

Many have tried, but few parallel file system upstarts have challenge the dominance of Lustre, and to a lesser extent these days, GPFS/Spectrum Scale. It does not seem to be just a matter of open source versus proprietary, but tradition and function. And while both most-used file systems in HPC have evolved with the times, the demands of exascale are pushing entirely new ways of thinking.
Upstarts like WekaIO, BeeGFS, and Vast Data, among several others, have sought to carve out a slice of the pre-exascale share while centers like NERSC have taken bleeding-edge systems and paired them with massive Lustre installations, despite the hard work involved.
One emerging file system, developed specifically for the unique requirements of exascale systems and a new breed of mixed workloads, might have a chance at gaining ground. This is in part because of its capability and in another part because of its pedigree.
Los Alamos National Lab storage and HPC leads, Gary Grider and Brad Settlemyer are well known in the world of supercomputing I/O with innovations ranging from burst buffers, computational storage, file system enhancements and more. They have been developing the new exascale file system, dubbed DeltaFS, in conjuction with the Parallel Data Lab at Carnegie Mellon (with PanFS creator, Garth Gibson) among other institutions. This lends the effort some serious credibility of the gate and the open source approach further solidifies the potential role of DeltaFS in some upcoming extreme-scale HPC environments.
The creators say the high cost of global synchronization for strong consistency is extreme-scale environments is one of the primary motivating factors, along with gaps in what’s available in existing file systems for scaling metadata performance. By adding these and other missing pieces, they say they can realize “the promise of a relaxed “no ground truth” parallel file system for non-interactive large-scale HPC, getting us out of the one-size-fits-all approach/modify to suit approach that’s fit the bill for so long.
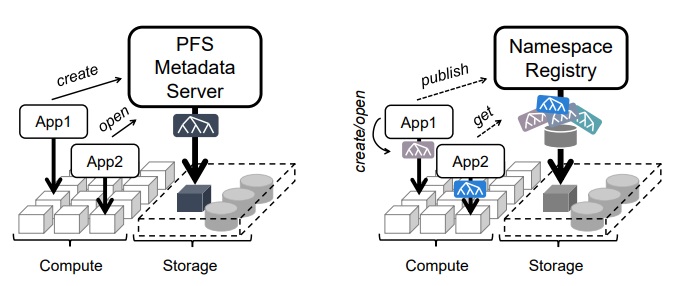
The metadata performance scalability issue is one several storage upstarts have claimed to tackle but it’s not a simple problem to untangle and seems to require a fresh start. Most metadata services now use dynamic namespace partitioning across several such servers. Each of these servers is handling its own slice of the file system’s namespace. The problem is, this approach partitions global synchronization capabilities. It’s also not cheap—each of these requires a dedicated metadata server, even though all of them might not be required for some applications and there’s no way to tell in advance. This is inefficient and performance-wise can cause other problems.
DeltaFS is trying to kill multiple birds with one stone: by targeting metadata scalability/performance and the global synchronization problem, they’re solving some of the most pressing issues for exascale I/O.
Architecting this around the idea that workloads can no longer be generalized in large-scale HPC is a bonus outcome. “While the high cost of global synchronization will continue to be necessary in cases where the applications use the filesystem to communicate, it is also important to realize that many of today’s parallel applications are no longer a group of laboratory scientists sharing their text files. Instead, they are for the most part non-interactive batch jobs that do not necessarily benefit from many of the semantic obligations that early network filesystems carried in their computing environments,” the creators explain.
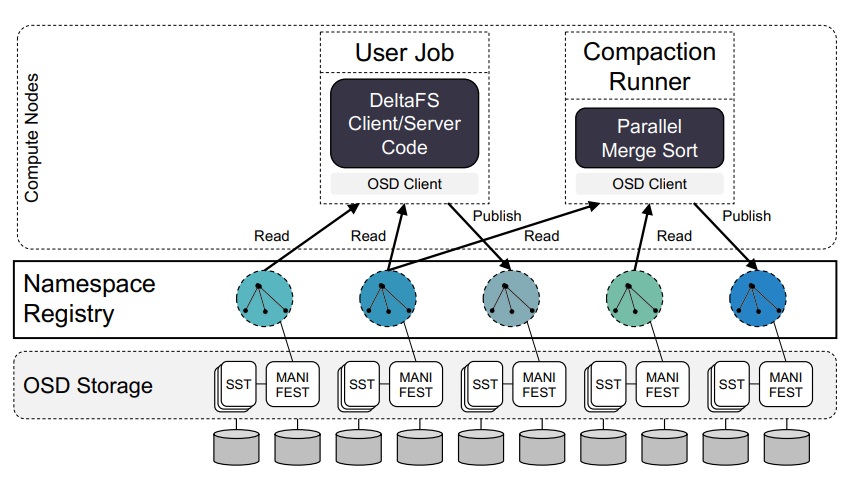
A DeltaFS cluster consists of per-job DeltaFS client/server instances and dynamically instantiated compaction runners on compute nodes reading, merging, and publishing filesystem namespace snapshots to a public registry that maps snapshot names to snapshot data stored in a shared underlying object store.
