

If the ecosystem for Arm processors is going to grow in the HPC arena, as many think it can, then someone has to make the initial investments in prototype hardware and help cultivate the software stack that will run on current and future Arm platforms.
Sandia National Laboratories, which has done its share of innovating in the supercomputer arena, has been investing in prototype Arm machinery for the past seven years and is taking it up another notch with a 2.3 petaflops pre-production system called “Astra” that is part of its Vanguard project to help create an exascale-class Arm machine that can be delivered after 2022 and be an option for future Advanced Technology System (ATS) supercomputers, which help manage the stockpile of nuclear weapons for the US military under the auspices of the Department of Energy.
The Astra system is the fourth experimental cluster based on the Arm architecture that Sandia has put together, and it represents a bit of a change in the roadmaps that Sandia is steering by as it tries to put Arm processors in a future exascale system.
In the original roadmap, which we divulged last September, a small pre-Vanguard early access machine was supposed to be installed during the fiscal 2018 year (that means before July 1 to the US government). Take a look:
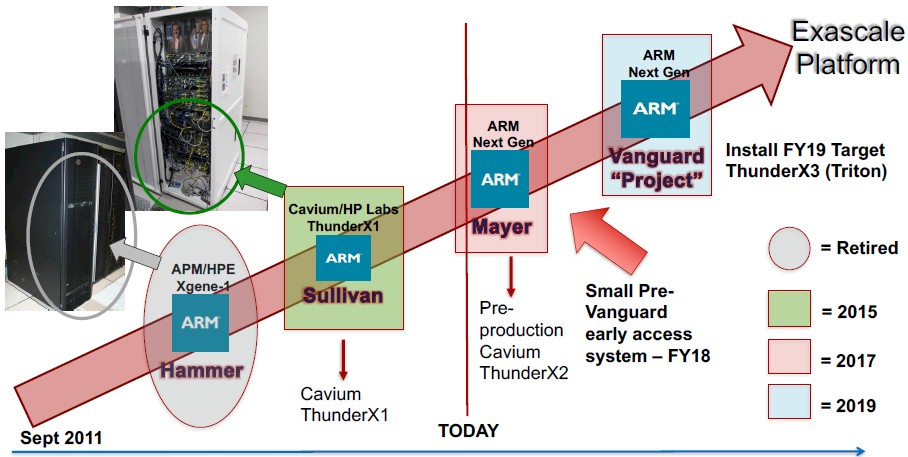
With the maturation of the “Vulcan” ThunderX2 chip from Cavium, it looks like Sandia is confident enough to skip an interim step and get the first Vanguard machine into the field this fiscal year rather than next year. See below:
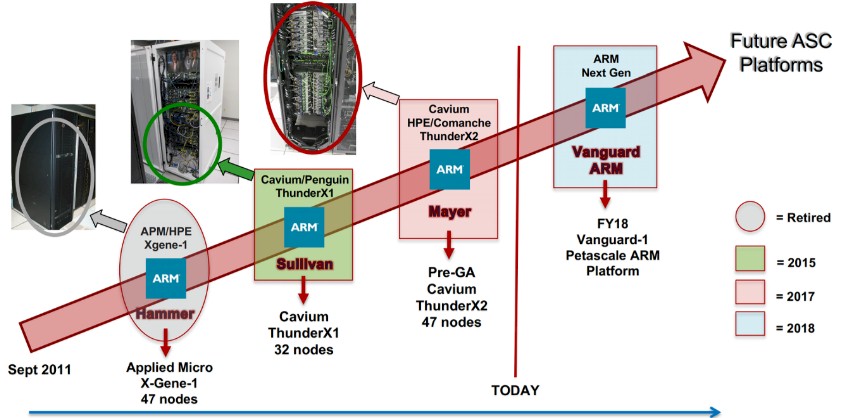
Sandia is using the “Comanche” server boards from HPE for its Apollo 70 clustered system as the basis of that box, which we now know is called Astra, which is the same platform that it used based on pre-production ThunderX2 silicon in a much smaller 47 node machine named “Mayer” that was built by Cavium and HPE last year.
As you can see, Sandia has tried a number of different kinds of machines since it first installed the “Hammer” system back in September 2011 as part of the DOE’s Advanced Simulation and Computing (ASC) program that has underwritten much of the research and development on processors and systems for decades. Cavium was by no means a shoe-in for the Astra bid, and in fact, says Mike Vildibill, vice president of the Advanced Technology Group at HPE, the Astra deal was a competitive bid with open processor choices – so long as they were based on the Arm instruction set, which is the purpose of the Vanguard project.
The Hammer system consisted of 47 nodes, too, and was based on the “Storm” X-Gene 1 processors, which was commission from Applied Micro (now part of a new company, funded by private equity firm The Carlyle Group, called Ampere) and Hewlett Packard Enterprise and using a 10 Gb/sec Ethernet interconnect between the nodes. Hammer looks like a custom blade server chassis based on HPE’s C-Class frames. It was neither a big nor powerful machine, but a testbed.
When Applied Micro started slipping on its roadmap, Sandia switched out to ThunderX1 processors from Cavium and created the “Sullivan” system in conjunction with Penguin Computing, which is correctly identified in the second roadmap but not in the first one. This Sullivan cluster had a mere 32 nodes, but it was enough to test out some of the HPC stack that was evolving pretty rapidly on Arm server chips.
If you look at the old roadmap, it looks like the first Vanguard machine – which would have meant Astra we presume – was supposed to come out in fiscal 2019 and, importantly, was to be based on the future “Triton” ThunderX3 processor from Cavium. For whatever reason, Sandia does not want to wait until next year and it does not want to wait for ThunderX3. And thus, Astra is built on the ThunderX2 processor that is ramping now and on the Apollo 70 system that, technically speaking, will not even be generally available until later this year.
According to Vildibill, the Astra system is comprised of 2,592 two-socket Comanche nodes, and four nodes can be crammed into a 2U enclosure. The Astra machine is based on the 28 core variant of the ThunderX2 processor that runs at 2 GHz. (See our overview of the Vulcan ThunderX2 chips for a complete SKU stack.) The original and remaining 54 core ThunderX2 chip, which we do not know the code name of and which has only six memory channels like Intel’s “Skylake” Xeons, is aimed at heavily threaded workloads has not yet been announced.
“Cavium does make parts with higher core counts and faster parts than this 28 core, 2 GHz chip, but we decided on this part for this implementation because it was a good fit to meet price, performance, price/performance, and bandwidth requirements,” Vildibill tells The Next Platform. “It is a kind of goldilocks SKU for this deployment.”

