

Governments like to spread the money around their indigenous IT companies when they can, and so it is with the AI Bridging Cloud Infrastructure, or ABCI, supercomputer that is being commissioned by the National Institute of Advanced Industrial Science and Technology (AIST) in Japan. NEC built the ABCI prototype last year, and now Fujitsu has been commissioned to build the actual ABCI system.
The resulting machine, which is being purchased specifically to offer cloud access to compute and storage capacity for artificial intelligence and data analytics workloads, would make a fine system for running HPC simulation and models. But that is not its intended purpose, as was the case with the Tsubame 3.0 system that was made by SGI (a strong player in Japan and now part of Hewlett Packard Enterprise) and that includes a mix of Intel “Broadwell” Xeon E5 processors and Nvidia “Pascal” Tesla P100 GPU accelerators.
If the Linpack parallel Fortran benchmark test was run on the finished ABCI machine, which should hit 37 petaflops peak theoretical performance at double precision floating point, it would be shown to be three times as powerful as the Tsubame 3.0 machine that is aimed at HPC workloads.
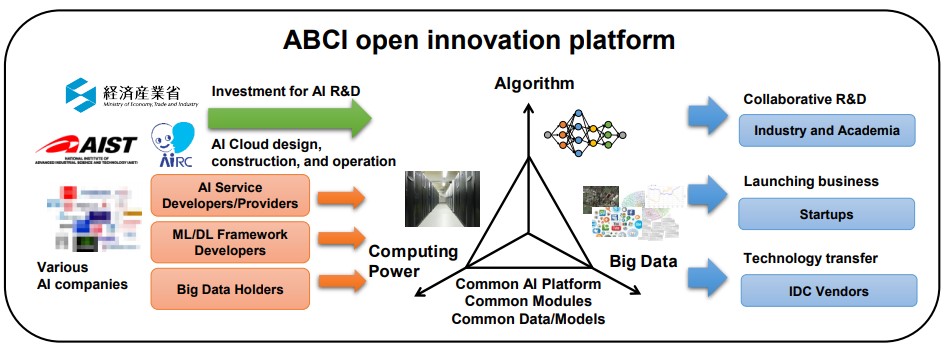
But importantly, the ACBI system will be using the new “Volta” Tesla V100 GPU accelerators, which sport Tensor Core units that deliver 120 teraflops per chip for machine learning training and inference workloads. That is 12X the performance of the Pascal GP100 chip on training at 32 bit single precision floating point and 6X the performance of the GP100 on inference at 16-bit half precision. Technically, this would make ABCI the most powerful supercomputer in Japan when it is fired up, and the third most powerful one in the world, if you use the Top 500 Linpack rankings are your gauge and if Linpack is even run on it at some point in the future. (There are lots of super-secret machines that don’t run the Linpack test publicly, as well as big systems like the “Blue Waters” hybrid CPU-GPU machine at the University of Illinois.)
The ABCI prototype, which was installed in March, consisted of 50 two-socket “Broadwell” Xeon E5 servers, each equipped with 256 GB of main memory, 480 GB of SSD flash memory, and eight of the tesla P100 GPU accelerators in the SMX2 form factor hooked to each other using the NVLink 1.0 interconnect. Another 68 nodes were just plain vanilla servers, plus two nodes for interactive management and sixteen nodes for other functions on the cluster. The system was configured with 4 PB of SF14K clustered disk storage from DataDirect Networks running the GRIDScaler implementation of IBM’s GPFS parallel file system, and the whole shebang was clustered together using 100 Gb/sec EDR InfiniBand from Mellanox Technologies, specifically 216 of its CS7250 director switches. Among the many workloads running on this cluster was the Apache Spark in-memory processing framework.
The goal with the real ABCI system was to deliver a machine with somewhere between 130 petaflops and 200 petaflops of AI processing power, which means half precision and single precision for the most part, with a power usage effectiveness (PUE) of somewhere under 1.1, which is a ratio of the energy consumed for the datacenter compared to the compute complex that does actual work. (This is about as good as most hyperscale datacenters, by the way.) The system was supposed to have about 20 PB of parallel file storage and, with the compute, storage, and switching combined, burn under 3 megawatts of juice.
