

Today is the ribbon-cutting ceremony for the “Venado” supercomputer, which was hinted at back in April 2021 when Nvidia announced its plans for its first datacenter-class Arm server CPU and which was talked about in some detail – but not really enough to suit our taste for speeds and feeds – back in May 2022 by the folks at Los Alamos National Laboratory where Venado is situated.
Now we can finally get more details on the Venado system and get a little more insight into how Los Alamos will put it to work, and more specifically, why a better balance of memory bandwidth and compute that depends upon it is perhaps more important to this lab than it is in other HPC centers of the world.
Los Alamos was founded back in 1943 as the home of the Manhattan Project that created the world’s first nuclear weapons. We did not have supercomputers back then, of course, but plenty of very complex calculations have always been done at Los Alamos; sometimes by hand, sometimes by tabulators from IBM that used punch cards to store and manipulate data – an early form of simulation. The first digital computer to do such calculations at Los Alamos was called MANIAC and was installed in 1952; it could perform 10,000 operations per second and ran Monte Carlo simulations, which use randomness to simulate what are actually deterministic processes. Los Alamos used a series of supercomputers from IBM, Control Data Corporation, Cray, Thinking Machines, and Silicon Graphics over the following four decades, and famously was home of the petaflops-busting “Roadrunner” system built by IBM out of AMD Opteron processors and Cell accelerators, which was installed in 2008 and which represented the first integration of CPUs and accelerators at large scale.
More recently, Los Alamos installed the $147 million “Trinity” system in 2015, comprised of Intel Xeon and Xeon Phi CPUs from Intel with a combined 2 PB of memory and Intel 100 Gb/sec Omni-Path interconnect. Trinity was noteworthy because offloading the results of calculations from that large amount of memory required a burst buffer so the machine could keep on calculating. The replacement for Trinity, which was installed in August 2023, is the “Crossroads” supercomputer, which is based on Intel’s “Sapphire Rapids” Xeon SP processors with HBM2e stacked memory and HPE’s Slingshot interconnect.

Both Los Alamos and its neighbor Sandia National Laboratories have been eager to foster the creation of Arm servers that can be clustered into supercomputers, and Los Alamos has been driving the memory bandwidth per core with the ill-fated ThunderX4 Arm server project at Cavium (and then Marvell). Neither the “Triton” ThunderX3 or the ThunderX4 ever saw the light of day, and so Los Alamos cajoled Intel to create the HBM variant of Sapphire Rapids, and also did its part in convincing Nvidia to create the “Grace” CG100 Arm server chips that is paired with its current “Hopper” GH100 and GH200 GPU accelerators and, soon, its future “Blackwell” GB100 and GB200 accelerators.
On The Hunt For The Memory Stag
Venado which means deer or stag in Spanish and is also the name of a peak in New Mexico’s Sangre de Cristo mountains, and that is where the new machine gets its name. As you might expect, Hewlett Packard Enterprise is the prime contractor on the system, and as we expected, the system does not make use of the NVLink Switch shared memory interconnect for GPUs that Nvidia has created to make superpods of shared memory GPUs.
There was some talk two years ago when the Venado system architecture was being formalized that Los Alamos might want to use InfiniBand, not HPE’s Slingshot variant of Ethernet, inside of a Cray “Shasta” XE supercomputer system with Grace-Grace and Grace-Hopper compute engines, but as it turns out, Los Alamos is deploying 200 Gb/sec Slingshot 11 interconnects. Our guess? HPE Slingshot 11 with 200 Gb/sec per port is a whole lot cheaper than Nvidia Quantum 2 InfiniBand with 400 Gb/sec ports.
