

When Hewlett Packard Enterprise finally closed on its $1.3 billion acquisition of supercomputer maker Cray in September, it was just over a month after the US Department of Energy announced Cray had completed a sweep in the country’s initial push into the exascale computing era. The veteran high performance computing company was awarded the $600 million contract to build “El Capitan,” an exascale-class supercomputer built on its new Shasta systems and integrated Slingshot interconnect and which will be housed in the Lawrence Livermore National Laboratory sometime in late 2022. Cray already was contracted to build the other two exascale supercomputers – “Aurora” at Argonne National Laboratory and “Frontier” at Oak Ridge National Laboratory, both Shasta systems and due next year.
As we wrote when the El Capitan announcement came down last year, there were other OEMs in the running for the contract, including IBM, which already had built the two major pre-exascale supercomputers – the massive “Summit” system at Oak Ridge and”Sierra” at Lawrence Livermore – and possibly HPE, which was rumored to have bid its own systems for the exascale systems. (Summit and Sierra were part of the CORAL-1 supercomputers; El Capitan, Frontier and Aurora are part of the CORAL-2 initiative.)
HPE made its way in through its acquisition of Cray, a deal first announced in May 2019. HPE was no stranger to HPC – it ranked number five on the of vendors with systems on the November 2019 Top500 list with 35 supercomputers, one behind Cray. Combined the two would have tied Chinese company Sugon for second with 71 (behind Lenovo, at the top of the list with 174 systems). A couple of months after buying Cray, HPE issued a statement talking about how the addition of Cray enabled it to offer complete HPC systems and added to its capabilities and expertise in artificial intelligence (AI)-based solutions. As we wrote when the deal was first announced, HPE had reached the top of the HPC space, though in unconventional fashion.
Also in that statement after the deal closed, HPE also spoke about the ability to now more widely open up HPC to an enterprise space that is being inundated with data and emerging workloads like AI and analytics, and deliver those capabilities on premises, in the cloud or as a service. “Now every enterprise can leverage the same foundational HPC technologies that power the world’s fastest systems, and integrate them into their data centers to unlock insights and fuel new discovery,” it read.
The Enterprise And HPC
Six months later, that view still holds true. To Peter Ungaro, former Cray CEO and now senior vice president and general manager of HPE’s HPC and AI business, the future of HPC is exascale, including the massive systems that the company is putting together for the national labs. It also can be seen in the efforts other countries, including China, Japan and the European Union are making to bring out their own exascale-class supercomputers that are expected to begin going int production between 2021 and 2023, and the expected jolt of spending exascale is expected to give the HPC space in general.
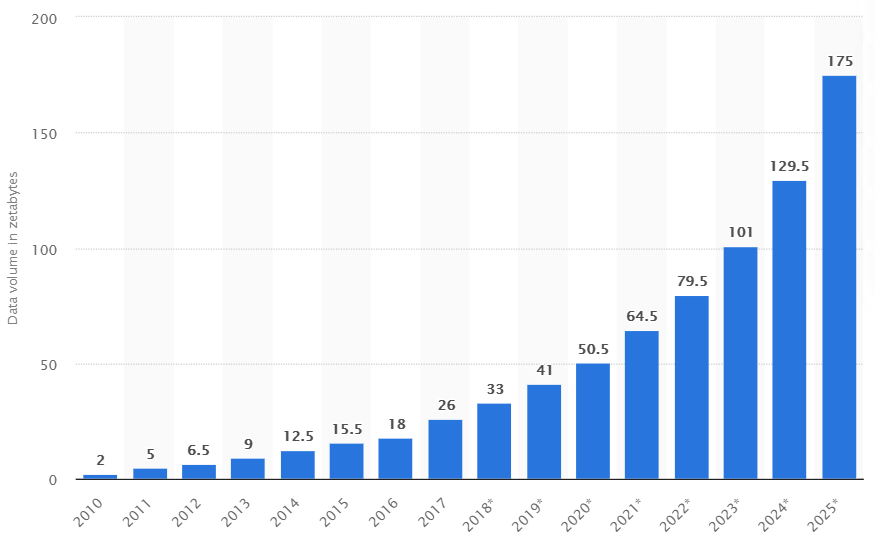
However, when Ungaro talks about the exascale era in HPC, he focuses on what it will mean for enterprises, which are desperate for more computing power to help them run modern AI and HPC-type workloads and manage and analyze the huge amounts of data that are being generated. Inside all that data is information crucial for making informed business decisions and for more quickly rolling out products and services for their customers. As the chart from Statista below shows, the amount of data generated worldwide in 2020 is expected to hit 50.5 zettabytes. In 2025, 175 zettabytes will be created.
“The exascale systems have spawned a whole new set of technologies, both hardware and software technologies, that are in the process of being developed for these exascale systems that will be leveragable by everyone,” Ungaro tells The Next Platform. “A lot of times people feel that these very large systems at the top of the supercomputing pyramid are kind of irrelevant for them, but I really believe in the future that pretty much every company – especially every company of size, so say like Global 1000 company and even many small businesses that are more focused from a technology perspective – will have a system in their datacenter that will look and feel very much like a supercomputer and have the same kinds of technologies that a supercomputer today has in it, just because of the tremendous expansion of the amount of data that people are dealing with, which is creating bigger computing problems.”
Trickle Down Of Exascale
An example is the “Slingshot” interconnect introduced by Cray in 2018 with the Shasta systems. The interconnect starts at 200 Gb/s throughput and includes the ability to manage traffic congestion that enables improved performance and scale when running data-intensive workflows on a single system. At the same time, it’s based on an Ethernet ASIC that can easily communicate with the Ethernet that is running in datacenters around the globe. Slingshot “will work with very open technologies, [like] Ethernet,” Ungaro says. “It will be able to attack the highest performance, highest scale problems on the planet. So taking a commodity technology like Ethernet and being able to scale that and leverage that to the highest level of performance, this is very important, because if it was proprietary, not a lot of companies will be willing to use that.”
