

The hype around generative AI is making every industry vibrate at an increasingly high pitch in a way that we have not seen since the days of the Dot Com boom and sock puppets.
With promises of more automation and significant cost savings that could come to areas like customer service, software development, and content generation, we understand the excitement around generative AI. But there also is the dawning reality that training these large language models will not just require supercomputer-class systems and massive amounts of data, but will also require securing proprietary information that can’t be allowed out the door through clever prompting.
Managing the data part – and finding how best to wrench the critical information from that data – is crucial for such workloads as analytics, machine learning, and AI. It’s that AI part that Rahul Ponnala, co-founder and chief executive officer of startup Granica, is looking at.
“AI in particular is very interesting for us because of the scale of data that you’re looking at in terms of training your models, in terms of making sure that your models are much more effective,” Ponnala tells The Next Platform. “You want to gather as much data as you can out there. You’re collecting information from text, you’re collecting information from video, audio, sensor data, what have you, depending on the vertical that you’re at, and trying to aggregate all of these things, different modalities of data, into a single data store. Unfortunately, this data store cannot be our databases, storing rows and columns. These are typically different modalities, different types of data.”
On-premises storage systems will not be able to scale to the level needed to address the amount of data needed for AI and machine learning. The go-to data stores will be object stores in the cloud – think Amazon Web Services S3, Google Cloud Storage, and Azure Blob Storage. That’s where the data action is.
Beyond scale, there are other problems enterprises face when trying to adopt generative AI, from the cost of storing the massive amounts of data in the cloud stores to accessing it, and ensuring the privacy and security around it, he says. These are the bumps on the road for enterprises that Granica is aiming to pave over. Armed with $45 million in new funding from the likes of NEA, Bain Capital Ventures, and former Tesla chief financial officer Deepak Ahuja, Granica came out of stealth recently with its cloud-native AI Efficiency Platform, which is designed to bring AI models and programs within reach of most enterprises.
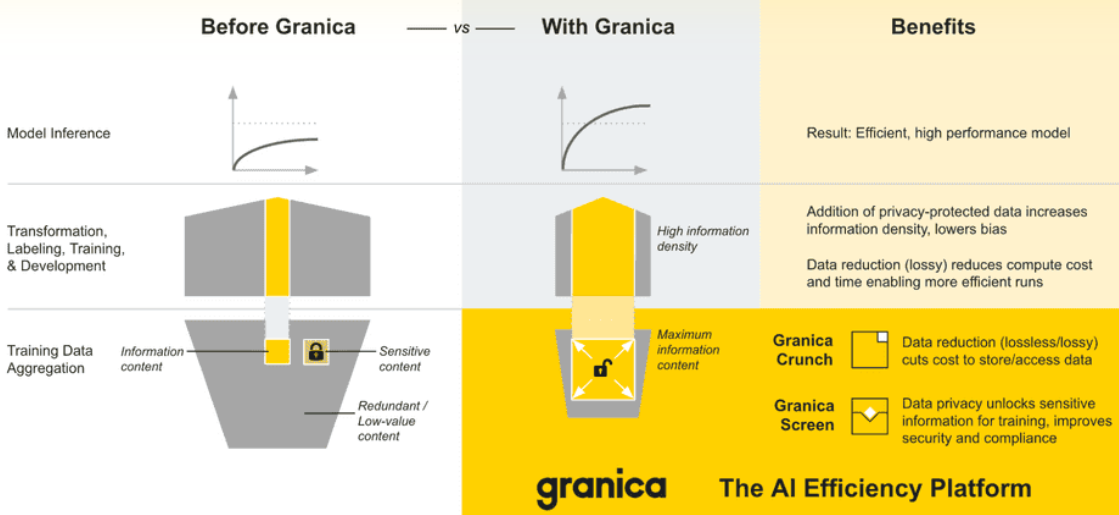
The four-year-old company is doing this through data reduction capabilities that drive down cost to store and access training data as well as reduce training time and cost, and privacy preservation capabilities that safely increase the source data available for model training in order to improve model performance.
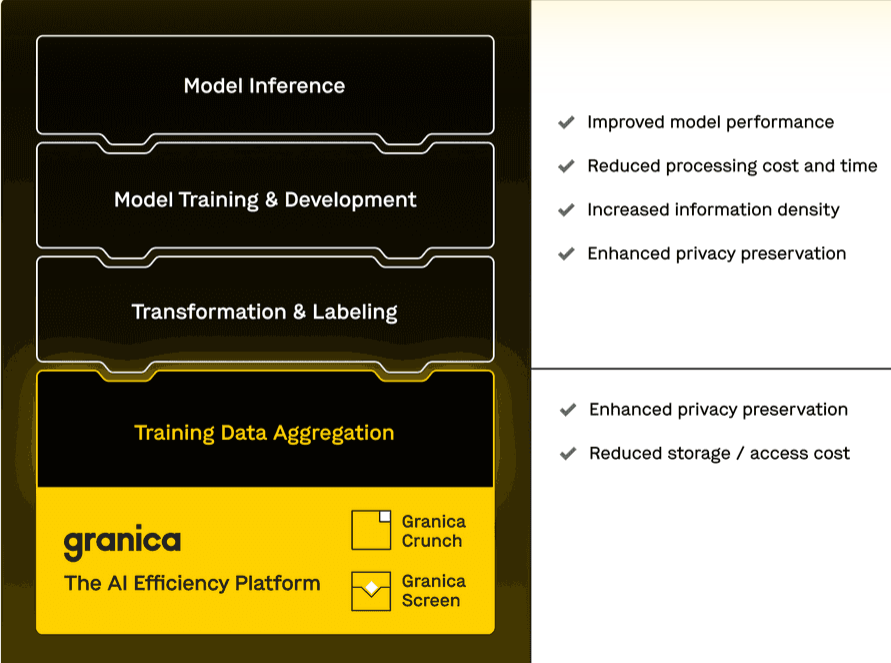
“What we basically are is a very seamless, transparent layer between your applications and your cloud object stores,” Ponnala says. “The beauty of our interface is we are compatible with S3 and Google Cloud Storage today. We will eventually also expand to other cloud object stores, which means that in a world of multicloud, you don’t need to change your applications. You just talk to Granica, a single-platform API. You can move your data between any data store in the back end. You have alleviated the problem of data gravity and we are able to do it effectively and efficiently because we are reducing the cost. We’re reducing the size of your data, which means that data, when it moves from point A to point B, from cloud object store to cloud object store, we’re able to move it much faster and cheaper because access costs in the cloud are more expensive than just storage itself.”
Along with coming out of stealth, Granica also rolled out its first two services. The first, Granica Crunch is the byte-level data reduction tool that includes compression and deduplication algorithms to reduce – losslessly – the amount of data for training AI models. The company uses statistical correlation algorithms that look at large streams of data and, based on the metadata collect, finds similarities – not always identical data – between them. Then compression and duplication is used to reduce the amount of data being pushed through the system. According to the company, all this can cut the cost for storing and transferring objects in S3 and Google Cloud Storage by as much as 80 percent and the reduce write costs by up to 90 percent.
And numbers improve over time as more data is sent through the system and the models learn the data patterns in an enterprise and figure out what redundancies can be eliminated.
