

It must be tough for the hyperscalers that are expanding into public cloud and the public cloud builders that also use their datacenters to run their own businesses to decide whether to hoard all of the new technologies that they can get their hands on for their own benefit, or to make money selling that capacity to others.
For any new, and usually constrained, kind of capacity, such as shiny new “Skylake” Xeon SP processors from Intel or “Volta” Tesla GPU accelerators from Nvidia, it has to be a hard call for Google, Amazon, Microsoft, Baidu, Tencent, and Alibaba to make. We don’t know when any of the hyperscalers and cloud builders get the hot new tech unless they tell us – and they rarely tell us – for their internal use, but we do know when they make it available on the public cloud because they make a lot of noise about it.
For the Volta GPU accelerators, Amazon Web Services, the public cloud juggernaut that is the profit engine of the online retailing behemoth, is the first to get these massively parallel motors, which made their debut back in May, up and running on an infrastructure cloud among the big providers. Various server OEMs and ODMs got their hands on Voltas a few weeks back and have announced their initial systems already.
Amazon doesn’t generally talk to the press and analyst community, except from on high from its events because company execs are allergic to answering questions like grownups do, so we can’t get a sense from AWS how the prior generation of P2 instances on its Elastic Compute Cloud (EC2) infrastructure, which made their debut in September 2016 using Nvidia’s Tesla K80 GPU motors, sold and therefore get a sense of how the new P3 instances, which are based on the Volta V100 GPUs, might do. But in a statement announcing the P3s, Matt Garman, vice president in charge of EC2, said that AWS “could not believe how quickly people adopted them,” referring to the P2s, and added that most of the machine learning done on the cloud today is on P2 instances, and “customers continue to be hungry for more powerful instances.”
AWS gets very touchy when we suggest that sometimes it hangs back with technologies, which we did suggest when it opted for the dual-socket Tesla K80 accelerators from Nvidia into its P2 instances. The Tesla K80s are based on the “Kepler” GPU architecture, which was already a year old when it was put into the first K80s back in November 2014. That was almost three years ago now. The P2 instances on EC2 are based on a two-socket server using custom “Broadwell” Xeon E5-2686 v4 processors, in this case with 16 cores running at 2.7 GHz. And once again, we will point out that the Broadwell chips started shipping in September or October 2015 before they were launched in the P2 instances about a year later.
We realize it takes time to ramp production and that all public cloud builders need to amortize their costs over a long time period of three to four years, sometimes more. So the transitions in the cloud fleets take time, just as they do in the enterprise datacenters of the world. And thus, we are not surprised that AWS is deploying the Volta GPUs with the same custom Broadwell processors, but in this case, it is shifting from a motherboard that uses PCI-Express 3.0 links to lash the GPUs to the CPUs, as with the Tesla K80s, to a motherboard that has native NVLink 2.0 ports and uses the SXM2 sockets for the Volta GPUs to put up to eight GPUs on the system.
Given this re-engineering work, you might be thinking that AWS would have gone all the way and opted for a custom “Skylake” Xeon SP processor for this P3 instance. This certainly seemed logical a year ago. But the whole point about GPU accelerated computing is that the CPU is not doing a lot of work, and a Broadwell Xeon is considerably less expensive than a Skylake Xeon, as we have shown in great detail. There is no much point in having a CPU with lots of vector math, as with Skylake, if you are offloading the math to the GPU. Hence, we presume, the smartness of sticking with Broadwell. If Skylake Xeons supported PCI-Express 4.0 peripheral links between the CPUs and the GPUs, then it might be a totally different story, and a year ago there was still a chance that the Skylakes would support PCI-Express 4.0. But with the PCI-Express 4.0 spec just being finalized this week, it would have been tight to get the Skylakes out the door with working PCI-Express. (IBM was probably pushing it by having PCI-Express 4.0 integrated with the Power9 chip, and that might be one of the reasons why its volume ramp is now throughout 2018 instead of the second half of 2017.)
