
In the public cloud business, scale is everything – hyper, in fact – and having too many different kinds of compute, storage, or networking makes support more complex and investment in infrastructure more costly. So when a big public cloud like Amazon Web Services invests in a non-standard technology, that means something. In the case of Nvidia’s Tesla accelerators, it means that GPU compute has gone mainstream.
In years gone by, AWS tended to hang back on some of the Intel Xeon and AMD Opteron compute on its cloud infrastructure, at least compared to the largest supercomputer centers and hyperscalers like Google and Facebook, who got the X86 server chips earlier in the product cycle. But in recent years, Amazon has been on the front end of the CPU cycles among its cloud peers, shipping “Haswell” Xeon E5 v3 processors in the the C4 instances in January 2015, about four months after Intel launched them, and in the M4 instances in June 2015, nine months after their launch. Amazon similarly added “Haswell” Xeon E7 v3 processors, which were launched in May 2015, inside of its X1 instances in May 2016. That was a year between when Intel launched and when AWS had the X1 instanced up. And a month later, Intel launched the Broadwell Xeon E7 v4 chips, and there is no way that AWS didn’t know they were coming then and there is no way that if AWS wanted to be among the first to deploy the Xeon E7 v4 processors in the world (not just among cloud providers) Intel would not have been thrilled to sell them a couple of ten thousand of them.
Obviously, AWS can’t change all instance types to the latest CPUs and now GPUs instantaneously; it has to get three or four years out of each machine it installs and it has to ramp up installations along with its compute suppliers–and at aggressive pricing that preserves its margins.
AWS took issue with our interpretation of all this, pointing out that it is ahead of other cloud providers. But that was not our point. The hyperscalers and HPC shops pay a premium to get the latest chips often ahead of their official launch and get them installed as soon as possible, and the big public cloud builders, including AWS, do not do this as far as we know, and for sound economic reasons.
Here is the more important point. With the new P2 instances on the EC2 compute facility, AWS is definitely putting mainstream CPU and GPU parts into the field that can run a variety of applications, including traditional simulation and modeling workloads typical in the HPC market as well as the training of neural networks in deep learning and GPU-accelerated databases.
The P2 instances are based on a custom “Broadwell” Xeon E5 v4 processor that AWS commissioned Intel to build that has 16 cores and that runs at 2.7 GHz. Again, to our point, Intel actually started shipping early Broadwell Xeon E5 v4 processors to HPC and hyperscale customers at the end of 2015 (we think in September or October), and the official launch of the chips was in March of this year, but the P2s are coming out in September 2016. AWS could have launched these in March concurrent with the Broadwell announcement, since the Tesla K80s themselves debuted in November 2014. And if it was really on the front end, the P2 instances would have been based on Broadwell Xeons plus “Pascal” Tesla P100s, and if it wanted to stay there, sometime in the second half of next year there would be a P3 instance with “Skylake” Xeon E5 v5 chips married to “Volta” Tesla accelerators. AWS might be installing Broadwell processors ahead of its cloud peers–the Xeon E5-2686 v4 chip was also added to the fattest M4 instance last week, the m4.16xlarge instance–but this is not exactly at the front of the Xeon or Tesla lines.
Each of the P2 servers has two of these Xeon processors and eight of Nvidia’s Tesla K80 accelerators. If you look at the details from AWS, you might get the impression that it has put 16 of the Tesla cards in this server, but AWS is counting the individual “Kepler” family GK210B GPUs and their dedicated 12 GB GDDR5 memory chunks individually. The K80 has two GPUs, each with its own frame buffers. If would be cool if AWS actually put 16 Tesla K80s in a server – and some vendors are doing this to create extremely beefy compute nodes for deep learning and simulation – but this is not the case.
Each Tesla K80 has a total of 4,992 CUDA cores running at a base speed of 560 MHz with a GPUBoost speed of 875 MHz, and delivers 240 GB/sec of bandwidth between the GK210B and its 12 GB of GDDR5 memory. With the clock speeds cranked on all cores (which is possible if the server can take eight cards jamming at 300 watts each, as the custom AWS system must surely be able to do), each card can deliver a peak 8.74 teraflops of floating point math crunching at single precision and a third that, or 2.91 teraflops, at double precision.