This probably means other shops looking at ThunderX2 nodes for their HPC workloads should probably pay attention to what Sandia is doing. The system has over 2.3 petaflops of peak double precision performance across its 145,152 cores. You could take the top bin Vulcan ThunderX2 part which has 32 cores running at 2.5 GHz and get the same 2.3 petaflops at double precision. But these chips run at 200 watts and cost a little under $3,000 a pop. We don’t know the price or thermals of this middle bin SKU running at 2 GHz with 28 cores, but it is, based on the thin information we have, probably a 140 watt part that costs somewhere around $1,500. That’s around half the price and 30 percent lower power for the CPU. It takes 43 percent more nodes to do the job, but as best we can figure, the performance per watt comparing this top bin and middle bin part are dead even at the CPU level. By having more nodes, you have more memory slots per core, and therefore the potential for more memory capacity and more memory bandwidth per core on the Astra system that Sandia actually picked over a top bin configuration.
Our point is, the fastest part with the high clocks and the most cores is not always the right choice. It usually is never the right choice, unless the workload is dominated by clock speed and core count per box – like, say, a search engine is.
The nodes in the Astra cluster have just under 330 TB of DDR4 main memory (128 GB per node) and all told they have over 800 TB/sec of aggregate memory bandwidth. This is 33 percent more memory bandwidth than you can get out of the top SKUs of Intel’s “Skylake” Xeon SP processors. In terms of SPEC CPU ratings, Cavium suggests that the part used in Astra is most like Intel’s 14 core Xeon SP-6132 Gold processor, which runs at 2.6 GHz, which is rated at 140 watts, and which costs $2,111. That is about 40 percent more dough for the same oomph at the same thermals at the CPU level. Of course, raw performance is not the same thing as tuned performance on actual workloads, and even Cavium has conceded that there is about a 15 percent performance gap on raw integer and floating point jobs comparing the open source GCC compilers on Vulcan ThunderX2 versus the Intel compilers on Skylake Xeons. But Cavium and Arm Holdings and labs like Sandia are working to close that gap – and we think they will.
The Astra cluster also includes an all-flash Lustre parallel file system that is based on HPE’s Apollo 4250 storage server nodes, which launched back in April 2016. The Lustre servers are hooked onto the same 100 Gb/sec EDR InfiniBand interconnect from Mellanox Technologies as is used to lash the compute nodes together. This Lustre cluster is almost akin to a burst buffer, according to Vildibill, who knows a thing or two about this given his prior job at HPC storage vendor DataDirect Networks. This Lustre array has 350 TB of flash capacity and delivers 250 GB/sec of bandwidth, allowing for the rapid movement of data into and out of the Arm compute cluster. (The original Apollo 4250 storage servers were based on two-socket “Broadwell” Xeon nodes, and it is unclear if these have been replaced by ThunderX2 processors – but clearly, for the Vanguard project that is championing Arm chips, they should be changed out. Lustre does, by the way, run on Arm chips.
That InfiniBand network is a little bit different on the compute than it is on the Lustre file servers. It is a single rail network on the compute, and the oversubscription level is set at 2:1. For the Lustre storage, the InfiniBand is a full fat tree with non-blocking access and no oversubscription so nodes can rip straight to the data.
In addition to the servers, HPE is adding a few extra goodies to the Astra system. Firstgiven the compute density of the Apollo 70 systems, the 37 racks in the Astra system are equipped with Modular Colling System 300 series rack cooling systems, which has not yet been announced as far as we know. (The MCS 200 series is a rack with a water jacket that can cool up to 55 kilowatts of gear; we wonder what the MCS 300 series can do.) HPE is also cooking up its own MPI stack for loosely coupling the memory on the nodes to run parallel workloads and has its own Performance Cluster Manager, both of which come from its acquisition of SGI two years back.
If this Astra machine were ranked on the Top 500 supercomputer list today, it would be somewhere around number 63 and will no doubt be the most powerful Arm machine in the world for at least a while.


Throwing Down The Gauntlet To CPU Incumbents
The server processor market has gotten a lot more crowded in the past several years, which is great for customers and which has made it both better and tougher for those that are trying to compete with industry juggernaut Intel. And it looks like it is going to be getting …
HPE Builds Out GreenLake Utility, Creates Ezmeral Software
Hewlett Packard Enterprise in January created its Transformation Office with an eye toward accelerating its move to become a platform provider – complete with hardware, software, services and other components – with a reach from the datacenter out through the cloud and to the fast-growing edge computing environment. This was …

The Mystery Of Tianhe-3, The World’s Fastest Supercomputer, Solved?
We don’t like a mystery and we particularly don’t like it when what is very likely the most powerful supercomputer in the world – at this time anyway – is veiled in secrecy. But that is what the Tianhe-3 supercomputer built for the National Supercomputer Center in Guangzhou, China has …
Be the first to comment