

If the hyperscalers have taught us anything, it is that more data is always better. And because of this, we have to start out by saying that we are grateful to the researchers who created and administer the Top 500 supercomputer benchmark tests for the past 25 years, creating an astonishing 50 consecutive lists ranking the most powerful machines in the world as gauged by the double precision Linpack Fortran parallel matrix math test.
This set of data stands out among a few other groups of benchmarks that have been used by the tens of thousands of organizations – academic supercomputing centers, government agencies, large enterprises, IT vendors, and an increasing number of cloud builders and hyperscalers – that engage in traditional simulation and modeling in science and finance as well as an increasing number of data analytics and machine learning workloads that, not precisely coincidentally, also tend to run on similar computing architectures these days. Linpack, as embodied by the Top 500 rankings, stands tall with the SPEC processor benchmarks, the SAP set of commercial application benchmarks, the TPC transaction processing and data warehousing benchmarks, and the STREAM memory bandwidth benchmarks as the key tools that the core several tens of thousands of organizations that sit on the leading and bleeding edge of distributed and NUMA processing have used to try to reckon the relative performance of systems.
That gauging function should always be the point of such benchmarks, but the Top 500 has been used in other ways in recent years, with many machines that have nothing at all to do with distributed technical computing running Linpack to boost a vendor’s profile on the list, or for nationalistic reasons as one country tries to boost its standing against others. Moreover, many machines that are among the most powerful systems in the world, whether they are classified or known, such as the “Blue Waters” system at the University of Illinois, are for their own reasons do not have official Linpack results submitted for them and therefore they are not part of the conversation. And therefore, they are not part of the Top 500 data set and they are not helping further our understanding of the performance and scale of specific computing, networking, and memory architectures. And that is wrong.
But the Top 500 list is a voluntary one. We can’t compel people to run it if they don’t want to, and of necessity, the Top 500 organizers have to take the data they can get. We actually have no idea how much money is spent and how many systems are built in black ops budgets all over the world on supercomputing, and how many tens or hundreds of petaflops are embodied by that money. It is with this in mind that we examine the November 2017 Top 500 rankings, and a list that has been pumped up with Linpack results on many machines that we believe have little to do with double precision floating point math used in production or traditional HPC as we know it.
So we have machines that should be on the list that are not, and machines that should not be on the list that are, and this is not a good thing for a list that cuts off at 500 machines in a world where maybe somewhere around two orders of magnitude of machines running at scale exist. We will be examining this problem in another follow-up story, but we needed to point this out before jumping into the stats on the current list. We are aware of the issues with the Top 500 data, which has lots of precision, but which may not accurately reflect what is actually happening with traditional HPC systems.
Where the list does still do an admirable job is in collecting and compiling information of the largest government and academic supercomputers. Generally speaking, as a rule of thumb, if it has a nick-name and we know it publicly, and if it is near the top of the Top 500 list, then it is very likely a real supercomputer.
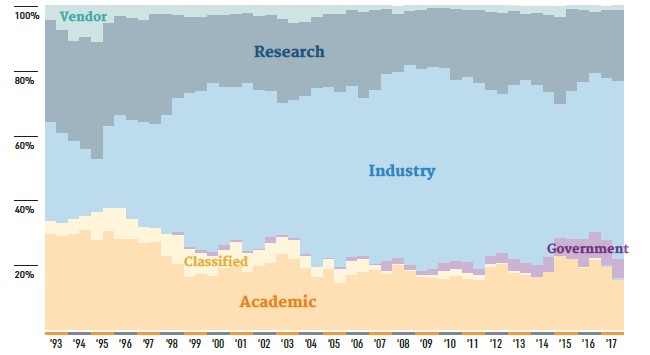
In the November 2017 rankings, much will be made of China finally surpassing the United States as the dominant nation represented on the list. Inasmuch as this might spur a rapid response for investment in supercomputing in the United States, we suppose this is a good thing, but it is utterly ridiculous to suggest for even a nanosecond that the United States has less computing power than China. With millions of servers each, Google, Facebook, Microsoft, and Amazon could, if they felt like it, carve their entire server fleets up into 10,000-node instances and run Linpack on them and easily aggregate into them into something on the order of 2,500 exaflops to maybe 3,000 exaflops of double precision oomph. (We are not even counting the GPU that these companies have, which might be a few exaflops more.) We can carve the hyperscalers into machines that have 15,000 nodes each, and they will be rated at around 15 petaflops running Linpack. So anything that is not in the top six on the current November ranking would be slid off the list. And there would be another 532 machines in a row from Google, Amazon, Microsoft, and Facebook behind them, knocking every other machine off the current Top 500. And every week, collectively they can add one or two more of these clusters. Plunk. Plunk. Plunk. . . .
