

There was an outside chance that China might pull a surprise on the HPC community and launch the first true exascale system – meaning capable of more than 1 exaflops of peak theoretical 64-bit floating point performance if you want to be generous, and 1 exaflops sustained on the High Performance Linpack (HPL) benchmark if you don’t – but that didn’t happen. And so, we wait.
There was a reasonable amount of churn on the semi-annual Top500 ranking of supercomputers, the June list of which was divulged at the International Supercomputing (ISC) conference as is tradition. ISC21 was hosted online, however, rather than in Germany, and like many of you, we miss traveling to see colleagues and friends – and even competitors – and hope that this coronavirus pandemic will not have a resurgence in the fall with the Delta variant. We shall see, or more precisely, the supercomputers of the world will help us see. If there is any good that comes out of this, it is that the value of supercomputing has been shown to the world. So there is that, and in the long run, this is what is actually important. But we still miss that German breakfast. . . .
The new machine at the top of the Top500 list is the “Perlmutter” pre-exascale system at Lawrence Berkeley National Laboratory, which is a Cray EX system from Hewlett Packard Enterprise that we detailed last month. Perlmutter is interesting in that it mixes AMD CPUs with Nvidia GPU accelerators and an HPE Cray Slingshot interconnect between the nodes. This machine was installed in phases. In Phase 1, the 1,500 nodes in a dozen cabinets had a single 64-core “Milan” Epyc 7763 processor running at 2.45 GHz with 256 GB of memory and four Nvidia “Ampere” A100 GPU accelerators with 40 GB of HBM2E memory, for a total of 6,000 GPUs. In Phase 2, another dozen cabinets were installed that had 3,000 all-GPU nodes with a pair of the 64-core Milan Epyc 7763 processors.
Add up all of the compute elements in Perlmutter – that is the Epyc cores and the Ampere streaming multiprocessors – and you have 706,304 “cores” and a total power draw of 2.53 megawatts, and Perlmutter has a peak theoretical performance of 89.75 petaflops and delivers 64.59 petaflops of performance on the Linpack test. That’s a computational efficiency of just a hair under 72 percent. This ain’t too shabby, which must make Erich Strohmaier, one of the co-founders of the Top500 list who retired from the Berkeley Lab last summer who is still maintaining the Top500 list, quite happy. That’s Strohmaier at the bottom of the summary chart below that shows the Green500 supercomputer efficiency rankings along with the Top500 performance rankings for the same machines:
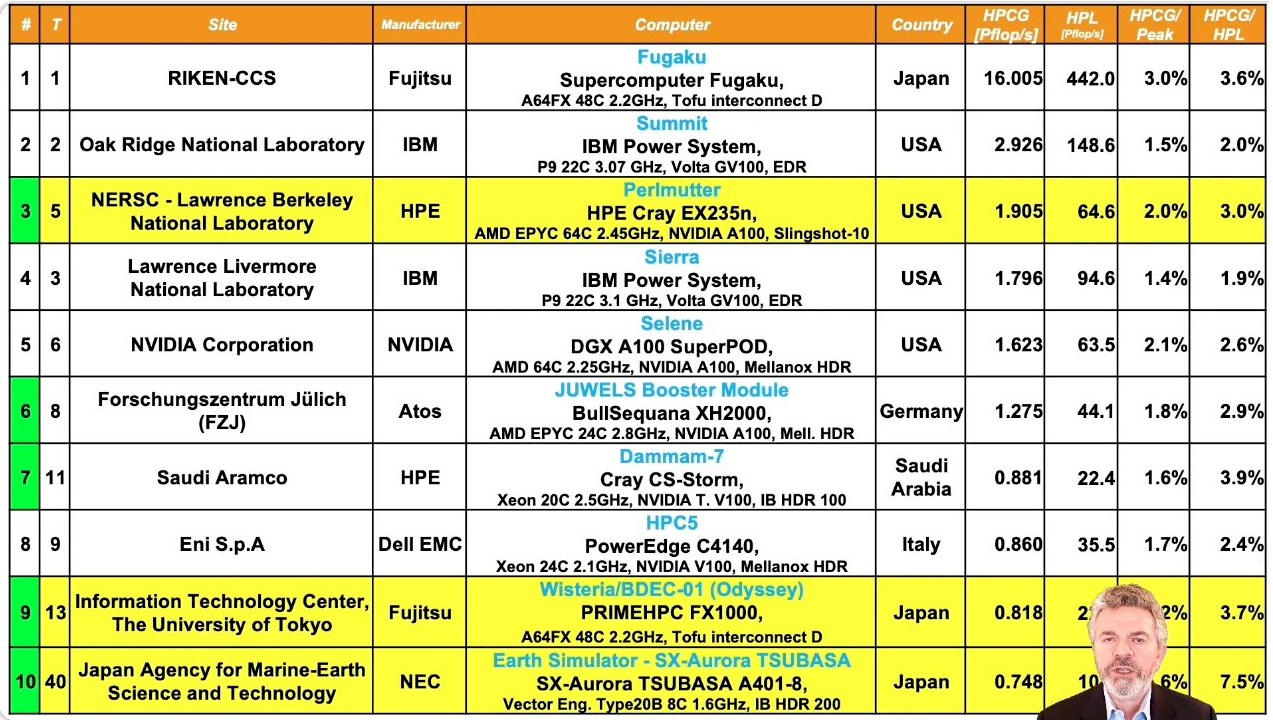
In terms of performance, Perlmutter slides in underneath the Sunway “TaihuLight” system at the National Supercomputing Center in Wuxi, China, which came onto the Top500 list at the number one ranking in June 2016 and held that position until the early nodes for the “Summit” supercomputer at Oak Ridge National Laboratory came into the datacenter and were tested on a partial configuration. Perlmutter pushes down Nvidia’s own homegrown “Selene” hybrid AI/HPC supercomputer to the number six slot, and everyone else below does some sliding until we see a few new machines here and there and even a few cloud instances on Amazon Web Services and Microsoft Azure.