He also pointed to the work in software HPE is doing. In the acquisition, HPE inherited the Cray Programming Environment (CPE), aimed at developers and administrators that need to manage HPC and AI workloads that leverage multiple processors and accelerators. CPE provides a range of compliers, programming languages, tools and libraries and gives developers flexibility in porting applications and transition to new hardware. In addition, HPE brought its Performance Cluster Management (HPCM) software, which enables provisioning, management and monitoring to clusters of up to 100,000 nodes, with new versions of the software extending support to new Cray systems.
“We’re in the process of completely revolutionizing our entire software stack and really making it more cloud-enabled, so micro services-based [software], containers, Kubernetes, really a cloud-like system,” he says. “We’re trying to build supercomputers so they look and feel like they’re from the cloud, but they scale and run and perform like a supercomputer. We’re really blending those two worlds … to make them much more broadly applicable [to enterprises] than supercomputers in the past.”
HPE is adding Cray supercomputers to its lineup of high-density Apollo systems aimed at enterprises. The company over the past several years has been expanding the range of these servers to enable enterprises more easily adopt and run AI and HPC applications. Adding Cray into the mix will give organizations even more options, ranging from a single server to supercomputers, all based on the Shasta architecture.
The combined company also is reaching into the cloud with its supercomputing capabilities, building on the partnership Cray has with Microsoft to offer managed supercomputers in the Azure cloud and administered by Cray.
A Hybrid World
“Much the world is going hybrid, where you’ll have some computing on the cloud, you’ll have some in your in your datacenters, you’ll have some in third-party datacenters that you won’t manage, that others – like HPE, for instance – would manage for you,” Ungaro says. “That’s a huge part of how we see things going forward. Clearly, the kind the architecture of an HPE supercomputer today is very different than the architecture that you get in the cloud. It’s much more tightly integrated, it’s much more tightly connected. For instance, we have a partnership with the Azure team of putting a Cray supercomputer up on the Azure cloud, because it’s a very different resource than the rest of the resources in Azure, AWS [Amazon Web Services] or Google or any of the major cloud guys.”
In these hybrid environments, it’s more about the application than the location, he says.
“I really don’t see as much of a decision point from, ‘Do I want it on premises or in the cloud?’” Ungaro says. “I see it more from a perspective of what kind of architecture should these applications run on. Does it need a more tightly connected, high-bandwidth, scalable infrastructure, or does it fit nicely on a loosely coupled, more-commodity style architecture? Then you put those applications where they best fit and then you make a decision, a business decision, whether you want those resources in the cloud or on-prem.”
The key is ensuring that wherever the application goes, it can run on HPE supercomputing technology. True exascale machines will only be available to a few people, he says. However, the technology being built for these systems will be more widely available.
“The technologies that we’re building for those exascale machines will be leveraged all the way down to a single cabinet in a datacenter or even a single server that’s in a data center,” Ungaro says. “The real driver is the growth of data. Then when you look at the way that processors and GPUs and accelerators and deep learning accelerators and all these different processing technologies are moving, the biggest thing that we need to do is to figure out how we take all of those and put them together into a tightly integrated package so that we can have a high-bandwidth, bandwidth-rich environment for people to compute on that need to compute on tightly coupled applications, which is a lot of applications today. We used to talk about technology comes in at the high end and then over three or five years waterfalls down into lower levels of computing. I don’t really think that ever happens so much anyway, but what I see is that you’re developing these technologies now to take advantage of the processing technologies and the system-level technologies and the huge growth in data that’s taking place. Being a leader in an high-performance computing and supercomputing and being the company that a lot of the exascale technology systems are going to be based on, we’re in a perfect position to take advantage of what’s going on.”

The Edge Propels HPE While Datacenter Taps The Brakes
Customers of Hewlett Packard Enterprise have one foot on the gas and one foot on the brakes at the same time that the company is transitioning from selling gear outright to customers to selling them subscriptions that spread the cost – and therefore HPE’s recognized revenues – out over time. …

Mixed Results For The Datacenter Thundering Thirteen In Q4
We have been tracking the financial results for the big players in the datacenter that are public companies for three and a half decades, but starting last year we started dicing and slicing the numbers for the largest IT suppliers for stuff that goes into datacenters so we can give …
Companies Need On-Premise HPC – And For More Than AI, Too
Generative AI and the various capacity and latency needs it has for compute and storage is muscling out almost every other topic when conversations turn to HPC and enterprise. Intel, AMD, Nvidia, Arm, and other chip makers are boasting about what their latest products can do for AI workloads, cloud …
Be the first to comment