To be fair, there will be a day when Alibaba, Baidu, Tencent, and China Mobile will rival the compute capacity of the hyperscalers and cloud builders in the United States – which stands to reason given the relative populations of these two countries and their economic spheres of influence. But that day is not today, and it will not be for many years to come.
Our point is that Linpack rankings should be for traditional HPC and maybe financial systems modeling, and maybe for hybrid machines that are doing some analytics or machine learning. But not just any old machine that ran the test. A whole bunch of real HPC machines, some with GPU accelerators, some without, were knocked off the list by the invasion of the telcos and service providers, which are by and large running virtual network infrastructure on their clusters.
We are excited by real HPC, and the new machines that are on the current list and that, like the “Summit” and “Sierra” machines being built by IBM for the US Department of Energy, that are right around the corner, perhaps by the June 2018 list. So let’s take a look at some of the real HPC machines on this important ranking.
Stacking Them Up
The top three machines on the list are the same, but number four is very interesting indeed and a serious upgrade of a machine that was one of the most energy efficient ones on the June 2017 list.
The top end machine, now for the fourth Top 500 listing in a row, is the Sunway TaihuLight massively parallel system installed at the National Supercomputing Center in Wuxi, China. This machine has a whopping 10.65 million cores based on the homegrown SW26010 processor, which delivers 125.4 petaflops of peak theoretical performance and 93 petaflops on the Linpack benchmark. The Tianhe-2 system installed at the National Super Computer Center in Guangzhou, China is, once again, ranked second, with its mixture of Xeon CPUs and Xeon Phi accelerator cards delivering 3.12 million cores that have a peak speed of 54.9 petaflops and deliver 33.86 petaflops of sustained performance running Linpack. The Piz Daint system at the Swiss National Supercomputing Center comes in third, again, and is a Cray XC50 machine based on the “Aries” XC interconnect with a mix of compute nodes based on Intel’s twelve-core “Haswell” Xeon E5-2690 v3 processors with Nvidia’s Tesla P100 accelerators using the “Pascal” GP100 GPUs. This machine has 361,760 compute elements, which includes the Xeon sockets and the individual streaming multiprocessors (SMs) on the GPUs, which have dozens of CUDA cores each. This system has a peak performance of 25.3 petaflops and delivers 19.6 petaflops on Linpack.
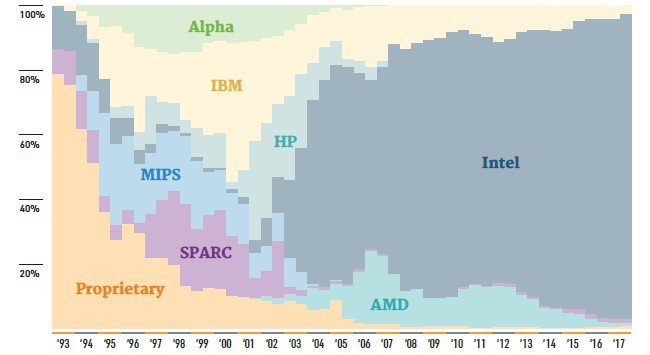
Number four on the November ranking is a hybrid system installed at the Japan Agency for Marine-Earth Science and Technology, which is where the original Earth Simulator, a massively parallel vector system made by NEC, reigned at the top of the supercomputer rankings in the early 2000s. As we have previously reported, NEC has created a vector coprocessor for its latest “Aurora” SX10+ Tsubasa system, which will be unveiled this week at the SC17 supercomputing conference in Denver. You would think that JAMSTEC would be a natural candidate for the Tsubasa iron, and it may eventually invest in such a machine, but for this year, the organization has contracted with liquid cooling expert ExaScaler and floating point coprocessor maker PEZY Computing to create the Gyoukou system. This machine makes use of the 16-core, 1.3 GHz Xeon D-1571 – the low-end chip created by Intel predominantly for Facebook to stop interest in Arm server chips – as the serial compute and uses a geared down PEZY-SC2 floating point PCI-Express coprocessor card for the parallel math. This processor has 2,048 cores running at 700 MHz, which is 30 percent slower than the 1 GHz rated speed for this 16 nanometer chip. All told, the Gyoukou machine has more than 19.9 million cores, which is the largest amount of concurrency ever managed to run Linpack before, and nearly twice what is done on the TaihuLight system. This JAMSTEC system has a total of 29.2 petaflops of peak performance and delivers 19.1 petaflops running Linpack. This is a 68.9 percent computational efficiency, and with 100 Gb/sec EDR InfiniBand linking the nodes, the Gyoukou system is probably not bandwidth constrained and is delivering 14.1 gigaflops per watt.