Which beings us to an important point we need to start considering. When should a cloud supercomputer be added to the Top500 rankings? Just like we believe that a bunch of telco and service provider machines in the United States and China, with a few from Europe, should not have portions of their clusters carved up and have the Linpack test run on them to game the list for nationalistic purposes – you know who you are, but we don’t know who you are because the list doesn’t usually divulge who is running these machines and what their real day job is – we also don’t believe we should pollute the list of actual, sustained HPC investments with cloud supercomputers that cost orders of magnitude less to run for a few hours to show Linpack test results. We think that for any cloud supercomputer to be on the list, it has to be activated for a certain amount of time and be more or less permanent in at least some fashion. Test the peak capacity, for sure. But there has to be rules. Here is one to start: A cloud supercomputer has to be activated with at least 25 percent of its capacity for 50 percent of the wall clock time in a year to even be eligible to be on the Top500 rankings.
Additionally, you could just allow a whole new list of ephemeral cloud instances, called the Top500 Cloud Supercomputers or something like that, which would show these machines being fired up and also show their cost for the time the Linpack runs were done. Then we could do performance analysis and price/performance analysis across clouds and maybe even co-location services that specialize in HPC and AI. This makes sense to us, and let’s get this right before it gets out of hand.
At the moment, there is one machine from Amazon Web Services on the list, which had a peak theoretical performance of 15.11 petaflops and a Linpack rating of 9.95 petaflops, for a computational efficiency of 65.9 percent. There are four cloud supercomputers from the Microsoft Azure cloud listed on the June 2021 Top500 rankings, which have a total of 99.23 petaflops peak and 66.36 petaflops sustained on Linpack, for a computational efficiency of 67.6 percent. If you are sensing a theme, it is that excepting in cases where a machine has been heavily customized, about a third of the aggregate flops in a supercomputer on the Top500 lists go up the chimney. The average across all 500 machines on the June 2021 ranking, in fact, is that only 63.2 percent of the peak performance actually drives Linpack.
If the end of Moore’s Law means anything, it means doing better than that. Better interconnects between CPUs and accelerators would be a good place to start, and the industry is working on that. The memory hierarchy needs to be improved to feed all those cores, too. And the jury is till out on how best to do that. But that HBM2 memory on the A64FX processors used in the “Fugaku” system at RIKEN Lab in Japan, in the “Aurora” vector accelerators used in systems from NEC, and in GPU accelerators from Nvidia and AMD (and soon Intel) are a step in the right direction. We need fatter HBM memory and less dependence on DRAM. Or, better DRAM and no HBM at all. The latter is the way IBM is going to do it with Power10.
Now that we have gotten that off our chest, let’s look at the June 2021 Top500 list a little more carefully.