Being able to support both SP and DP math is key because some workloads really require that extra precision. AWS cannot build some clusters aimed at deep learning based on the “Maxwell” M4 and M40 accelerators that came out in November 2015 or the new “Pascal” P4 and P40 units that came out earlier this month because, despite all of the noise, deep learning has not gone mainstream among the enterprise customers who use the AWS cloud – although it most certainly has within the Amazon retail business itself and among the hyperscalers like Facebook that have widely deployed the M40 accelerators for this purpose. Given its desire to buy the cheapest powerful compute it can get, the cost of the flops on a Pascal P100 card with NVLink that came out in April this year are a little too rich and rare for AWS at this time, and what we hear is that while the PCI-Express variants of the Tesla P100 that came out in June offer substantially better bang for the buck than the Tesla K80s at list price, volumes are still ramping for all P100s.
Perhaps more importantly, the PCI-Express versions of the P100s have either 12 GB or 16 GB of HBM memory per PCI slot (and per GPU), but the double-packed Tesla K80 can get 24 GB of GDDR5 memory in the same space. The K80 still has a density advantage, and we figure AWS is getting a great price on these K80s, too. If AWS is getting a 30 percent discount off the K80’s street price, the SP flops will be 30 percent cheaper on the K80 than on the PCI-Express variant of the P100 and the DP flops will be about the same price. If AWS is being more aggressive in its pricing, it can make the K80s an even better price/performer. The cheaper PCI-Express P100 card, at 540 GB/sec per slot, doesn’t have that much more bandwidth than the K10, at 480 GB/sec across two GPUs in a slot.
By making Tesla K80s, which are the workhorse GPU accelerators in the Nvidia line, AWS can cover the most bases and crank up its volume purchases from Nvidia. As more customers with different workloads come to the cloud to run their models, simulations, neural nets, and databases, AWS will be able to diversify its fleet of GPU accelerators to better match the needs of the workloads, and will also enable customers to have complex workflows that mix and match different GPUs across those workflows. This is just the beginning of Nvidia’s assault on an addressable market for GPU compute that Nvida pegged at $5 billion a year ago and which is probably larger now.
Doing The Math
The G2 compute instances that married “Sandy Bridge” Xeon E5 processors with Nvidia’s GRID K520 accelerators were not Tesla-class compute and were really intended for video streaming and encoding and decoding work as well as pumping virtual desktops out of the Amazon Cloud. They were fit for purpose, and we able to be used as compute engines for CUDA and OpenCL applications if customers could deal with the lack of error correction on the GDDR5 frame buffer memory and other features found on the Tesla accelerators.
As we pointed out last July when we said that GPUs on the cloud were still nascent, these were not even Amazon’s first attempt at providing GPU compute capabilities. Way back in November 2010, when HPC on the cloud seemed poised to take off, AWS put a bunch of Tesla M2050 cards on a section of its server farm (using “Nehalem” Xeon X5570 processors) and allowed customers to glue up to eight nodes together to create an 8.24 teraflops cluster. But, lighting the fuse on HPC on the cloud was a bit tougher than expected, mostly because of the issues of licensing HPC codes on public clouds under a utility pricing model, and that is why instead of deploying Teslas with the G2 instances, it went with the GRID K520s. There was a video workload that really justified Amazon’s investment, and HPC and deep learning came along for the ride. It looks like there is enough deep learning and HPC work out there to justify a true Tesla investment now for the AWS cloud, and hence the deployment of Tesla K80s in the P2 instances now.
Here is how the G2 and P2 instances compare with each other in terms of their feeds and speeds:

As you can see, the P2 instances have a lot more floating point oomph and a lot more frame buffer memory and aggregate bandwidth on that memory to make use of it. The networking on the largest instances is 20 Gb/sec, and we presume that RDMA over Converged Ethernet (RoCE) and GPUDirect, which allow for data to be passed from CPU to CPU or from GPU to GPU without going through the full CPU software stack, are enabled on the new P2 instances. Add it all up and GPU accelerated instances should run a lot faster on the P2 instances than on the G2 instances.
As the first table above shows, the cost per hour for on-demand or pre-paid reserve instances (those are for standard three-year contracts for the reserved instances) is considerably higher on the P2 instances than on the G2 instances. But look at the performance differences in the second table. We have estimated the single precision (SP) and double precision (DP) floating point performance of the GRID K520 card, and the G2 instances have either one or four of these fired up with an appropriate amount of CPU to back them.
