
Things would go a whole lot better for server designs if we had a two year or better still a four year moratorium on adding faster compute engines to machines. That way, we could let memory subsystems and I/O subsystems catch up and get better utilization of those compute engines and also require fewer banks of memory and fewer I/O cards to keep those compute engine beasts fed.
That is not going to happen, of course.
And in fact, the four year delay in moving from the 8 Gb/sec PCI-Express 3.0 peripheral interconnect, whose specification came out in 2010, to the 16 Gb/sec PCI-Express 4.0 interconnect, which should have come out in 2013 but didn’t make it into the field until 2017, has created an impedance mismatch between the I/O bandwidth that compute engines really need and what the PCI-Express interconnect can deliver.
That mismatch has been carried forward such that PCI-Express has been perpetually behind. And this in turn has forced companies to come up with their own interconnects for their accelerators rather than use generic PCI-Express interconnects that would open up server designs and level the I/O playing field. So Nvidia had to create NVLink ports and then NVSwitch switches and then NVLink Switch fabrics to lash memories across clusters of GPUs together and, eventually, to link GPUs to its “Grace” Arm server CPUs. AMD had to create the Infinity Fabric interconnect to link together CPUs and then CPUs to GPUs, which has also been used inside of the socket to link chiplets
And for the record, we have heard that it was Intel that dragged its feet on PCI-Express 4.0 after having issues with integrated PCI-Express 3.0 controllers on some of its Xeon processors from more than a decade ago. But we think that to be fair, it has to be admitted that the jump to PCI-Express 4.0 had other technical issues that needed to be resolved, just like the Ethernet roadmap had issues above 10 Gb/sec and could not jump directly to 100 Gb/sec speeds and had to do a 40 Gb/sec stepping stone and a then a high cost, high power 100 Gb/sec Ethernet implementation base on the same 10 Gb/sec lane signaling before the hyperscalers and cloud builders (and Broadcom and Mellanox) convinced the IEEE to adopt cheaper 25 Gb/sec lane signaling.
Things happen, and the PCI-Express roadmap is one of the things has had its share of happenings. As you can see below from our coverage of the launch of the work stating on the PCI-Express 7.0 specification last year:
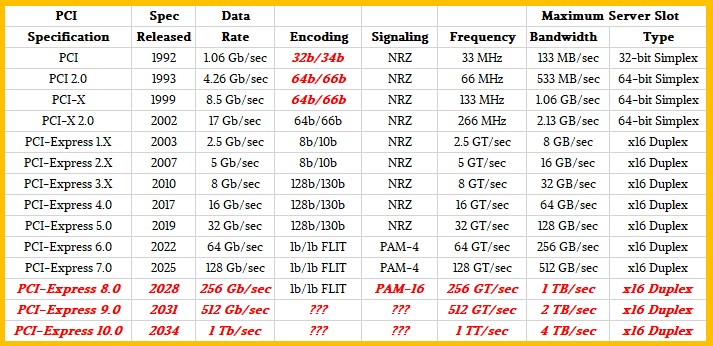
We have argued that the cadence of the PCI-Express roadmap for peripheral cards, retimers, and switches needs to match the cadence of compute engine releases, and have said further that based on the specs, we really need for PCI-Express 7.0 to be in the field today when the spec is not even going to be ratified until next year. But given that PCI-Express 6.0 is the first generation to use PAM-4 signaling and FLIT low-latency encoding, jumping straight from PCI-Express 5.0 with well-established NRZ signaling to an even faster PAM-4/FLIT combination expected with PCI-Express 7.0 devices is not practical. Pretty much in direct proportion as it is very desirable.
And no one knows this better than Broadcom, which makes PCI-Express switches and the retimers that extend the range of the copper wires that plug into them thanks to Avago’s acquisition of PLX Technologies in June 2014 and Avago’s acquisition of Broadcom in May 2015. The company is readying its “Atlas 3” generation of PCI-Express switches and “Vantage 5” retimers, which are based on the “Talon 5” family of SerDes that implement PAM-4 signaling. The Talon 5 SerDes are related to – but unique from – the “Peregrine” PAM-4 SerDes that are used in its “Tomahawk 5” and “Jericho 3-AI” families of Ethernet switch ASICs, and that is because PCI-Express is an absolutely lossless protocol that also happens to have much more stringent low latency requirements.