To get onto the Top500 list this time around, a machine had to have at least 1.52 petaflops of sustained Linpack performance, up 23.6 percent from a year ago, when the entry point was 1.23 petaflops. To be in the Top100, a machine has to have at least 4.13 petaflops running Linpack, up 47.5 percent from the 2.8 petaflops from the June 2020 list. The list is starting to get top heavy, and it is about to get worse when $3 billion a year or so of exascale machines slam into the top 20 machines over the next four years. The aggregate compute power of the entire Top500 list stands at 2.8 exaflops, up 26.7 percent from the 2.21 exaflops a year ago. The “Frontier” machine going into Oak Ridge National Laboratory at the end of this year is on the order of 1.5 exaflops peak, so maybe just around 1 exaflops sustained on Linpack – clearly, that is the goal – and the “El Capitan” machine going into Lawrence Livermore National Laboratory next year is expected to be somewhere north of 2 exaflops peak – call it 2.3 exaflops with maybe 1.,5 exaflops sustained on Linpack. These machines, as well as the exascale systems being installed in Europe and China, are going to skew the Top500 data. Bigtime.
The number of machines that in the Top500 that are accelerated by GPUs has remained more or less constant over the past three years, with modest growth, as you can see in the chart below:
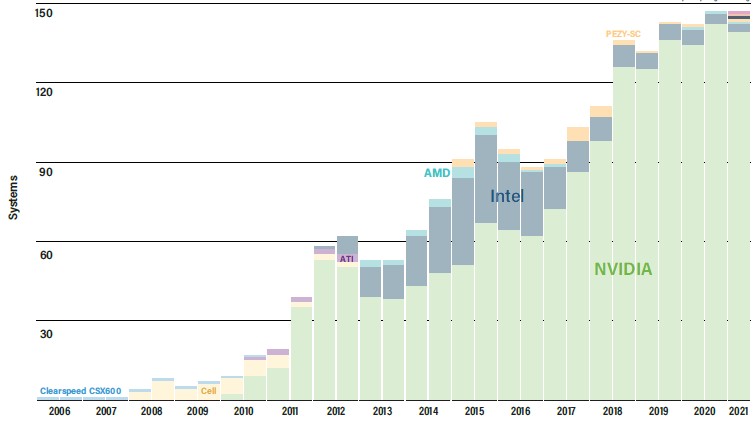
Part of the reason this is the case is that so many telco and cloud clusters that are not really doing HPC or AI work (we strongly suspect) are dominating the middle of the list and do not usually have any kind of acceleration. Moreover, academic and government labs as well as private HPC centers still have a lot of CPU-only codes and have not embraced hybrid architectures. The perceived pain of the transition is greater than the perceived gain, and so people stick to what they know and, we think, they pay a higher price for the hardware to not have to pay a higher price and suffer the disruption of radically tweaking their software. When compilers can do all of this automatically, you will see accelerators rise much more dramatically in use.
Nvidia utterly dominates the list of accelerators employed on the clusters in the Top500 rankings, and here is the breakdown for the June 2021 list:
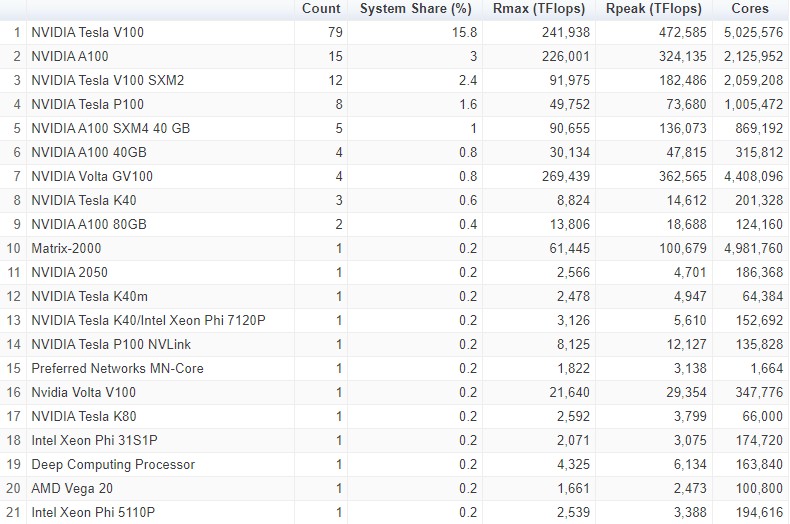
In terms of CPUs, Intel’s dominance is weakening and AMD is on the rise, as we expected. And once the exascale machines hit, AMD will have a large percentage of the GPU compute and even the CPU compute because of the hybrid architectures in use. In June 2018, Intel had 95 percent share of the CPUs used in the Top500 rankings, and in June 2019 it rose to 95.6 percent and then fell to 94.2 percent in the June 2020 list. In the November 2020 list, Intel’s CPU share of the supercomputing rankings dropped to 91.8 percent, with AMD rising to 4.2 percent, and in the June 2021 rankings Intel is down to 86.2 percent of the systems and AMD is up to 9.8 percent of systems. With all of the big pre-exascale systems and exascale systems coming down the pike based on AMD Epyc processors in their hosts, AMD’s share of machines is going to rise, but its share of CPU cores is going to explode. And the same thing is going happen with the system count and GPU count for AMD relative to Nvidia starting with the November 2021 list, when the Frontier system at Oak Ridge is expected to leap ahead of Fugaku and take the top spot.