In any event, this time around, AWS is on the front end of the Volta wave, but will be last of the big cloud providers to launch Skylake Xeon instances, if and when it does it next month at its re:Invent shindig in Las Vegas. As far as we know, Amazon bought a ton of Skylake processors from Intel in the second quarter, but Google was in the front of the line in the first quarter and got its initial shipments late in 2016.
We have heard from sources in the know that AWS is making use of a variant of the HGX-1 reference design that was created by Microsoft in conjunction with Ingrasys, a maker of OpenPower platforms that is a subdivision of giant contract manufacturer Foxconn. As we previously reported, Microsoft open sourced the HGX-1 design of its machine learning box through the Open Compute Project back in March, specifically so others might pick up and run with it.
The initial HGX-1 design was based on the “Pascal” P100 SXM2 socket and the system board had room for eight of these; the PCI-Express mesh of the HGX-1 was such that four of these HGX-1 systems, each with two Xeon processors and eight GPU accelerators, could be lashed together and share data across the NVLink 1.0 and PCI-Express 3.0 ports. With the Volta GPU accelerators, NVLink is stepped up to the faster 2.0 level with 25 Gb/sec signaling, but the PCI-Express is the same on the servers.
The P2 instances were available in the US East (Northern Virginia), US West (Oregon), and EU (Ireland) regions, and with the P3 instances, these same regions are supported and the Asia Pacific (Tokyo) region is added, and additional regions are promised in the future. AWS operates 16 regions with a total of 44 availability zones, each comprised of one or more datacenters, around the globe, and has another six regions with 17 more availability zones in the work. It will probably be a while before GPUs are pervasive across all AWS regions and zones. But if AI and HPC and database acceleration go as mainstream as we think they could, that could change a lot over the next couple of years.
While AWS had some earlier G2 and G3 instances that had GPU offload capabilities, these were really aimed at desktop virtualization workloads and we never thought of them as a serious contender in the HPC, AI, and now database acceleration areas. The P2 instances were an honest attempt at crafting something for both HPC and AI, and with the P3 instance, AWS is truly on the cutting edge of GPU acceleration. Here is how the P2 and P3 instances stack up against each other:

Remember, the Tesla K80 is a card with two GPUs – in this case, the GK210B unit – and all of its feeds and speeds in terms of GDDR5 memory and bandwidth are shared by two. This table normalizes the data for each GPU socket.
Both AWS GPU instance types rely on Elastic Network Adapter (ENA) connectivity, which allows for shifting from 10 Gb/sec to 25 Gb/sec performance by resetting the homegrown FPGA on the smart NIC that Amazon has developed with its Anapurna Labs division. This ENA card can also be scaled down below 10 Gb/sec, which it is on the entry P2 and P3 instances. Both also rely on Elastic Block Storage (EBS) for hosting operating system and application data for the nodes; there is no local or ephemeral storage associated with these instance types. The cost of network and EBS is not shown in the pricing for on demand (OD) and reserved instance (RI) types. On demand means you buy it by the hour, no commitments, and this is the highest price. We picked a three year reserved instance for our comparison, with no money up front, because that term is akin to the lifespan of a server among hyperscalers and cloud builders and no money down is worth a bit of a premium compared to paying up front. With the P3 instances, that three year, no money down reserved instance cuts the cost per hour by 56.5 percent; with the P2, the discount was 49 percent.
While these basic feeds and speeds are interesting, what matters for HPC and AI workloads is money, memory bandwidth, and compute capacity – in that order. So this second table will help reckon the P2 and P3 instances against each other, and also against the touchstone server using the Volta GPU accelerators, Nvidia’s own DGX-1V system. We tossed in its predecessor, the DGX-1P system based on Pascal, too, to make a point.