To help get server makers and peripheral makers pulling in the same direction, Broadcom is starting to publish its PCI-Express switch and retimer roadmap, which is a good thing. We show it below with codenames added where we know them:
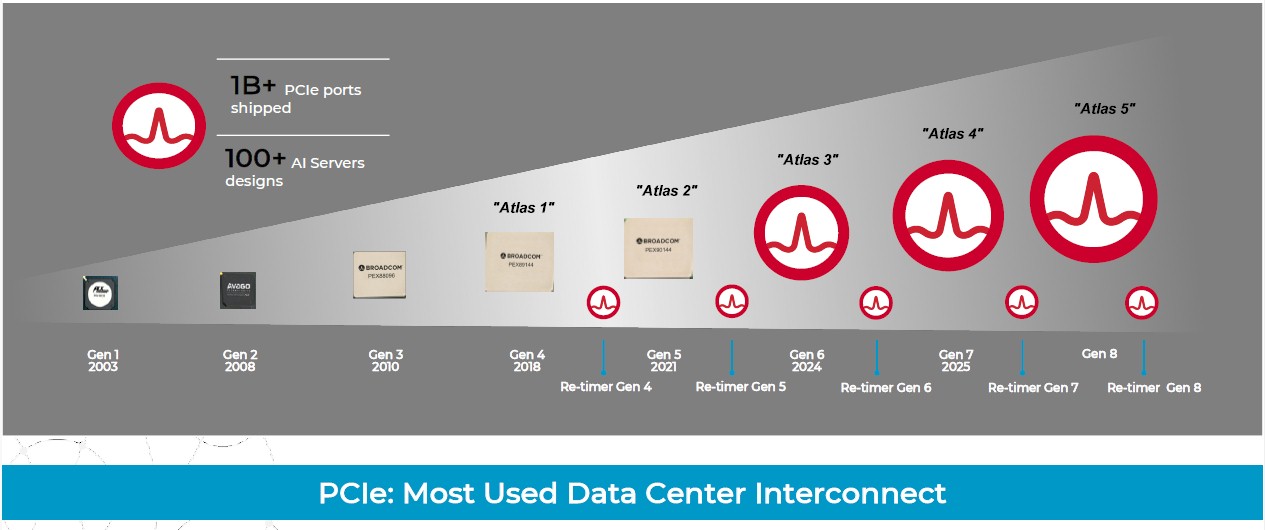
Interestingly, Broadcom was going to get out of the retimer business and was pulled back into it by its customers and partners, and technically this story is about revealing some of the details about the Vantage 5 and 6 families of PCI-Express retimers for the PCI-Express 5.0 and 6.0 generations.
“We always want to have the retimers be companion chips with the switches,” Jas Tremblay, vice president and general manager of the Data Center Solutions Group at Broadcom, tells The Next Platform. “We believed in PCI-Express Gen 5 that the retimer was going to be a commodity and that there was going to be three or four suppliers to successfully bring these products to market. So we focused all our efforts on switches and other higher complexity PCI-Express 5.0 products. But we were totally wrong. Customers came back to us because the retimers were a lot harder than anyone thought. We have to make sure the switch and the retimer work, of course, and that they are extremely solid, but we actually have to make sure it’s instrumented so that we can help system providers and cloud providers pinpoint what is going on in the devices.”
