

If you handle hundreds of trillions of AI model executions per day, and are going to change that by one or two orders of magnitude as GenAI goes mainstream, you are going to need GPUs. Lots of GPUs. And apparently Meta Platforms does, and it is getting out its big, fat checkbook and writing a number with lots of digits on the left side of the decimal point to Nvidia.
Back in January, Mark Zuckerberg, chief executive officer at social network and AI innovator Meta Platforms, floated out some numbers in an Instagram post that showed the company was going to be making a massive investment in GPU accelerators this year – including a whopping 350,000 Nvidia “Hopper” H100 GPUs as well as other devices – as the company pursued artificial general intelligence, or AGI.
You know, thinking machines.
At the time, Zuckerberg said that by the end of 2024, Meta Platforms would have a fleet of accelerators that had the performance of “almost 600,000 H100s equivalents of compute if you include other GPUs.”
Now, the techies inside of Meta Platforms who are shepherding those GPUs into systems through various ODM partners, have put out a statement describing the servers, networks, and storage that will be used to train Llama 3 large language models for production use and also build more powerful and very likely larger successors in the Llama family.
Let’s talk about these GPU equivalent numbers first and then see what choices Facebook is making as it builds out its infrastructure as it pursues AGI with Llama 3 and works on what we presume are Llama 4 and Llama 5 in its Facebook AI Research and Generative AI labs.
We have no idea how many GPUs that Meta Platforms had in its fleet in 2022, when things started to get interesting with GenAI. In 2017, Meta Platforms – then called Facebook after its founding and dominant social networking application – built the first generation of its AI clusters with 22,000 “Volta” V100 GPUs.
In January 2022, when the GenAI boom was just starting, Meta Platforms bought its Research Super Cluster, or RSC for short, from Nvidia based on its DGX server designs and 200 Gb/sec InfiniBand, and slated to bring 2,000 nodes with a total of 16,000 GPUs to bear for AI workloads. The first phase of the RSC machine, which we reported on here, used 6,080 of Nvidia’s “Ampere” A100 generation of GPU accelerators, and this was up and running by October 2022. In May 2023, The RSC buildout was finished, and not with then shipping “Hopper” H100 GPUs, but with another 9,920 A100 GPU accelerators. The nodes were all connected to each other in a two-tier Clos topology based on a 200 Gb/sec InfiniBand network.
According to a report by Omdia, which we reported on here, Meta Platforms was set to get 150,000 H100 GPUs in its Nvidia allocation for 2023. We presume these H100 GPUs were put into clusters based on the “Grand Teton” systems that Meta Platforms unveiled in October 2022, and that we talked a bit more about recently as part of our coverage of Broadcom’s PCI-Express switches, which are used to multiplex connections from the GPUs to the CPUs in the Grand Teton machine.
Based on all of this, here is what we think the Meta Platforms GPU fleet will look like as 2024 comes to a close:
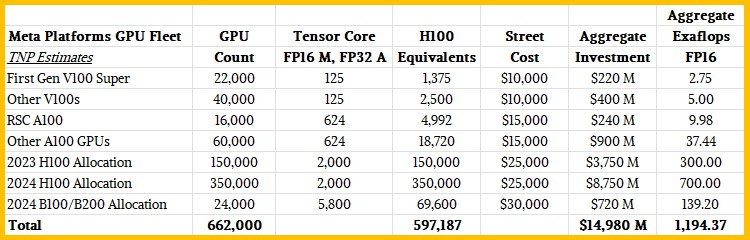
We realize there is a lot of guessing to fill in the gaps here. This is a thought experiment, and that is the way it is.
Let’s think about a couple of things. If the Omdia data is right about H100 allocations to Meta Platforms in 2023, then the combined 2023 and 2024 H100 allocations to Meta Platforms would be enough to build twenty clusters with 24,576 GPUs, which is the scale of two machines that the company talked about this week.
With 350,000 H100s going into Meta Platforms this year, one thing is clear: Whatever the “Blackwell” B100 and B200 GPU accelerators are, Meta is not waiting for them to start building its foundation for AGI. That does not mean Meta Platforms won’t have Blackwell GPUs this year.