Imagine a public namespace registry where jobs publish their namespaces as a series of snapshots. When each job starts, it selects a subset of these snapshots as input and ends by publishing a new snapshot comprising all of the job’s output. This new snapshot can then be used by an interested followup job to serve as its input, achieving efficient inter-job data propagation.
DeltaFS is based on the premise that at exascale and beyond, synchronization of anything global should be avoided. Conventional parallel filesystems, with fully synchronous and consistent namespaces, mandate synchronization with every file create and other metadata operations. This has to stop. Moreover, the idea of dedicating a single filesystem metadata service to meet the needs of all applications running on a single computing environment, is archaic and inflexible. This too must stop.
The creators say that DeltaFS shifts away from constant global synchronization and dedicated filesystem metadata servers, towards the notion of viewing the filesystem as a service instantiated at each process of a running job, leveraging client resources to scale its performance along with the job size. Synchronization is only used (depending on the needs of followup jobs) and this is managed through an efficient, log-structured format that lends itself to deep metadata writeback buffering and merging
“DeltaFS does not provide a global filesystem namespace to all application jobs,” the creators add. “Instead, it records the metadata mutations each job generates as immutable logs in a shared underlying object store and allows subsequent jobs to use these logs as “facts” to compose their own filesystem namespaces without requiring a single global ordering for all logs and without requiring all logs to be merged. Enabling jobs to choose what they see prevents unnecessary synchronization on top of a large computing cluster. A smaller filesystem metadata footprint per job further improves performance.”
WekaIO and others have come up with their own object storage/cloudy way of bringing metadata performance and scalability to HPC but for this particular set of users, open source is generally looked upon more favorably. There have been significant modifications to Lustre to make it even more robust at scale and with mixed files, but it takes a lot of investment internally at the labs to make Lustre jump through these hoops.
The question is whether the HPC community is ready to rewrite the way it thinks about I/O. It seems pressing to do so with the addition of so many all-flash installations to feed pre-exascale and future exascale machines. Perhaps starting with someone that is architected for what’s to come versus tacking onto what’s come (decades) before is the way, but time will tell.
Benchmarking and in-depth descriptions can be found here.


Divide Deepens Between HPC and Enterprise Storage
The more things change, the more they stay the same in HPC storage. But for the broader enterprise world, the more things stay the same, the quicker companies are to seek out change. As long as it’s easy to manage and provides reliability, cost is not at the top of …

Blazing The Trail For Exascale Storage
When it comes to advanced technologies at the high end of compute, networking, and storage, Lawrence Livermore National Laboratory is one of the world’s pathfinding testbeds. Trying new things at scale is a big part of the mandate for the lab, which among other things, is the US Department of …

Intel Targets DAOS Object Storage At More Than HPC
Intel is looking to position itself as a leader in AI and HPC through a holistic approach that plays to the company’s strengths across a broad swath of the IT ecosystem. This covers not just silicon hardware such as CPUs and ASICs, but also the firm’s expertise in open software …
Be the first to comment