
The big oil and gas companies of the world were among the earliest and most enthusiastic users of advanced machinery to do HPC simulation and modeling. The reason for these decades of experimentation and investment was simple: If you can figure out where the oil and gas is – and where it is not – you can avoid wasting a huge amount of money and increase the odds of making a whole lot more money than you might otherwise.
While the oil and gas majors all obviously have relatively large HPC systems – and usually more than one, like the national labs tend to – Eni, formerly known as Ente Nazionale Idrocarburi and the Italian energy major that employs over 32,000 people and operates in 62rento countries worldwide, is one that is public about its HPC investments. The energy company has an oil, gas, and electricity generation and distribution business as well as chemical refining operations, and has made substantial investments in supercomputers in the past decade that we have been keeping a careful eye on Eni, as the company is known.
And this week, Eni is making big investments once again as it has commissioned Hewlett Packard Enterprise and AMD to build its HPC6 system for its Green Data Center in Ferrera Erbognone southwest of Milan, not far from the Po River and a place that Nicole and I would absolutely love to visit.
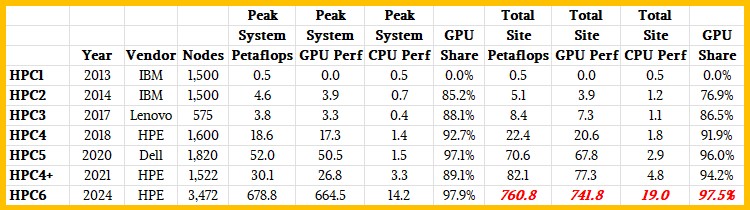
To cut to the chase scene a bit, here is a table we have built to show the HPC systems installed in the Green Data Center by Eni between 2013 and 2024:
Eni has put together a retrospective on its HPC history at this link if you want to go back into the 1960s.
Over that time, Eni has expanded the capacity of its flagship system by a factor of 1,360X, which is a pretty good jump for a commercial enterprise when it comes to HPC investments. We detailed the HPC1, HPC2, HPC3, and HPC4 systems when the HPC4 deal was inked in 2018 with HPE, which was before HPE bought Cray and had access to its interconnects and system designs. IBM built the HPC1 and HPC2 systems, and after Lenovo bought the System x server business from Big Blue in late 2014, Lenovo picked up the contract to build the in 2017. HPC1 was a CPU-only machine, and since HPC2, Eni has had hybrid CPU-GPU systems where the bulk of the computational oomph of the machines come from GPUs but the machines have enough compute power to run CPU-only codes at reasonable scale if that is necessary.
In 2020, Dell got a deal to build the 52 petaflops HPC5 machine for Eni, and in 2021, during the coronavirus pandemic, Eni approached HPE to do a system swap upgrade to the HPC4 system, surprising creating a new HPC4+ machine in 2021 – one with GreenLake-style utility pricing for the compute and storage, which seems only fitting for a utility company. . . . You would have expected for Eni to install HPC6 at that time, not upgrade its N-1 system. But it looks like Eni was waiting for the GPU Wars to heat up a bit and for Nvidia and AMD and possibly Intel to be able to all bid on what would become its HPC6 system. And as we said at the time, we think HPC4+ was a stopgap machine designed to be aggressively priced using N-1 technology from the GPU makers.
Ditto for the HPC5+ system that Dell also built in 2022 and that we did not know about until two weeks after this HPC6 story was published. We have updated our Eni HPC historical table to reflect this formerly unknown HPC5+ machine. We don’t know much about it except for the feeds and speeds in the table above.
Eni was on the cutting edge among oil and gas majors to adopt GPU acceleration for its reservoir modeling and seismic analysis workloads, and for in November 2021 Eni formed a strategic partnership with Stone Ridge Technology to adopt the latter’s ECHELON dynamic reservoir simulator into a full-featured simulator for the oil and gas giants – all based, of course, on GPU acceleration. You can see Eni’s hunger for GPUs growing over the past several years, and we strongly suspect that it is now getting ready to deploy the much-expanded ECHELON software in production and thus the step function increase in GPU acceleration with the HPC6 system that will be installed this year – and hopefully by the Top500 list that comes out in June concurrent with the ISC24 supercomputing conference.

There is no good reason why HPC6 should not be installed fairly quickly, considering it is more or less 37 percent of the 1.68 exaflops “Frontier” supercomputer that has been installed more than two years ago at Oak Ridge National Laboratory in the United States.