The second service, Granica Screen, looks not only at metadata but also inside files to identify at a granular, field level what data is private, sensitive, or business-critical. The service is an early access program.
All this is being done through an unusual business model. Rather than have organizations pay for the services they use – the data they store, the APIs they use, and the like – enterprises pay a portion of the savings from storage costs relative to a baseline for S3 and Google Cloud Storage. The platform is free to deploy.
Granica’s initial focus dovetails with other efforts to make generative AI projects more accessible to enterprises. That includes making it easier to include proprietary corporate data into the AI model training process, something we’ve written about that includes Nvidia and its NeMo initiative. Generative AI products like ChatGPT use publicly available data – including what’s on the Internet – as the dataset it trains on. Such models become more relevant to enterprises when they are trained on company data, which also heightens the need to secure the data used in the training.
Being able to use the Granica platform to access data in any data store is important as enterprises look to build domain-specific models.
“These models are something that they can build in-house using a model provider of choice or custom build it using open source,” Ponnala says. “But we are fundamentally working at that data layer, so this becomes an invisible interface so] you don’t have to think about the protocols behind the scenes. You don’t have to think about where your data is stored. You don’t have to think about getting locked up in one data store of yours. You can use this service to basically gain fluidity and move the needle where you can gain the most value. It’s a recipe. All of this to help domain specificity.”
What Granica is doing has roots in 2006, when as an undergraduate at Jawaharlal Nehru Technology University in India Ponnala developed a Discrete Cosine Transform-based tool that distilled sets of images into their basic elements and identified ideal points for inserting cipher code. This work fueled Ponnala’s ongoing interest in the complexity of data, information extraction, and how to preserve the integrity of data while optimizing its use.
With Granica, Ponnala is trying to carve a space in the rapidly expanding AI world by tackling the data layer. Vendors like Nvidia are looking at the infrastructure side of things, while Scale AI and Labelbox do data labeling, a layer above where Granica sits. Granica is “looking at the byte streams and trying to figure out how to make those bite streams more efficient. How can you extract information from there? We can figure out what is the most information-dense dataset that will help your model achieve greater performance and only send that data to your labeling service of choice.”
The data layer is only the first step. The company has ten projects on its roadmap as it looks to spread its efficiency efforts to other parts of the AI environment. Right now, it is focusing its platform on autonomous vehicles and robotics, retail and e-commerce, and geospatial intelligence, with more industries like healthcare and financial tech on the way. Granica this week was named member of the FinOps Foundation, part of a non-profit tech consortium from The Linux Foundation for cloud financial management.


Datacenter Infrastructure Report Card, Q3 2023
It is hard to keep a model of datacenter infrastructure spending in your head at the same time you want to look at trends in cloud and on-premises spending as well as keep score among the key IT suppliers to figure out who is winning and who is losing. And …

Anthropic Fires Off Performance And Price Salvos In AI War
It is a strange time in the generative AI revolution, with things changing on so many vectors so quickly it is hard to figure out what all of this hardware and software and people-hours costs and what it might be worth when it comes to transforming, well, just about everything. …
The Next 100X For AI Hardware Performance Will Be Harder
For those of us who like hardware and were hoping for a big reveal about the TPUv5e AI processor and surrounding system, interconnect, and software stack at the Hot Chips 2023 conference this week, the opening keynote by Jeff Dean and Amin Vahdat, the two most important techies at Google, …
The cloud’s on-ramp can be so welcoming, warm-&-fuzzy, feature-full, and easy-buttoned, that one’s forgiven for overlooking its (often) Hotel-California-inspired off-ramp … I like that Granica is tackling this with lossless compression and dedupe — it should be a growing market (winning), especially as successful startups (hopefully many) progress from cloud, to Co-Lo, to on-prem (in my opinion).
Azure blog storage is a good one…