The retimers are an increasingly important part of the PCI-Express hardware and firmware stack. First of all, servers are just getting more complex than they were two decades ago when PCI-Express 3.0 ruled the world and all we needed – well, according to Intel – were more lanes not faster lanes. Look at the difference between a general purpose server and an AI server when it comes to PCI-Express interconnects inside of the node:
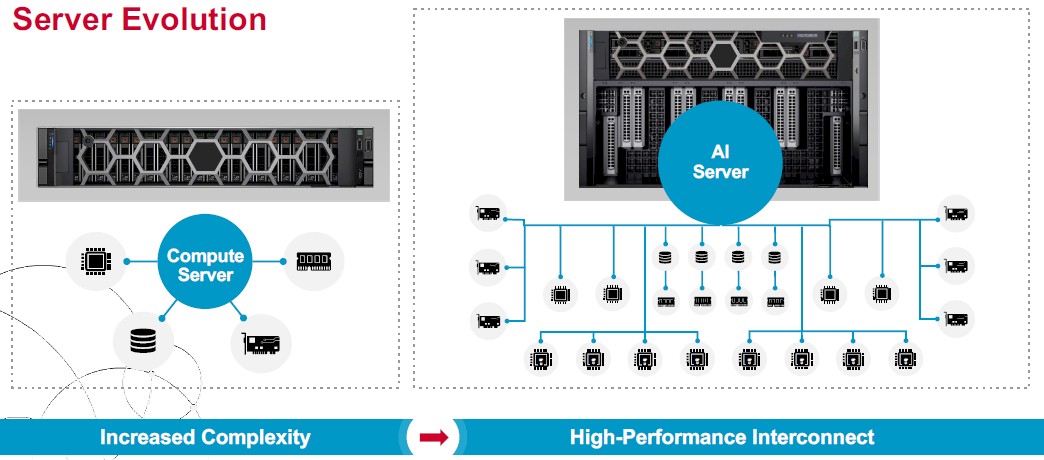
We have moved from a point-to-point interconnect with a handful of devices – a disk controller or two, a network controller, maybe some other specialized peripheral – hanging off the PCI-Express bus to what amounts to a PCI-Express switched fabric that is used to connect CPUs to accelerators, network interfaces, flash storage, and soon CXL extended memory. Someday, we might even see CPUs linked over PCI-Express links running the CXL protocol instead of proprietary NUMA interconnects, or more likely, proprietary overlays running atop PCI-Express/CXL as it looks like AMD and Broadcom are working on for future CPUs and GPUs. (We are working on a separate story on that. Stay tuned.)
But there is another problem, and this is where the retimers come in.
With each doubling of the bandwidth, the distance that a PCI-Express signal can be driven down a copper wire is cut in half. The retimers are used the extend the length of the copper wire; the longer the wire, the more retimers you need. Because of latency issues and the fact that PCI-Express is used as an extension of the CPU bus, you try not to let those wires get too long. But if you want to stretch PCI-Express fabrics across several racks, or even an entire row of machinery – as we here at The Next Platform want the industry to do – then retimers are going to be needed more and more as the PCI-Express bandwidth goes up.
The latest Vantage 5 and Vantage 6 retimers from Broadcom add only 6 nanoseconds to boost the length of the PCI-Express 6.0 signal, and this seems like a pretty low overhead given that such a PCI-Express fabric would obviate the need for InfiniBand or Ethernet fabrics across the racks of machinery. Broadcom, as a founding member of the Ultra Ethernet Consortium that is trying to make Ethernet better than InfiniBand and with its Jericho 3-AI deep buffer switch ASIC that is the first step in this effort, wants to have PCI-Express switching within a node and maybe across nodes in a rack, but Ethernet across racks and rows. We shall see what customers choose to do. A lot, it seems, will depend on the retimers and the levels of switchery used to make a cluster – and the overall cost of PCI-Express fabrics versus InfiniBand and Ethernet.
Here is how complex a modern AI server looks on the inside these days:
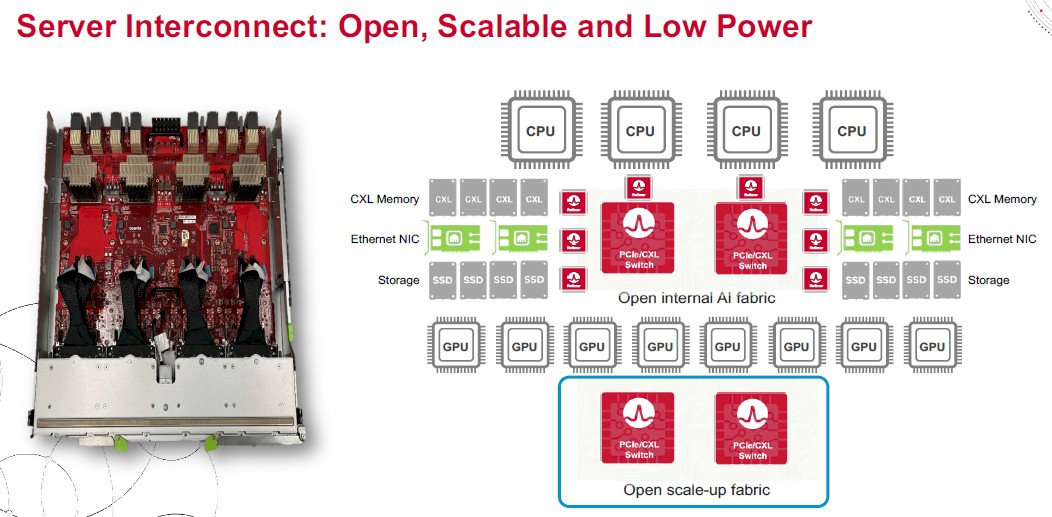
That is a block diagram of the “Grand Teton” AI server that Meta Platforms unveiled as an Open Compute Project design back in October 2022 and that were rolled out in production at the social network in 2023.
