

The hyperscalers of the world are increasingly dependent on machine learning algorithms for providing a significant part of the user experience and operations of their massive applications, so it is not much of a surprise that they are also pushing the envelope on machine learning frameworks and systems that are used to deploy those frameworks. Facebook and Microsoft were showing off their latest hybrid CPU-GPU designs at the Open Compute Summit, and they provide some insight into how to best leverage Nvidia’s latest “Pascal” Tesla accelerators.
Not coincidentally, the specialized systems that have been created for supporting machine learning workloads would make excellent nodes for certain kinds of accelerated traditional HPC workloads and maybe even GPU-accelerated database jobs. What is good for one is often good for the other, and there is a certain kind of similarity between these Facebook and Microsoft systems and, say, the fat nodes that will be used as the building blocks in the future “Summit” and “Sierra” supercomputers being built by the US Department of Energy by IBM, Nvidia, and Mellanox Technologies. It is probably safe to say that the NVLink interconnect that is crucial for scaling out GPU compute capacity was designed with both hyperscalers and HPC shops in mind, but for now, it is that the hyperscalers are more enthusiastic about getting Pascal GPUs and lashing them together into a tightly coupled compute complex. They also have the benefit of having lots of budget for this, and HPC centers funded by governments and academia have some budgetary issues right now. And despite the fact that Nvidia has been peddling its own DGX-1 hybrid system since last year, that system was never intended to be a product that hyperscalers or HPC centers would buy in volumes – meaning hundreds or thousands of nodes – from Nvidia, but rather a machine that selected researchers could get Pascal GPUs early in the product rollout and jumpstart their machine learning efforts. (There are exceptions, such as the new DGX-1 cluster at Japan’s RIKEN or the one installed by Nvidia itself.)

The Facebook “Big Basin” ceepie-geepie system unveiled at OCP Summit is a successor to the first generation “Big Sur” machine that the social media giant unveiled at the Neural Information Processing Systems conference in December 2015. The Big Sur machine crammed eight of Nvidia’s Tesla M40 accelerators, which slide into PCI-Express 3.0 x16 slots and which has 12 GB of GDDR5 frame buffer memory for CUDA applications to play in, and two “Haswell” Xeon E5 processors into a fairly tall chassis.
By shifting to the SMX variants of the Pascal Teslas, which have 16 GB of HBM memory, Facebook is able to run much larger datasets inside of the Big Basin machines while at the same time putting more memory bandwidth between the CUDA cores and that HBM memory and driving more floating point math behind it. With support for half precision math, the Pascal GPUs allow for what is an effective 64 GB of memory and also quadruple the effective floating point operations possible against that larger dataset, so the machine learning models are much bigger than the 33 percent increase in raw capacity between the Maxwell M40 and Pascal P100 generations of GPU accelerators. The single precision math on the M40 is 7 teraflops, and it is 10 teraflops on the P100, so there is a matching 30 percent right there, and moving up to half precision would double it again while making the models larger, too.