To be precise, the HPC6 system is based on the HPE Cray EX4000 liquid cooled enclosures, which use the Cray EX235a blade servers. The HPC6 system has 28 such racks, which hold 128 nodes in total. That 28th rack only has 16 nodes in it, so there are a total of 3,472 nodes in the HPC6 system. Each node has a 64-core AMD processor, which is the custom “Trento” chip created by AMD specifically for Frontier, which runs at only 2 GHz and which runs at a lot lower power than a standard 64-core “Milan” or “Genoa” part. But, for all we know, Eni is getting a standard Genoa part that has the Infinity Fabric 4.0 ports on it to talk coherently with the AMD GPUs in the system. Eni was not specific.
The GPU compute motors in the HPC6 system are not the just-announced “Antares” MI300X accelerators, but rather the prior generation “Aldebaran” MI250X GPUs that are used in Frontier. This may seem like an odd choice given that the MI300X chips offer significant performance (and presumably some price/performance) advantages. But it is fairly likely that all of the MI300X devices that AMD can have made are already allocated for distribution this year (mostly to the hyperscalers and cloud builders, and probably since the middle of last year) and similarly that Lawrence Livermore National Laboratory is getting nearly all of the MI300A hybrid CPU-GPU devices that AMD can have made. If AMD had a lot of MI250X processors in the barn, and they are priced at the same cost per flops as the MI300Xs, then it is a difference that only makes a difference in a tight space with thermal constraints.
You go to the AI War with the GPUs you can get, to paraphrase Donald Rumsfeld, former US Secretary of Defense.
In any event, the HPC6 system is using N-1 technology, just like the HPC4+ system did, and we think Eni would have hung back on purpose because it has to balance budget against energy efficiency against timing. While a large system in its own right, there are companies that want to buy between 20,000 and 50,000 GPUs right now, and who will pay top dollar for them as AI engines. HPC customers do not have those kinds of budgets, and it is reasonable to expect for those who are focused on FP64 and FP32 vector performance to hang back when they can because they do not necessarily need the AI features like FP8 and in the future FP4 reduced precision the same way the clouds and hyperscalers do.
Across those 3,472 nodes in the HPC6 system, there are 13,888 GPUs, which means the node has the same 1:4 CPU to GPU ratio as the Frontier system. But, as we have shown, it is really a 1:1 ratio if you look at the eight CPU chiplets inside the single Epyc socket and the four two-chiplet GPUs that are literally attached to each other in a one-to-one fashion. (Cray has always liked 1:1 pairings of CPUs and GPUs in its supercomputer designs.)
To link the nodes together, the HPC6 system will use Cray’s existing Slingshot 11 interconnect, which consists of the “Rosetta” switch, which has 64 extended Ethernet ports running at 200 Gb/sec, and the matching Cray “Cassini” ASICs on the network interface cards. Ethernet ASICs from Cisco Systems, Broadcom, and Marvell have four times the bandwidth (which means ports that can run 2X to 4X faster at higher or the same radix), but they do not have all of the HPC-centric network features that Cray has woven into the Slingshot interconnect – many of which work to accelerate AI workloads, too. We do not know the precise design of the Slingshot network that the HPC6 system is using, but it does have a dragonfly topology like the one inside of Frontier.
The announcement from Eni says that HPC6 will have a peak performance of over 600 petaflops and will have at least 400 petaflops of sustained performance on the High Performance LINPACK supercomputing benchmark test. When Eni does the math on the peak performance of the CPUs and GPUs in the HPC6 system, it says there is 625.8 petaflops of peak GPU oomph and 6.94 petaflops of peak CPU oomph, for a total of 67632.74 petaflops of combined peak oomph. The GPUs (and their HBM memory) represent 98.9 percent of the aggregate peak FP64 flops of the machine, and probably somewhere around 80 percent of the total cost of the system.