In that Grand Teton server, there is a pair of PCI-Express switches that are used to link a quad of CPUs to Ethernet NICs, flash storage, and CXL memory, with retimers adding length to the connections between the peripherals and the switches. There is another pair of PCI-Express ASICs that are used to interconnect eight GPUs so they can share memory. The Grand Tetons were based on PCI-Express 5.0 chips, meaning Vantage retimers and Atlas 2 switch ASICs. Each of those ASICs has 114 lanes of PCI-Express 5.0 signals, which yields 57 TB/sec of aggregate bandwidth across all of the devices inside the box.
Here is a different – and perhaps more accurate – block diagram that shows how the switches and retimers are used in the Grand Teton system, which comes from its OCP specs:
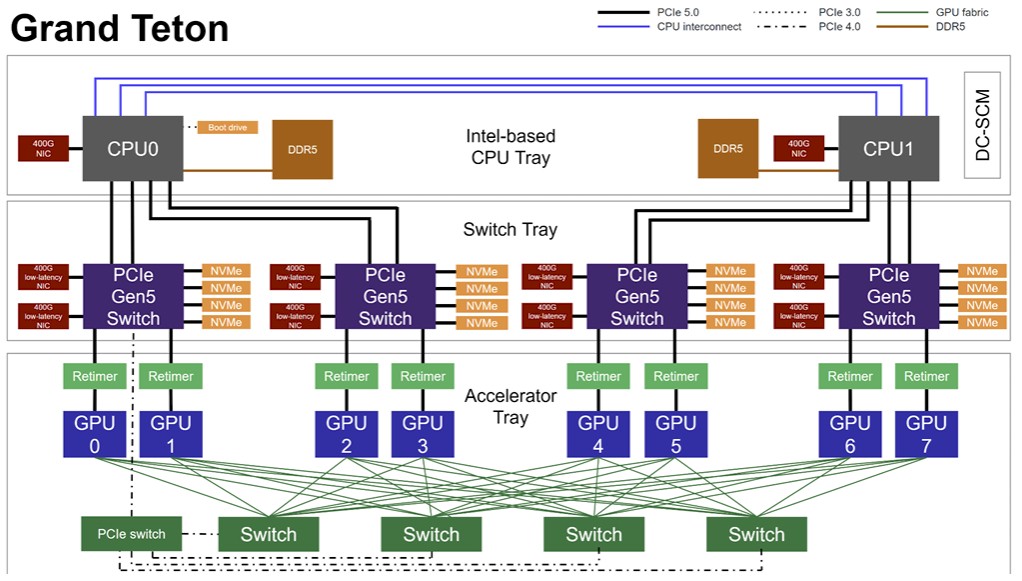
These specs were not available back in October 2022.
As you can see, the retimers are really used to extend the links between the PCI-Express switches and the GPUs, and the other peripherals are linked directly to the PCI-Express switches. Which is not exactly what the Broadcom chart suggests. The numbers of switches and retimers are the same, but their topology is different. Also, the NVSwitch interconnect is still used to link the GPUs to each other, although there is a secondary PCI-Express 4.0 switch that links the GPUs into one of the PCI-Express 5.0 switches, possibly as a management interconnect or as a means to send data back to the CPUs without having to go back through the retimers. It is an interesting schematic.