And, we wait.

Top500 Supers: Nvidia Utterly Dominates Those Shiny New Machines
If you stare at something for a little bit of time and let your mind wander, you can think of a new way to analyze something that you have looked at a bunch of times. We squinted at the June 2024 Top500 supercomputer rankings, which are out a month earlier …
Cadence Sells Custom GPU Supercomputers To Run New CFD Code
If money and time were no object, every workload in every datacenter of the world would have hardware co-designed to optimally run it. But that is obviously not technically or economically feasible. Just the same, sometimes a workload is so important that it warrants a highly tailored system to run …

With Vista, TACC Now Has Three Paths To Its Future Horizon Supercomputer
The national supercomputing centers in the United States, Europe, and China are not only rich enough to build very powerful machines, but they are rich enough, thanks to their national governments, to underwrite and support multiple and somewhat incompatible architectures to hedge their bets and mitigate their risk. In the …
>>> “Add up all of the compute elements in Perlmutter – that is the Epyc cores and the Ampere streaming multiprocessors – and you have 706,304 “cores” and a total power draw of 2.53 megawatts, and Perlmutter has a peak theoretical performance of 89.75 petaflops and delivers 64.59 petaflops of performance on the Linpack test. That’s a computational efficiency of just a hair under 72 percent.”
@Tim
Great article! A question for you.
Perlmutter has 6000 A100s. Each A100 is advertised to have 19.5 TF/s FP64 peak tensor core perf, which can be usable in LINPACK for DGEMMs (https://www.nvidia.com/content/dam/en-zz/Solutions/Data-Center/a100/pdf/nvidia-a100-datasheet-us-nvidia-1758950-r4-web.pdf).
So, the peak theoretical perf of just the A100s in Perlmutter should really be 6000*19.5= 117 PF/s.
The RPeak reported on Top500 is just 89.75 PF/s, presumably for both AMD CPUs and A100s combined. What gives? Are A100s running at a lower power/perf than the spec-sheet or is the Rpeak typically manipulated to make efficiency look better than it is? Do you have any insights? Thank you.
It must not be counting 64-bit tensor core but the raw 64-bit elements. Let me have a think.
The TF64 tensor cores are ideal for dense matrix multiply, so it would be surprising if NVidia does not use those during LINPACK.
Regular FP64 cores cannot get to that high Rpeak. They would max out at 6000*9.7 TF/s = 58.2 PF/s.
Then, each Epyc CPU would have to deliver (89.75-58.2)*1000/1500= 21 TF/s to get to the 89.75 PF/s Rpeak at system-scale, which is implausible.
It’d be great if you can shed some light on this. Thanks!
It’s ironic for the HPC community to complaining about “pollute[ing] the list of actual, sustained HPC investments with cloud supercomputers” while touting ML as the hot new investment. DeepMind/Google Brain, OpenAI, FAIR, etc. are not running on anything in the Top500 list, the state of the art in ML research has all been done on hyperscaler clusters, which are at least an order of magnitude more capable than the machines university groups have access to.
The elephant in the room is that Top500 has long since ceased being the final word in high-performance computing.
The Next Platform was founded on that idea, so no irony here. But we just want separate things kept separate.
China has seemingly decided, at high level, to ignore Top500 since last year’s November round. There already where three 100-200 P X86 systems deployed with Linpack runs done at that time.
China already has a true Exascale fully operational since April. The second system, TianHe 3 ARM, is in the final stages and looking faster than the Fugaku already at this point in yhgg.
Maybe China boycotting the Top500 is similar to everyone else boycotting the Beijing Olympics.
It appears there are many things at the international level that affect science and high performance computing right now. In my opinion, the best way forward is for everyone to work a little smarter and better so popular inflationary entitlements don’t undermine people’s self worth and lead to corruption and crime.
I agree that cloud computing provisioned for a couple days to run HPL should not be counted as resources in a country devoted to science. At the same time, the current list doesn’t really measure how easily available HPC resources and development environments are to sciences in different countries anyway. It would be interesting quantify the percentage of supercomputing time in submitted grants that was awarded per country and what local resources various scientists have in terms of workstations and development clusters.