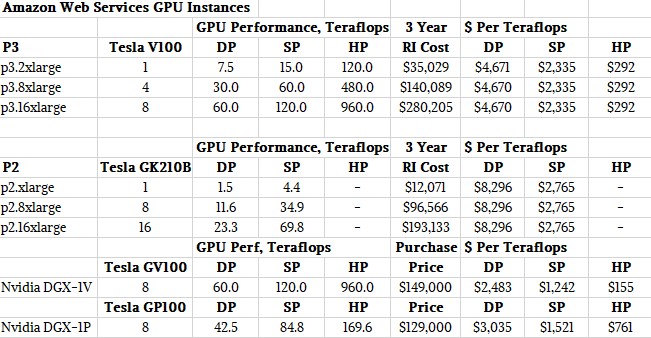
In this chart, we have added in the performance of the instance at half, single, and double precision floating point. The Kepler GPUs did not support half precision, and while the “Pascal” GPUs did support a kind of half precision floating point as well as 8-bit integer math, the Tensor Core implementation in the Volta GV100 is a lot more sophisticated and is tuned precisely to the functions used in machine learning training and inference alike.
A few things jump out in these comparisons. First, thanks to the improvement in double precision performance with the Volta GV100 GPUs, the cost that AWS is charging for a teraflops of oomph has come way down for both a machine you have reserved for three years or you buy using capacity on demand at an hourly rate. For a three year reserved machine fully loaded with Volta GPUs on AWS – that’s the p3.16xlarge with eight Tesla G100s –the cost of a teraflops is $4,670, down 43.7 percent from the p2.16xlarge instance with eight Tesla K80s, which cost $8,290 per teraflops. If you rented the full on p3.16xlarge on demand for three years, which is the highest price you could pay for the compute, it could cost $10,730 per teraflops at double precision, or $643,775 compared to $280,205 for the reserve instances. If you did that, you would be stupid. But it gives you a sense of how much money Amazon might make out of a GPU accelerated node if it can get something even close to 50 percent utilization on it with a half and half mix of on demand and reserved instances. Call it something around $150,000 a year.
Well, isn’t that funny. For the same $150,000, you could get a DGX-1V system from Nvidia. But, you will probably have to go to an OEM or ODM to get a machine like a DGX-1V, because you are not Elon Musk or Yann Le Cun and these systems are supposed to be aimed at researchers. (Funny also how Facebook has a 128-node DGX-1P cluster, though, and it was tested running the Linpack HPC benchmark.)
For single precision math, the P3 instances at AWS are not offering quite the same jump in performance, and that would be a big deal for machine learning inference if it were not for the fact that the bunch of Tensor Core units on Volta do an even much better job at it. Anyway, for single precision floats, the P3 instances cost $5,365 per teraflops over three years with reserved instances, down only 1 percent from the P2 instances. But with that half precisionishness of the Tensor Core , you can make machine learning training run around twelve times faster and machine learning inference run six times faster than with Pascal, according to Nvidia. So for those workloads at least, the jumps are much larger and the bang for the buck much better than the raw DP, SP, and HP numbers in this table imply.
You begin to understand why AWS skipped the Pascal GPUs. We would have, too, if we knew Volta was on the way. It is a much better fit for HPC, AI, and even database acceleration workloads, and not just because of the compute but because of the caching hierarchy, the HBM2 memory that is twice as fat at 16 GB per GPU and 25 percent faster at 900 GB/sec per GPU, and the incremental cost is only probably about 30 percent or so at list price.
AWS and other cloud builders could have installed the PCI-Express variants of the Volta GPUs to save some dough, and it is interesting in that AWS went all the way, unlike some system makers. But there is a reason for that.
“For AI training, the NVLink interconnect allows those eight Volta GPUs to act as one and not be inhibited by inter-GPU communication,” Ian Buck, vice president of accelerated computing at Nvidia, tells The Next Platform. “That’s why we created NVLink, but you don’t have to use it, and all of the frameworks and the container environment we have created for the Nvidia GPU Cloud all works with PCI-Express versions of Volta. There is a bit of a slowdown, but the SXM2 and NVLink provide the best performance. There is always a choice, but I would expect a significant majority of cloud deployments to be for the SXM2 versions and using the HGX-1 setup. Traditionally, PCI-Express is very easy to design in, and we continue to make it available because it is a form factor that the entire catalog of the world’s servers can execute on. For some workloads, like machine learning inferencing or some HPC workloads where we don’t have to span multiple GPUs, then PCI-Express works just fine.”