By the way, just to show you how technology advances, the Titan system at Oak Ridge National Laboratory, which was the fastest system in the word in the early 2010s, is a mix of 16-core Opteron processors from AMD and Tesla K20X GPU accelerators with nodes linked by Cray’s older generation “Gemini” XT interconnect. This system, which is still ranked number five on the list, has a peak theoretical performance of 27.1 petaflops and delivers 17.6 petaflops on Linpack, for a 64.9 percent computational efficiency. The big difference is that Titan burned 8.21 megawatts, delivering 2.1 gigaflops per watt. The Gyoukou system is 6.6X more energy efficient, at least running Linpack – and it does not rely on GPUs. It will be interesting to see how the new NEC SX-10+ vector motor, which could also find a home at JAMSTEC, will match up.
The remaining machines in the top ten of the Top 500 are familiar and have been on the list for a year or more, and some are getting quite long in the tooth but are still doing good work. These include, in descending order, the 17.1 petaflops Sequoia BlueGene/Q PowerPC CPU system at Lawrence Livermore National Laboratory, the 14.1 petaflops Trinity Cray XC40 Xeon Phi system at Los Alamos National Laboratory, the 14 petaflops Cori Cray XC40 hybrid Xeon-Xeon Phi machine at Lawrence Berkeley National Laboratory, the 13.6 petaflops Oakforest-PACS Fujitsu Xeon Phi machine at the Joint Center for Advanced High Performance Computing in Japan, and finally the venerable and still remarkable 10.5 petaflops K Fujitsu Sparc64 system at the RIKEN lab in Japan.
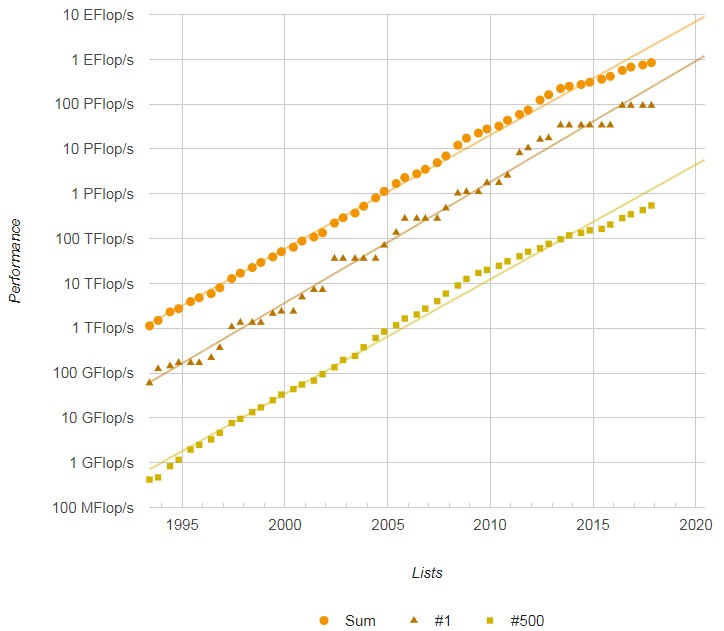
To get on the Top 500 list this time around, a system had to have at least 548 teraflops of aggregate sustained performance, up 27 percent from only six months ago in the June list, when the entry point was 432 teraflops. (That is, again, a double precision floating point rating.) The upper fifth Top 100 portion of the list is fairly stable in in terms of performance, with the entry point being 1.28 petaflops, up a tiny bit from 1.21 petaflops in June. This will change when a slew of new capability-class supercomputers come into play in 2018, but it would have been even higher had the “Aurora” parallel Knights Hill/Omni-Path-2 system proposed by Intel, which has been canceled in lieu of an exascale machine due in 2021, come to fruition with its 180 petaflops. While one could complain about the many machines that are not traditional HPC systems that are on the list, they are pumping up the numbers and bending the aggregate performance curves to keep them closer to the historical curves, so there is that. The November list had an aggregate of 845 petaflops of floating point oomph, up 12.8 percent from the 749 aggregate petaflops in the June list and up 25.7 percent from the 672 petaflops in the year-ago list.