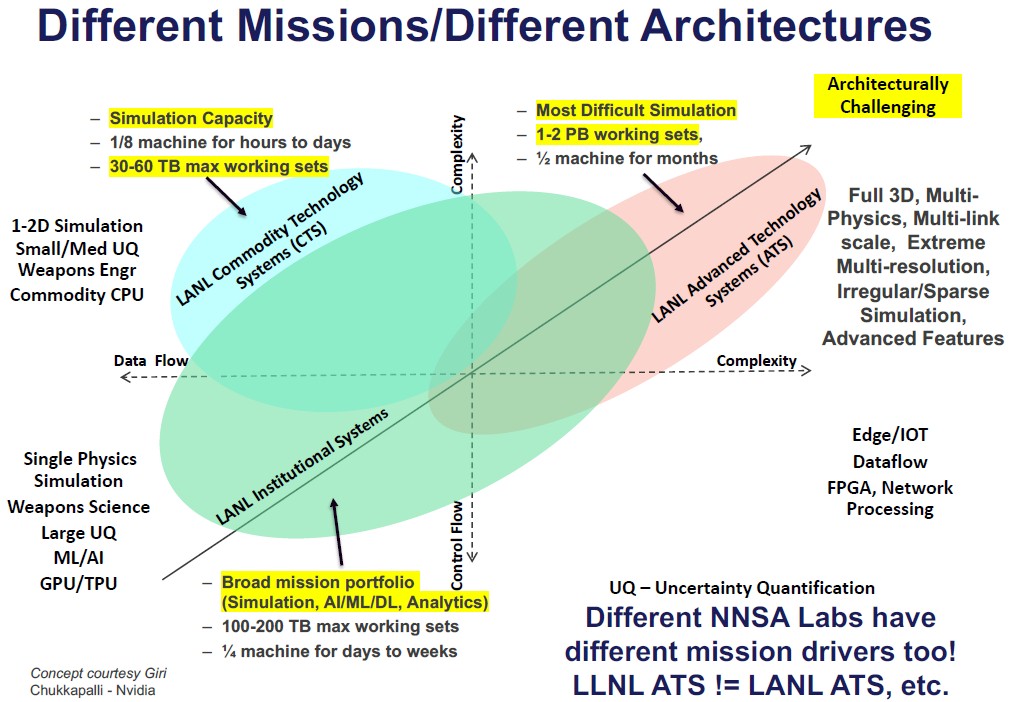
The new Venado system is not a workhorse machine in the Los Alamos fleet, but an experimental one that is built from its own budget and for the express purpose of doing hardware and software research. Most of the machines that Los Alamos acquires are proposed, built, accepted, and put immediately to work on workloads for the National Nuclear Security Administration that manages the nuclear weapons stockpile for the US military.
Back in May 2021, here is what we knew about Venado officially from the announcement:
We also learned from talking to Jim Lujan, HPC program manager, and Irene Qualters, associate laboratory director of simulation and computation at Los Alamos, that the basic idea was to do an 80/20 split on compute cycles between the two architectures. Meaning 80 percent of the flops would come from the GPUs (and we assumed this was done at FP64 precision to carve the compute pie up) and 20 percent would come from the GPUs.
Considering that in regular GPU-accelerated machines, 95 percent to 98 percent of the flops are coming from GPUs, this Venado machine looked quite a bit heavier on the CPU than you might otherwise expect. For good reason, as Gary Grider, HPC division leader at Los Alamos for the past two and a half decades and, among many other things, the inventor of the burst buffer, tells The Next Platform.
“Our applications are these incredibly complex multiphysics, multi-link scale, extreme multi-resolution, incredibly complex packages with millions of lines of code that run on half the machine for six months to get an answer,” Grider explains. “That’s normal for us, which is not true of many other Department of Energy labs, if any. They might do it as an unusual thing, but not normally. The reason that it takes six months to run those applications is because the access to memory is so incredibly sparse and irregular because of the complexity of what they are trying to do – the applications re trying to run a problem that is 50 times bigger than the machine. And so that ends up being the driver for the kinds of machines we buy for our simulation environment because we have these needs. And it ends up being the reason why we don’t buy very many GPUs because GPUs are really good if you can do dense linear algebra. But if you are doing everything sparse and irregular, and everything is an index lookup and the like, then they are no better than the CPU, really. It is truly more about how much memory bandwidth you can buy per dollar than it is about how many flops you can buy.”
It was convenient, perhaps, that the hyperscalers and cloud builders running deep learning recommendation systems (DLRMs) on GPUs also needed a way to cache larger amounts of embeddings for those recommenders than could be held in the GPU HBM memory, and the answer Nvidia came up with was Grace, a glorified, computational memory controller for an additional 480 GB of LPDDR5.
