energy efficient supercomputer in the world, but at 13.889 gigaflops per watt it ranks number 5 on the Green 500 list and importantly it offers 6.5X better flops per watt than Titan. The Linpack and peak performance is scaling faster than the efficiency, but not outrageously so.
But here’s the real test. The portion of the Summit machine with 4,356 nodes was rated at 2.925 petaflops on the HPCG stress test, giving it the top spot on the list by a pretty fair margin compared to the K supercomputer at RIKEN lab in Japan, which has ruled the HPCG test from the beginning and is still, as we like to point out, an elegant machine that can do useful work. That is an efficiency as reckoned against sustained Linpack of 2.39 percent, which is alright. With all 4,608 nodes running HPCG, we estimate that it would hit 3.095 petaflops on the HPCG test with the same efficiency. That is a factor of 9.6X improvement over Titan.
This is, perhaps, the best indicator of performance improvements that Oak Ridge can expect to see on many of its HPC applications.
One last thing. With the advent of fatter memories on the Volta GPU accelerators and the NVSwitch used to create the DGX-2 system at Nvidia, and the prospect of having 200 Gb/sec networking at the node level, it is tempting to think how Summit might have looked had these technologies been brought to bear. But a machine is priced and designed and built at a given time, and technology advances and the latest-greatest thing can’t be put into the machines. So it goes. But it is interesting to think how NVSwitch might be used to make even fatter nodes in the future Frontier exascale system at Oak Ridge, and what maybe 400 Gb/sec or even 800 Gb/sec InfiniBand coupled with Power10 processors might be capable of. It had better be at least a 5X jump in performance with a 2.5X or less increase in power consumption.


Mellanox Doubles Up Ethernet Bandwidth With Spectrum-3
The relentless need for bandwidth is probably something that all of us are well aware of these days in our home lives thanks to the coronavirus outbreak. Now we can all appreciate at a fundamental level what it feels like in the datacenter most days, and why Ethernet switch ASIC …
Everyone Is Chasing What Nvidia Already Has
Transitions in the datacenter take time. It took Unix servers a decade, from 1985 through 1995, to supplant proprietary minicomputers and a lot of mainframe capacity that would have otherwise been bought. And from 1996 through 2001 or so, Sun Microsystems servers set the pace and reaped the profits, although …
The Local Maxima Ascension Of Datacenter At Nvidia
When we said thirteen weeks ago that we thought that Nvidia’s datacenter business would be its largest operating division before too long, we didn’t think it would only take a quarter to do that. But, as the gamers are awaiting the next-generation GPUs to power their ever-more-lifelike experiences and as …
Be the first to comment