If we take a guess and assume that the social network had around 40,000 legacy GPUs (we think mostly V100s) and plus those 22,000 V100s in the first generation supercomputer that came before RSC, and then adjust these to H100 equivalents based on FP16 multiply and FP32 accumulate on tensor cores on the V100 GPUs, which is the most generous way to count relative performance across the Nvidia GPUs that is still somewhat representative of the AI workload, then the V100 fleet of 62,000 GPUs is at a mere 3,875 H100 equivalents. We think it cost somewhere on the order of $620 million just to acquire those GPUs at prevailing prices at the time. Meta Platforms probably got a bit of a discount off that, but maybe not.
The 76,000 A100s that we think might be in the Meta Platforms fleet are equivalent to 23,700 H100s and comprised a $1.1 billion investment in the GPUs alone. That A100 fleet, if it indeed looks anything like we expect, has an aggregate performance of over 47 exaflops at FP16 resolution on tensor cores (with sparsity support included in the goosing), which is a factor of 6.1X more aggregate compute for less than 2X more money.
That massive 500,000 H100 GPU pool that is building at Meta Platforms represents an order of magnitude more investment – 11X, if you do the math, at $12.5 billion for the cost of the GPUs alone – and at 1,000 exaflops at FP16, that is a 21.1X increase in performance. The cost of an FP16 unit of oomph was cut in half, and if Meta Platforms uses FP8 data in its models – this is one of the thing that has been called out – then the relative performance can go up by 2X and the relative bang for the buck improves by that much, too.
By the way, we are assuming that Meta Platforms is only talking about its training fleet, but perhaps this is a mix of training and inference in this GPU fleet. The blog that Meta Platforms put out doesn’t explain it. Eventually, this fleet will include homegrown MTIA devices.
Anyway, we think there is room in the Meta Platforms budget for 24,000 Blackwell B100s or B200s this year, and we would not be surprised to see such a cluster being built if Nvidia can even allocate that many to Meta Platforms. Or that could be a mix of Blackwell devices from Nvidia and “Antares” Instinct MI300X devices from AMD.
The fact that one of the two new clusters that Meta Platforms is talking about is based on 400 Gb/sec InfiniBand networks is interesting in that Meta Platforms is one of the backers of the Ultra Ethernet Consortium and has been pretty clear that it wants Ethernet to behave more like InfiniBand in some ways and is working towards that goal.
“Our newer AI clusters build upon the successes and lessons learned from RSC,” write Kevin Lee, Adi Gangidi, and Mathew Oldham, who are in charge of various aspects of the infrastructure at Meta Platforms. “We focused on building end-to-end AI systems with a major emphasis on researcher and developer experience and productivity. The efficiency of the high-performance network fabrics within these clusters, some of the key storage decisions, combined with the 24,576 Nvidia Tensor Core H100 GPUs in each, allow both cluster versions to support models larger and more complex than that could be supported in the RSC and pave the way for advancements in GenAI product development and AI research.”