What is not a coincidence, perhaps, is that two 72-core Grace chips connected by NVLink ports formed into a superchip has 960 GB of memory capacity and 1 TB/sec of memory bandwidth into those Arm “Demeter” V2 cores etched into the Grace chip. And thanks to four 128-bit SVE2 vector engines per V2 core, the Grace-Grace superchip can deliver 7.1 teraflops of aggregate peak FP64 compute all by themselves. Under normal circumstances, when the GPUs are doing most of the compute, you would have thought Nvidia would use less heavily vectored “Perseus” N2 cores from Arm. We think Los Alamos in the US and CSCS in Switzerland with the “Alps” system, pushed Nvidia to go with the V2 cores. And thanks to the relatively few cores in the Grace CPU, the relatively cheap and low-power LPDDR5 memory, and the relatively fat 480 GB of available memory, Grace has a good balance of memory bandwidth per core and low cost per unit of memory bandwidth.
The Grace CPUs, which we detailed here, have sixteen LPDDR5 memory controllers each with a total of 546 GB/sec of memory bandwidth and 512 GB of capacity. The delivered version of Grace has only 480 GB of memory and only 500 GB/sec of bandwidth. Go figure. The two CPUs in a Grace-Grace superchip are linked to each other coherently over a 900 GB/sec NVLink chip-to-chip implementation (C2C in the chiplet lingo). That same NVLink C2C interconnect is used to hook a Grace CPU to a Hopper GPU with 80 GB or 96 GB of HBM3 or 141 GB of HBM3E capacity, depending on which model you buy.
Anyway, based on what we knew about Grace and Hopper back in May 2022 and doing an 80/20 split on compute, we did some back of the envelope math and figured you would need 3,125 Grace-Hopper nodes and around 1,500 Grace-Grace nodes. The Grace CPUs have more FP64 oomph than many expected – again, we think this is intentional and driven by HPC customers, not AI customers – and the upshot is that the actual Venado system has 2,560 Grace-Hopper nodes and 920 Grace-Grace nodes.
If you do the math on that, there are a total of 316,800 Grace cores with a total of 15.62 petaflops of peak FP64 performance. The Grace CPUs in the Venado nodes have a total of 2 PB of main memory. (Huh, do you think that is a coincidence? We don’t. It is the same amount of memory as the Trinity system.) That LPDDR5 memory has an aggregate of 2.1 PB/sec of bandwidth.
There are 2,560 Hopper GPUs in the box, with a combined 85.76 petaflops of FP64 performance on the vector cores and 171.52 petaflops of FP64 performance on the tensor cores. That’s 92 percent of FP64 on the Hoppers and 8 percent on the Graces if you use the tensor cores on the H100s, but it is 85 percent on the Hopper if you only use the vector cores. We presume that those Hopper GPUs have 96 GB of HBM3 memory each, for a total of 240 TB of HBM3 memory and 9.75 PB/sec of aggregate bandwidth. If you do the math further, then 81 percent of the memory bandwidth of the machine is on the Hopper GPUs but an amazing 19 percent is on the Grace CPUs.
As part of the contract with HPE, the Venado system will be equipped with a Lustre parallel storage cluster that resides on the Slingshot network, and Grider says that Los Alamos is looking to also try out the DeltaFS file system and perhaps others with the machine.
Grider says that Venado is installed and running now, and acceptance should come in the next two months “unless there’s some gotcha that happens sometimes,” and there should be lots of applications running on the experimental machine by July or so.


HPE’s Ungaro On Delivering Exascale For The Masses
When Hewlett Packard Enterprise finally closed on its $1.3 billion acquisition of supercomputer maker Cray in September, it was just over a month after the US Department of Energy announced Cray had completed a sweep in the country’s initial push into the exascale computing era. The veteran high performance computing …

NOAA Gets 3X More Oomph For Weather Forecasting; It Needs 3,300X
UPDATED* Until exascale supercomputers get a lot cheaper, which will allow weather forecasting models to run at a much smaller resolution – and more frequently – to deliver hyper-local weather forecasts, the actual weather forecasting is still going to be done by people. They will be armed with ever-improving models …
HPE Adapts Boosted Alletra Storage For GreenLake Utility Consumption
Nearly two years ago, Hewlett Packard Enterprise rolled out a new battle plan for storage and a new kind of storage array to implement it. This week, that new storage array – the Alletra line, one of the fast-growing part of the HPE business – is getting a “Sapphire Rapids” …
Monte Carlo is used to simulate random processes. In fact, it could be argued that you have it exactly backwards, as the numbers used in Monte Carlo are usually not random at all, but pseudo-random (aka deterministic).