Here is how the HPC1 through HPC6 systems at Eni chart out in terms of their peak CPU and GPU petaflops over time:
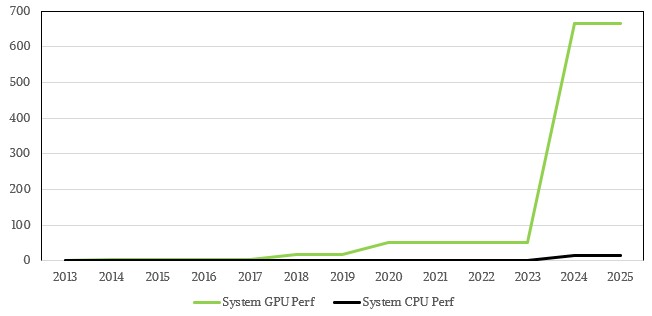
That is very hard to read on the CPU, but you get a good sense of the GPU jumps. Here is a log scale to show how CPU and GPU performance (in petaflops again) have tracked alongside each other in the HPC1 through HPC6 systems:
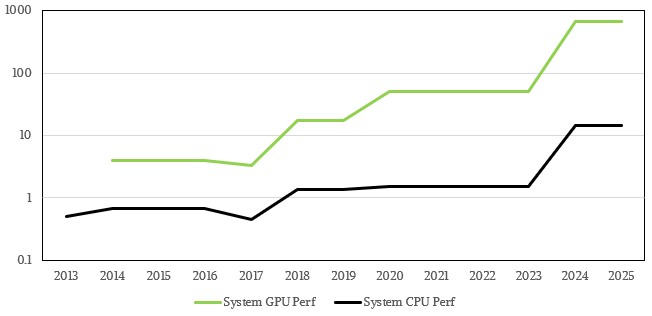
Eni says in its statement that the liquid cooling technology used with the HPC6 system will remove 96 percent of the heat generated by the system, which is going to make for a very nice heated pool somewhere and probably heating in the Eni offices. Eni also adds that the peak power load from the HPC6 system will be 10.17 MVA. Millions of volt-amps (MVA) is not the same thing as megawatts and is a gauge of the peak possible loading a device can handle, and we do not know at press time if Eni meant to say 10.17 MW or 10.17 MVA. In any event, the MVA rating is always larger than the MW rating, so if they really meant to say MVA, then the MW rating should be lower. Frontier is rated at 22.7 MW, and that would place HPC6 somewhere around 8.3 MW depending on the scale of the network and storage. So it looks like Eni meant to say MVA, but we all talk in real power consumed in MW when we talk about supercomputers. We think 8.3 MW will be pretty close.
It is hard to say what the HPC6 system cost, but we strongly suspect that Eni would not get the same kind of deal that Oak Ridge did. Oak Ridge paid $600 million for Frontier, which included $500 million for the system and $100 million for non-recurring engineering (NRE) costs. Cray told us back in 2019 that $50 million of that $500 million for the system was earmarked for storage, which consisted of an 11.5 PB flash tier, a 679 PB disk tier, and a 10 PB flash tier for metadata.
At the same cost per unit of FP64 compute, Eni would have to pay $185 million for HPC6, assuming it had a proportional amount of Cray ClusterStor E1000 “Orion” parallel file system disk and flash capacity attached to it, which is based on a mix of ZFS and Lustre file systems. The storage would be $18.5 million of that. Doing the math, that would be 250 TB of disk and 4.3 TB of flash plus another 3.7 TB of flash for metadata.
Now, Eni being a commercial customer, the energy giant would probably have to pay a premium compared to the Oak Ridge contract for Frontier, and historically, that multiple has been on the order of 1.5X to 2X. And in a market with GPU supply constraints and intense GPU demands, we think it is not unreasonable to think that Eni might have paid somewhere between $250 million and $300 million for the HPC6 machine. But, there is also a chance it paid as little as $175 million for it, too. We wonder if Eni got GreenLake pricing on the HPC6 system, and hope so because that will give us something interesting to talk to HPE about.
The HPC6 system will be installed sometime this year, Eni confirmed to The Next Platform, and also that the HPC4+ and HPC5+ systems would be decommissioned sometime in 2025. But until then, the Eni Green Data Center will at least for several months have a factor of 10.8X more FP64 oomph than it had two years ago. Remember, around 2X of that jump is the move from FP64 vector to FP64 matrix math on the GPUs.


The Interesting Years Ahead For Servers
By every measure we can get our hands on, 2022 was a bumper year for server shipments and server spending, which is good indicator for the appetite for new kinds of applications and the expansion of existing applications in the world at large. But what is going to happen this …

HPE Uses AI To Drive The Business, Which Is Increasingly AI
Hewlett Packard Enterprise is going through yet another restructuring to reduce costs, something we have seen a lot of in the past two decades and a half decades since it acquired Compaq to become a volume server peddler as well as high end system supplier for enterprises. But this time …
Accelerated Databases In The Fast Lane
Hardware accelerated databases are not new things. More than twenty years ago, Netezza was founded and created a hybrid hardware architecture that ran PostgreSQL on a big, wonking NUMA server running Linux and accelerated certain functions with adjunct accelerators that were themselves hybrid CPU-FPGA server blades that also stored the …
Timothy, the EX4000 is the cabinet and the EX235a is the blade:
https://www.hpe.com/psnow/doc/a00094635enw.html
Of course it is….