We pressed Buck on how Nvidia expected the breakdown of cloud versus on premises might play out with regard to the sales of Volta accelerators. We suggested that it might turn out that only 40 percent to 50 percent of the Volta accelerators might end up in the thousands of sites worldwide that do AI, HPC, or database stuff, and the remaining 50 percent to 60 percent would end up at cloud builders and hyperscalers. We happen to think, we shared with Buck, that of this, more of the Volta GPUs would be facing inwards, doing work like image recognition, speech to text or text to speech conversion, or search engine indexing aided by machine learning, image autotagging, recommendation engines, and such work that the hyperscalers do for themselves. The smallest piece of the Volta installed base might be the bit running on the cloud for public consumption. But, ironically, we think that the chunk of Volta capacity running on the cloud and facing outwards could generate more cash than the chunk running in private datacenters. Just look at the multiples for the reserved instances compared to the acquisition of a DGX-1 as a guide. And, irony of all ironies, with the big HPC centers and hyperscalers fighting hard to be at the front end and arguing for deep discounts (we presume) and getting them (we presume), this part of the business may account for a lot of Volta shipments, but less than you might think of revenues and perhaps even less for profits.
It is interesting to contemplate who will make more money – meaning net income – from Volta: Nvidia, or AWS? Buck neither confirmed or denied our scenario, but he didn’t burst out laughing and say it was stupid, either.
One other interesting tidbit: Buck confirms that the AWS instances are not running in bare metal mode, but using the custom Xen hypervisor that AWS has long-since cooked up for its EC2 infrastructure service. Buck adds that the overhead of this hypervisor layer only imposes about a 1 percent performance penalty on the system, including the GPUs. That is basically negligible, and a big improvement over the 30 percent overhead we saw in the early days of server virtualization hypervisors on X86 systems a little more than a decade ago.

In addition to touting the rollout of Volta GPUs on the AWS cloud, Nvidia also picked today to make its Nvidia GPU Cloud, or NGC, generally available and show how it will be linked to public clouds, starting with AWS but no doubt expanding to everybody. NGC previewed back in May at the GPU Technical Conference, and what may not be obvious is that it is not a cloud, per se, but a cloud-based registry for containerized frameworks and application images for machine learning that is used to keep the DGX-1 appliances up to date. It is intended to be used by developers to deploy software for ceepie-geepie machines, but it is not a place where such software actually runs.
In order to stimulate the use of hybrid computing for AI, Nvidia is making its cloud registry available for free, whether the tool is used to deploy software to public clouds like AWS or to on-premises iron owned by organizations and whether it is used for research or production.


With Huge Costs, Efficiency Is The Key To Mainstreaming Generative AI
The hype around generative AI is making every industry vibrate at an increasingly high pitch in a way that we have not seen since the days of the Dot Com boom and sock puppets. With promises of more automation and significant cost savings that could come to areas like customer …
Inside The Massive GPU Buildout At Meta Platforms
If you handle hundreds of trillions of AI model executions per day, and are going to change that by one or two orders of magnitude as GenAI goes mainstream, you are going to need GPUs. Lots of GPUs. And apparently Meta Platforms does, and it is getting out its big, …

Where To Park Your AI Cluster Is As Important As Procuring It
When we think about high performance computing, it is often in the context of liquid-cooled systems deployed in facilities specifically designed to accommodate their power and thermal requirements. With artificial intelligence, things can get tricky. While the systems themselves are powered by many of the same CPUs, GPUs, and NICs, …
First Tier One to have V100… sure, maybe. But not the first to have V100 in the cloud. I’m pretty sure Cirrascale had the first V100s deployed in the cloud, and was the first to announce it as well. Just sayin’.
I guess we could say “big public clouds”? I have nothing against niche players, but they are just that.