The plan was to get the full ABCI system operational by the fourth quarter of 2017 or the first quarter of 2018, and this obviously depended on the availability of the compute and networking components. Here is how the proposed ABCI system was stacked up against the K supercomputer at the RIKEN research lab in Japan and the Tsubame 3.0 machine at the Tokyo Institute of Technology:
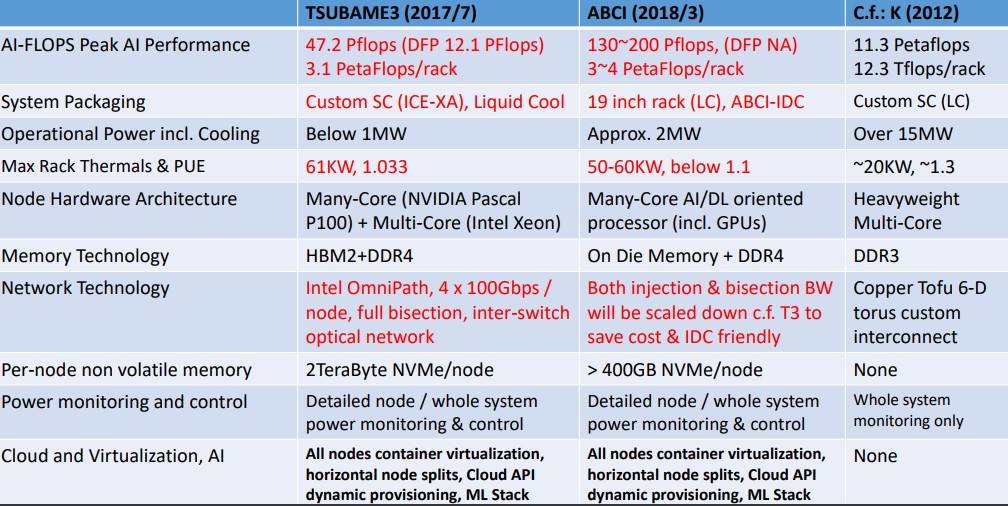
The K machine, which is based on the Sparc64 architecture and which was the first machine in the world to break the 10 petaflops barrier, will eventually be replaced by a massively parallel ARM system using the Tofu interconnect made for the K system and subsequently enhanced. The Oakforest-PACs machine built by University of Tokyo and University of Tsukuba is based on a mix of “Knights Landing” Xeon Phi processors and Omni-Path interconnect from Intel, and weighs in at 25 petaflops peak double precision. It is not on this comparison table of big Japanese supercomputers. But perhaps it should be.
While the Tsubame 3.0 machine is said to focus on double precision performance, the big difference is really that the Omni-Path network hooking all of the nodes together in Tsubame 3.0 was configured to maximize extreme injection bandwidth and to have very high bi-section bandwidth across the network. The machine learning workloads that are expected to run on ABCI are not as sensitive to these factors and, importantly, the idea here is to build something that looks more like a high performance cloud datacenter that can be replicated in other facilities, using standard 19-inch equipment rather than the specialized HPE and SGI gear that TiTech has used in the Tsubame line to date. In the case of both Tsubame 3.0 and ABCI, the thermal density of the compute and switching is in the range of 50 kilowatts to 60 kilowatts per rack, which is a lot higher than the 3 kilowatts to 6 kilowatts per rack in a service provider datacenter, and the PUE at under 1.1 is a lot lower than the 1.5 to 3.0 rating a typical service provider datacenter. (The hyperscalers do a lot better than this average, obviously.)
This week, AIST awarded the job of building the full ABCI system to Fujitsu, and nailed down the specs. The system will be installed at a shiny new datacenter at the Kashiwa II campus of the University of Tokyo, and is now going to start operations in Fujitsu’s fiscal 2018, which begins next April.
The ABCI system will be comprised of 1,088 of Fujitsu’s Primergy CX2570 server nodes, which are half-width server sleds that slide into the Primergy CX400 2U chassis. Each sled can accommodate two Intel “Skylake” Xeon SP processors, and in this case AIST is using a Xeon SP Gold variant, presumably with a large (but not extreme) number of cores. Each node is equipped with four of the Volta SMX2 GPU accelerators, so the entire machine has 2,176 CPU sockets and 4,352 GPU sockets. The use of the SXM2 variants of the Volta GPU accelerators requires liquid cooling because they run a little hotter, but the system has an air-cooled option for the Volta accelerators that hook into the system over the PCI-Express bus. The off-the-shelf models of the CX2570 server sleds also support the lower-grade Silver and Bronze Xeon SP processors as well as the high-end Platinum chips, so AIST is going in the middle of the road. There are Intel DC 4600 flash SSDs for local storage on the machine. It is not clear who won the deal for the GPFS file system for this machine, and if it came in at 20 PB as expected.
Fujitsu says that the resulting ABCI system will have 37 petaflops of aggregate peak double precision floating point oomph, and will be rated at 550 petaflops, and 525 petaflops off that comes from using the 16-bit Tensor Core units that were created explicitly to speed up machine learning workloads. That is a lot more deep learning performance than was planned, obviously.
AIST has amassed $172 million to fund the prototype and full ABCI machines as well as build the new datacenter that will house this system.
About $10 million of that funding is for the datacenter, which had its ground breaking this summer. The initial datacenter setup has a maximum power draw of 3.25 megawatts, and it has 3.2 megawatts of cooling capacity, of which 3 megawatts come from a free cooling tower assembly and another 200 kilowatts comes from a chilling unit. The datacenter has a single concrete slab floor, which is cheap and easy, and will start out with 90 racks of capacity – that’s 18 for storage and 72 for compute – with room for expansion.