With the Big Basin CPU-GPU node, Facebook wanted to break the CPU part of the compute free from the GPU part. So technically, Big Basin is not a server so much as an enclosure for GPUs – Just a Box Of GPUs, or JBOG in the lingo – just like the “Lightning” NVM-Express storage enclosure unveiled last year is Just a Bunch Of Flashes, or JBOFs, and the “Knox” and “Honey Badger” machines and the new “Bryce Canyon” arrays are Just a Bunch Of Disks, or JBODs. At the moment, Facebook is deploying the a “Leopard” server, which is based on earlier generations of Xeon processors as a head node that offloads jobs to the big Basin JBOG, but in the future it will be able to attach the new “Tioga Pass” two-socket system, which will employ Intel’s future “Skylake” Xeon processors, as the head node. This is what is meant by disaggregating the CPU and GPU compute. Now, they can be installed and upgraded separately from each other, and this is only possible if the networking between the devices is fast enough.
The Big Basin machine has motherboard designs that were inspired by Nvidia’s own DGX-1 boards, and like that DGX-1 system, it deploys the SMX2 variant of the Pascal P100 card, which has special links to hook the credit card sized module directly onto the motherboard; the other Pascal cards come in PCI-Express form factors that plug into x16 slots. The Big Basin system has two boards with four Pascal SXM2 modules each, like this:
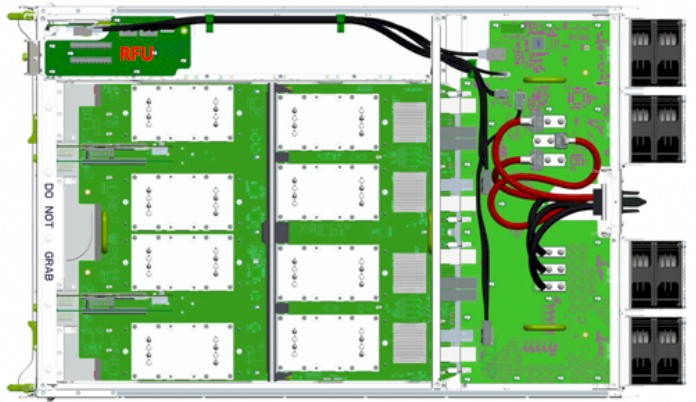
The system has four PCI-Express switches that are used to cross couple the GPUs to each other as well as to the Xeon compute complex, and by the way, the disaggregation between these two means that Facebook could swap in AMD Opteron, ARM, or Power9 processor modules and not change anything else about the system. The specs for Big Basin say that the GPU boards have to support the next generation of SXM2 cards, which means that the “Volta” GPUs will be socket compatible with the current “Pascal” GPUs, at least at the interconnect level expressed by the SXM2 module.
The GPUs use four mini-SAS connectors to bridge between the host Xeon module and the JBOG enclosure and NVLink ports are used to cross couple the GPUs to each other in a hybrid cube mesh. Like this:
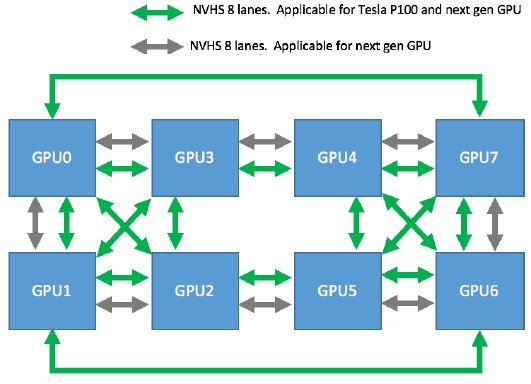
The interesting bit in the Facebook specs for Big Basin, which is built by Quanta Cloud Technology, the hyperscale division of Quanta Computer, is the statement that NVLink 1.0 ports run at 20 Gb/sec, but that the next generation NVLink 2.0 ports “could have SERDES running up to 25.78125 Gb/sec.” That is a pretty precise “could,” and indeed we know that the NVLink 2.0 ports as well as the more generic “Bluelink” ports on the Power9 processor all run at 25 Gb/sec. The fun bit in that NVLink topology chart shown by Facebook is that it shows Pascal GPUs having four NVLink 1.0 ports each, but that the Volta GPUs will have six NVLink 2.0 ports. This will allow for more cross coupling, and tighter linking, between GPUs, as well for greater scale for NVLink clusters that do not need the tightest coupling.
Facebook has two different topologies inside of the Big Basin machine that it can set by flipping jumpers in the retimer cards in the PCI-Express switch setups. Here is topology one:
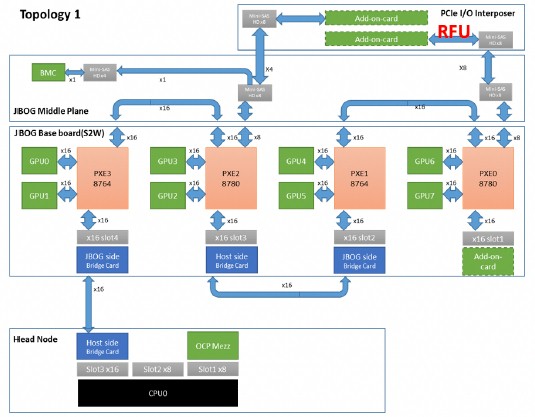
And here is topology two:
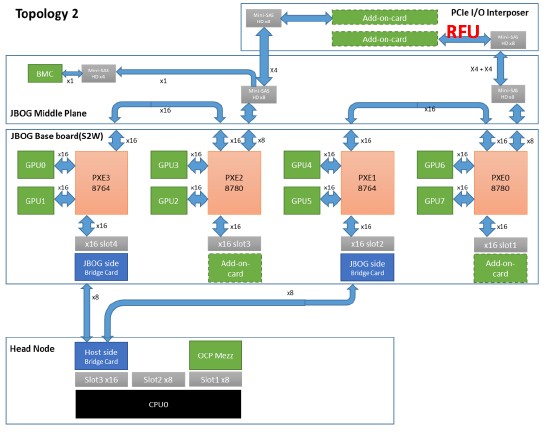
The big difference is having one x16 pipe or two x8 pipes coming off the GPU complexes, and it is not obvious why this makes such a big difference.
“In tests with the popular image classification model Resnet-50, we were able to reach almost 100 percent improvement in throughput compared with Big Sur, allowing us to experiment faster and work with more complex models than before,” explains Kevin Lee, an engineer who worked on the Big Basin design. Facebook is training at single precision, obviously, so it does not see as big of a jump as it would have had it been training at double precision and moving to half precision.
Enter The HGX-1
Over at Microsoft, the ceepie-geepie box unveiled at OCP Summit has been developed in conjunction with Ingrasys, a maker of OpenPower platforms that is a subdivision of giant contract manufacturer Foxconn. Microsoft is open sourcing the design of its machine learning box as the HGX-1 through the OCP, and hopes to establish this as a standard that many other companies employ for machine learning training models. And, as we pointed out above, the HGX-1 machine would probably make a good fat node for a supercomputer cluster if the Message Passing Interface (MPI) protocol could be grafted properly onto NVLink and PCI-Express with some kind of hierarchy.