A Monte Carlo method may be used to find a numerical approximation for a deterministic model. An example: Pi is a mathematical constant. The area of a circle is deterministic. The area, A, of a circle is uniquely determined by its radius, r, with the formula A = pi*r^2. By (pseudo)randomly sampling points from a uniform distribution from a square with side length r and testing whether they are inside or outside a circle inscribed in the square, one can find a numerical approximation of the area of the circle with radius r by multiplying the area of the square, r^2, by the fraction of points found to lie inside the circle. Noting the area formula for the circle, A = pi*r^2, the fraction of points found to lie within the circle yields an approximation of pi.
I do believe that is what I said originally without being anywhere near as precise. Monte Carlo is a kind of magic as far as I am concerned. It is an approximation, and sometimes nature is perhaps a bit more precise than we are. But that you can take randomness and do predictions at all is the amazing thing.
“Monte Carlo simulations, which use randomness to simulate what are actually deterministic processes”
Yes, it is pretty much used like that at Sandia and LANL, as a technique for uncertainty and sensitivity analysis in cases where parameters, driving forces, or initial conditions are known “imprecisely” in what are otherwise deterministic processes (say if a key model parameter’s value is known to be 4.57 ± 0.03). They also developed a Latin Hypercube Sampling (LHS) method and software to make such analyses more efficient (SAND2001-0417 at: https://www.osti.gov/biblio/806696/ ).
Great to see that Santa’s red-nosed rocket sleigh is now officially gambolling about, even as LANL elves get it ready for acceptance of upcoming christmas-present workloads! Its trendy heterogeneous configuration is wildly reminiscent of recent partitioned animals grazing in this field, like the Mare Nostrum 5 GPP (CPU only) and ACC (CPU+GPU). It does seem a bit smaller though (as wild deer can be relative to mares?), with its 316,800-strong slender-yet-gracious core (vs 725,760 for the GPP mare’s xeons; and also 660,800 xeon max’s at the LANL Crossroads).
Its PF/s 101 (15.6+85.8) could prove an interesting intro into heterogeneous gift delivery, seeing (for example) how a hopper full of Oh’Henri’s chocolate bars was the #1 Green500 favorite last year (yummy!). More to the point though, its targeted ability to efficiently graze through sparsely distributed North Pole tundra lichens should directly translate into great performance at dispatching christmas lumps of coal to the equally sparse naughty kids of the world! With 1.5x as many cores as Japan’s meteorological twins (PRIMEHPC FX1000), one may expect a top 20 or better 0.7 PF/s standing for this HPCG task, somewhat similar to the Wisteria’s Odyssey, but with a potential boost from the rocket engines of its matrix hoppers (helping it hop-along quicker!).
All in all a quite interesting animal, sure to be more power-thrifty than its upcoming Swiss cheese cousin from the Alps, itself better adpated to the dense grassy pastures found there (running at 445 PF/s in this ecosystem), but likely somewhat equivalent in sparse tundras (IMHO)! Cant’ wait to see its blinking red nose in the sky! 8^b
It is about having more memory per core and much lower cost per memory bandwidth, I think.
Maybe Intel and AMD should have LPDDR5 Xeons and Epycs with a 16 or 24 memory controllers as an option? Or even 32 or 48 using Eliyan PHYs? How much work could a CPU with proper memory configuration with lots of vector and matrix engines do? I am gonna have a think about this….
If HPC and making LANL happy was Intel’s objective, they obviously would have this. LANL has been asking for memory bandwidth ahead of flops for decades. The problem is they’re willing to spend hundreds of millions on these sorts of machines, but not tens of billions.
Can intel (or AMD) develop something like that for 2-3 customers?