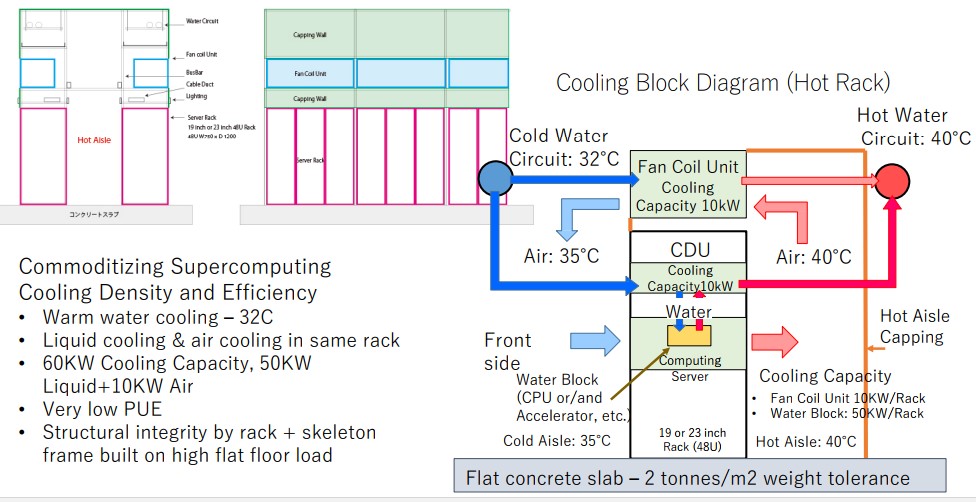
One of the neat bits of the ABCI design is the rack-level cooling, which includes 50 kilowatts of liquid cooling and 10 kilowatts of air cooling. The liquid cooling system uses 32 degree Celsius water (90 degree Fahrenheit) and 35 degree Celsius air (95 degree Fahrenheit). The water cooling system has water blocks on the CPUs and GPUs and probably the main memory, and there is hot aisle capping to contain it and more efficiently remove its heat.

Some parts of the ABCI stack look familiar to the HPC crowd, but most of it has come from the hyperscalers. The system runs Linux, of course, and it is containerized as well. (Docker or LXC we presume.) The ABCI stack can support InfiniBand or Omni-Path interconnects. Fujitsu did not make it clear which one was chosen, but the prototype was based on EDR InfiniBand and we suspected when this story originally ran that the full machine probably is , too. (We have subsequently heard through the grapevine that the production ABCI machine is indeed based on InfiniBand.)
The HDFS file system that underlays Hadoop data analytics is a key component of the stack, as are a number of relational and NoSQL data stores. And while there is MPI for memory sharing and the usual OpenACC, OpenMP, OpenCL, and CUDA for various parallel programming techniques, and some familiar programming languages and math libraries, the machine learning, deep learning, and graph frameworks running atop the ABCI system make it different, and also drive a different network topology from the fat trees used in HPC simulations where all nodes sometimes have to talk to all other nodes. That doesn’t happen in machine learning and deep learning – at least not yet.
The other interesting bit about the ABCI system is the tests that were used by AIST to select the architecture and the vendors of the components. The system relied on the SPEC CPU benchmarks, but did not use any of the standard HPC tests like Linpack or STREAM or DGEMM as part of the selection criteria. The tests that were run on proposed systems included the Graph 500 and MinuteSort tests as well as local storage and parallel I/O storage throughput. The low-precision GEMM test was used to define the level of “AI flops” in the system, and the AlexNet and GoogLeNet convolutional neural networks (CNNs) were used with the TLSVRC2012 image library. Caffe goosed by MPI was used as a multi-node CNN test, and Convnet on Chainer was used to stress a large memory CNN on the proposed system. Neural machine language translation was run on the Torch framework using recurrent neural network (RNN) with the long short-term memory (LSTM) approach.
It will be interesting to see if AIST will really make this a cloud, meaning that it will literally sell capacity on the system to interested parties, and if there is a plan to scale this much further to make an indigenous HPC/AI cloud that can compete with the likes of Google, Amazon, and Microsoft in the United States and Alibaba and Baidu in China. Japan needs such a resource, for its own pride as much as anything else. They have an architecture, but do they have a business plan? That is the real question.

Stacking Up Intel Gaudi Against Nvidia GPUs For AI
Updated: Here is something we don’t see much anymore when it comes to AI systems: list prices for the accelerators and the base motherboards that glue a bunch of them together into a shared compute complex. But at the recent Computex IT conference in Taipei, Taiwan, Intel, which is desperate …

Intel Finally Gets Chiplet Religion With Server Chips
When the top brass at Intel say that the “Sapphire Rapids” Xeon SP CPUs and “Ponte Vecchio” Xe HPC GPUs that are coming out early next year represent the “largest architectural shift in over a decade,” they ain’t kidding. At the third annual Architectural Day hosted this week, we heard …
H100 GPU Instance Pricing On AWS: Grin And Bear It
UPDATED: It is funny what courses were the most fun and most useful when we look back at college. Both microeconomics and macroeconomics stand out, as does poetry writing, philosophy, and religious studies despite the focus on engineering and American literature. The laws of supply and demand rule our lives …
The third most powerful super in the TOP500 is going to Java or Scala (aka Spark).
Hey, let’s install Visual Basic too, for the real slow learners.