Like the Big Sur box, the HGX-1 variant of Microsoft’s Project Olympus open source servers has support for eight of the Pascal SXM2 GPU modules, and it also uses PCI-Express interconnect to link the GPU processing complex to the Xeon compute complex in the system.
The speeds and feeds of the topology of the HGX-1 system were not available at press time, but Ian Buck, vice president of accelerated computing at Nvidia, tells The Next Platform that the HGX-1 system has a cascading set of PCI switches inside the box and across multiple boxes. Within a box, this PCI-Express switching complex allows one of the two Xeon processors in the system to dynamically address one, four, or eight GPUs directly, which are then allowed to share data very closely over virtual memory using NVLink that is implemented in the same hybrid cube mesh that the DGX-1 and Big Basin systems use. Microsoft is extending this PCI-Express mesh so it can be used to link as many as four HGX-1 systems together and allow for any of the eight Xeon processors in the complex to access data across 32 of the Pascal P100 SXM2 modules, effectively quadrupling the memory and compute capacity of the HGX-1 node using Microsoft’s own CNTK open source machine learning framework.
While Microsoft is engineering the HGX-1 initially to support the Nvidia Pascal compute modules and no doubt has made the future proof and able to take the Volta modules, don’t get the wrong idea. Microsoft is keeping its options open.
“The chassis for the HGX-1 is optimized for Nvidia GPUs,” Leendert van Doorn, distinguished engineer for Microsoft’s Azure public cloud, tells us. “But there is no reason why it can’t support AMD Radeon GPUs or Intel Nervana machine learning chips.”




Be the first to comment