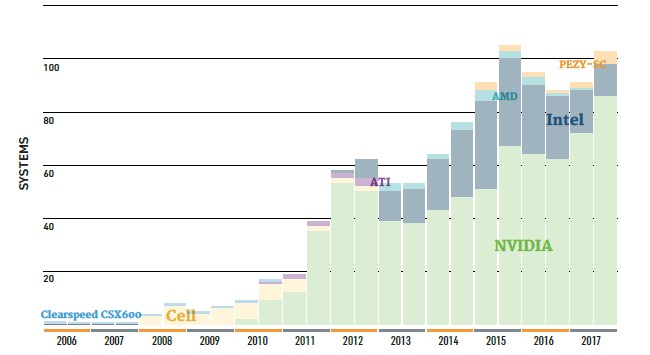
The interesting thing to track with each Top 500 list is how many are using a compute offload to accelerators. This time around, there are 101 accelerated systems on the list, with Nvidia’s various Tesla GPU accelerators being on 86 of these systems and accounting for an aggregate of 146 petaflops of double precision number crunching power. That’s 33 new systems, but a whole bunch fell off the list thanks to the influx of the telco and service provider clusters, which bulk up the middle section of the list. The five machines using the PEZY floating point accelerators comprise another 21.4 petaflops, and there are another dozen systems that use Intel’s Xeon Phi massively parallel motors as coprocessors and two use a combination of Xeon Phi and Tesla accelerators. There are another 14 machines on the list that use Xeon Phi chips as their only hosted processors, and while these are not technically accelerators, they help boost that massively parallel architecture and they do take work that might otherwise go on Xeons. It is hard to reckon how much performance, in aggregate, the Xeon Phis are providing in these hybrid machines without doing a lot of math, but suffice it to say that the 101 systems on the list using these architectures have a much larger proportion of the overall performance represented on the November list, which is precisely one of the points of using accelerators.
Much will be made of the geographic distribution of the machines on the Top 500 list, and if this leads to actual concern about increasing investments in actual HPC, then we suppose that is a good thing. But if it just leads to more Linpack tests being run on machines that are not actually doing HPC, this is obviously not ideal. In any event, China is now top gun on the Top 500, with 202 systems, up from 160 on the June list, and the United States now has only 143 systems, down from 169 in June. There are now 251 systems that are located in Asia, up from 210 six months ago, with 35 of these in Japan. Europe has 93 systems across the region, down from 106 in June. Germany has 21 of these, followed by France with 18 and the United Kingdom with 15.


Real-World HPC Gets the Benchmark It Deserves
While nothing can beat the notoriety of the long-standing LINPACK benchmark, the metric by which supercomputer performance is gauged, there is ample room for a more practical measure. It might not garner the same mainstream headlines as the Top 500 list of the world’s largest systems, but a new benchmark …

Dennard Scaling Demise Puts Permanent Dent in Supercomputing
When the TOP500 list of the world’s most powerful supercomputers comes out twice a year, the top-ranked machines receive the lion’s share of attention. It is, after all, where the competition is most intense. But if people had given more scrutiny to the bottom of the list, they would have …
The Widening Gyre Of Supercomputing
The twice-annual ranking of distributed computing systems based on the Linpack parallel Fortran benchmark, a widely used and sometimes maligned test, is as much a history lesson as it is an expectation always looking forward, with anticipation, to the next performance milestones in high performance computing. As we have pointed …
I am interested in three “accuracy” of these computers, especially the “Earth Simulator”. It was started they would predict ocean temperatures over the next 50 yrs. Now that some time has gone by, how did they do?
Good question. I don’t have an answer, but a good story to chase. I think that things are always harder than they look.