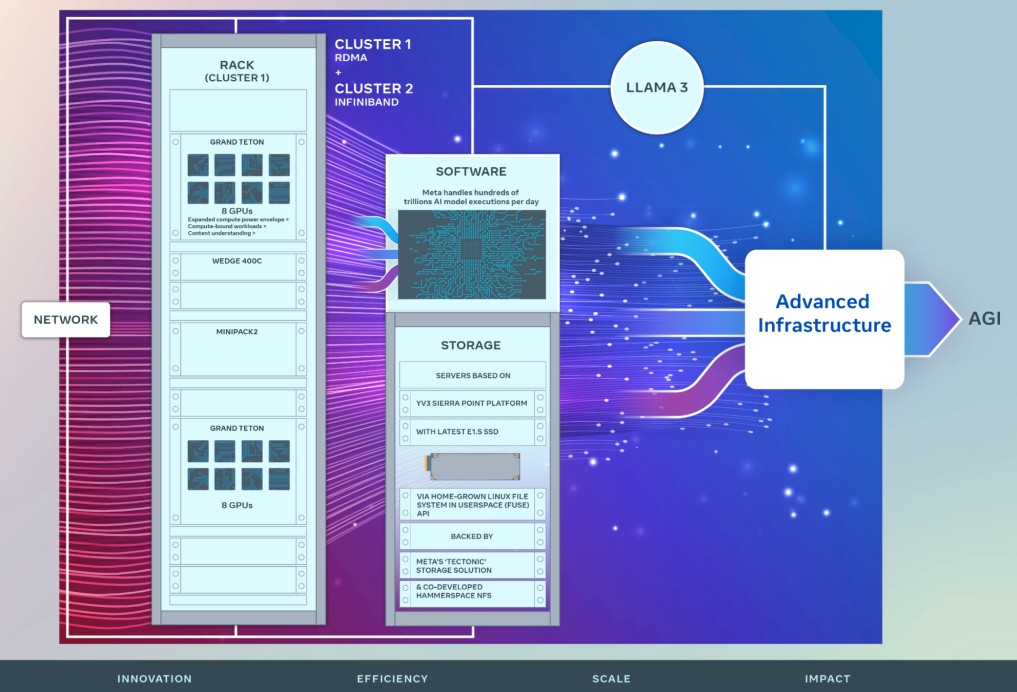
The company reaffirmed its commitment to its open source Grand Teton server designs and its OpenRack enclosures for housing these machines as well as to the open source PyTorch framework and its open source Llama LLMs.
If you do the math on 24,576 GPUs and see that there are only two Grand Teton systems in each rack in the system in the diagram above, that means the two clusters that Meta Platforms referenced in its blog each have 3,072 nodes across 1,536 racks, which suggests that the company is not yet moving to liquid cooling. Designs we have seen with liquid cooling can put four GPU machines in a rack. It might have something to do with the way Meta Platforms is distributing the networking among the racks.
There are Wedge 400C and Minipack2 networking enclosures, built by Arista Networks to the OCP specs, shown in the drawing above, which is clearly for the Ethernet switching infrastructure. Both InfiniBand and Ethernet versions of these clusters have eight 400 Gb/sec ports to the GPU servers, one for each GPU
“With these two, we are able to assess the suitability and scalability of these different types of interconnect for large-scale training, giving us more insights that will help inform how we design and build even larger, scaled-up clusters in the future,” the Meta Platforms techies write. “Through careful co-design of the network, software, and model architectures, we have successfully used both RoCE and InfiniBand clusters for large, GenAI workloads (including our ongoing training of Llama 3 on our RoCE cluster) without any network bottlenecks.”
The storage servers used with these GPU clusters will be based on the “Sierra Point” Yosemite V3 servers using E1.S SSD flash modules. Meta Platforms has a homegrown Linux file system in user space (FUSE) that will run on these Sierra Forrest storage servers, and they will be backed up by the company’s own Tectonic storage overlay for flash – it’s Haystack file system was optimized for disk drives – and a distributed NFS file system co-developed with Hammerspace.
We are working to get the reference architectures of these AI clusters. Stay tuned.




Wow! Quite an impressive GenAI Infrastructure plan by Meta. The two 24,576-GPU datacenter-scale clusters each pack roughly twice the oomph of MS Eagle (#3 on Top500), suggesting about 1.3 EF/s each in FP64 (if Meta were so-inclined as to run one through HPL). In my mind, if “believable” AGI doesn’t emerge from such massive assemblies of artificial matrix-vector neurons, then we might be in for a recurrence of some AI-winter-like weather (global cooling of enthusiasm). Let’s hope it pans out (safely), with some successful and long-lasting killer-apps coming out of the effort!
Yo, Slim. Don’t invoke “killer apps” please. . . .
Hi, I wonder if Meta is to buy 350,000 H100 chips or accumulate 350,000 by the end of the year.
As per his REEL, “we’re building massive compute infrastructure to support our future roadmap, including 350k H100s by the end of this year — and overall almost 600k H100s equivalents of compute if you include other GPUs”, it seems that 350k is the total H100 figure.
The beautiful table in this article may miss out MI300’s equivalent (2 MI300 = 1 H100?). Please check, thank you!