The P2 instances deliver a lot better bang for the buck, particularly on double precision floating point work. Take a look at the cost of GPU-accelerated Linux instances on the EC2 utility for a whole year:
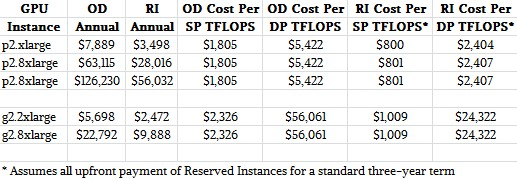
We divided the annual cost for on-demand and reserved instances for the G2 and P2 instances, and obviously the cost can mount up. But buying a two-socket Xeon server with eight Tesla K80 cards is not cheap either, and neither is powering it, equipping it with software, and maintaining it.
The price that AWS is charging for both the G2 and P2 instances scales linearly with the GPU compute capacity, as you can see. For single precision floating point, the price drop per teraflops is only around 22 percent from the G2 instances to the P2 instances for single precision work, but the compute density of the node has gone up by a factor of 7.1X and the GPU memory capacity has gone up by a factor of 12X within a single node, which doesn’t affect users all that much directly but does help Amazon provide GPU processing at a lower cost because it takes fewer servers and GPUs to deliver a chunk of teraflops.
The fun bit is looking at the change in pricing for double precision. It is an order of magnitude less costly to have double precision on the P2 instances than on the G2 instances.
Obviously, as the table above shows, paying three years in advance for reserved instances saves a ton of money compared to using on-demand instances.
The tougher – but necessary – comparison is to reckon what it costs to build an HPC cluster on AWS using these Tesla K80s and compare it to the cost of actually owning and operating a similar cluster in your own shop. We also want to know how GPU instances on Microsoft Azure, IBM SoftLayer, and Nimbix stack up. This is a detailed exercise we will have to save for another day, so bear with. We are also working to find out how many of these P2 instances can be clustered to see what kind of virtual hybrid supercomputer can be built for a long-term jobs.
The P2 instances require 64-bit, HVM-style Amazon Machine Images (AMIs) that are backed by its Elastic Block Storage (EBS) service; they do not have local SSD storage like the G2 instances did. CUDA 7.5 and OpenCL 1.2 are supported on the P2 instances. The P2 instances are available today in the US East (Northern Virginia), the US West (Oregon), and the Europe (Ireland) regions as on-demand, spot, or reserved instances as well as for dedicated hosts.
In addition to the new instances, Amazon has packaged up a new Deep Learning for AMI software stack, which you can read more about here. It includes the Torch and Caffe deep learning frameworks, the MXNet deep learning library, the Theano array library, and the TensorFlow data flow graph library.

SambaNova Doubles Up Chips To Chase AI Foundation Models
One of the first tenets of machine learning, which is a very precise kind of data analytics and statistical analysis, is that more data beats a better algorithm every time. A consensus is emerging in the AI community that a large foundation model with hundreds of billions to trillions of …

Vertically Unchallenged
Components make compute and storage servers, and servers with application plane, control plane, and data plane software running atop them or alongside them make systems, and workflows across systems make platforms. The end state goal of any system architect is really creating a platform. If you don’t have an integrated …

When Nvidia Says Hot Chips, It Means Hot Platforms
Nvidia hit a rare patch of bad news earlier this month when reports started circulating claiming that the company’s much-anticipated “Blackwell” GPU accelerators could be delayed by as much as three months due to design flaws. However, Nvidia spokespeople have said things are on schedule and some suppliers say that …
Does anyone know how AWS is virtualizing the K80s? To the best of my knowledge, this is not possible on VMware due to a limitation in the amount of passthrough memory. I know of no workaround, and VMware seems not to, either…
https://cto.vmware.com/gpgpu-computing-with-the-nvidia-k80-on-vmware-vsphere-6/
Any insight would be appreciated.
The GRID K GPUs allow for such virtualization, so presumably there are features in the Teslas that are not turned on. Also, AWS has its own implementation of the Xen hypervisor, and they clearly knew how to virtualize the GPUs do to virtual desktops in the cloud. As long as the Tesla GPUs don’t stop it, it seems to me that this should just work. But again, it depends on what features in the GPU that such virtualization are dependent upon. Good question, we shall try to find out.