Back to the retimers. Here are the salient characteristics of the Vantage 5 and Vantage 6 retimers, which are paired with PCI-Express 5.0 (“Atlas 2”) and PCI-Express 6.0 (“Atlas 3”) switch ASICs:

Because they drive 64 Gb/sec PAM-4 signaling, the Vantage 6 retimers run a little bit hotter than the Vantage 5 retimers, which only do 32 Gb/sec NRZ signaling. Both retimers use the same Talon 5 SerDes, which support either signaling approach, and both the Vantage chips are etched in 5 nanometer processes from Taiwan Semiconductor Manufacturing Co.
It is not clear why there is not a channel performance spec for the Vantage 6 when connecting to a Broadcom SerDes using 64 Gb/sec PAM-4 signaling. Perhaps Broadcom is holding that information back for now. Clearly, Broadcom wants to do end-to-end connectivity for customers – and even wants to get a shot at replacing NVSwitch in some designs, which you can bet the hyperscalers and cloud builders as well as the HPC centers of the world want to do as soon as PCI-Express can do the job.
Tremblay says that the combination of its chips provide 40 percent greater reach using its Talon 5 SerDes on the retimers and switches together, which provides 12 decibels of better signal than the PCI-Express 5.0 specification requires. The combination of the architecture of the Talon 5 SerDes and the shrink to 5 nanometers – compared to 7 nanometers for the competition making PCI-Express switches and retimers – delivers 50 percent lower power dissipation, too.
By the way, Broadcom did contemplate moving straight from PCI-Express 6.0 to PCI-Express 8.0, jumping right over PCI-Express 7.0 entirely, to try to get compute and I/O back into better balance. But there are a whole lot of compute engine makers and server makers and peripheral makers that would need to leap with Broadcom on that long jump, and it just wasn’t possible. Had Broadcom made that jump, customers would have been plugging PCI-Express 7.0 stuff in its PCI-Express 8.0 gear and running them at the slower compatibility mode anyway.
They get credit for thinking about it.


Switching Back Into A Higher Gear
If you want to get a sense of what is happening in the high-end of the Ethernet switch and routing market, it is Arista Networks, formerly an upstart and now just one of the bigger vendors taking on the hegemony of Cisco Systems in networking in the datacenter and now …
Before Long, Datacenter Will Be Nvidia’s Biggest Business
It is hard to remember sometimes way back when, in 2008, as Nvidia first took a stab at GPU compute in the datacenter with the original Tesla GPU accelerators and a very rudimentary CUDA programming environment for offloading parallel algorithms from CPUs to GPUs. It has been a long road …
Can Marvell Profit As It Tries To Triple Its Business By 2028?
A rising tide may lift all boats, and that is a good thing these days with any company that has an AI oar in the water. But the question is will any of that water be potable – by which we mean profitable. Thus far, depending on how cynical you …
I can’t wait to see CPUs, GPUs, memory modules, and FPGAs, supporting PCIe 6.0 PAM-4, plugging into these Atlas 3 switches and Vantage 6 retimers, for the first realization of the CXL 3.0 cohesive integration protocol on real-world machines. The prospect of scaling coherency beyond multi-core CPU caches and into whole multi-cabinet heterogeneous systems, by design, and with low latency, is one that I find to be quite a game changer (especially from the rather commodity perspective of PCIe). It’ll probably take years to fully take advantage of the flexibility that this brings to datacenter and HPC/AI machinery, and so, the sooner it starts, the better (IMHO)! Co-Packaged Optics (CPO) might also reduce the need for local retimers I think (vs copper).
Me, too. Those optics, according to Jas, are inevitable by PCI-Express 8.0 because copper won’t work after that. But, then again, people thought that would happen years ago. But after 100 Gb/sec signaling, we are going to hit some power issues and length of wire issues. It will be like two inches from the switch to the port is my guess, and that ain’t gonna cut it. The optics are so much more expensive than copper that the latency add from retimers is well worth it. 6 nanoseconds is not so bad. It might make memory a bit jiggy jaggy, admittedly. But we can have fast HBM, slower local DRAM, and even slower CXL and have a memory hypervisor manage data placement across the complex and lie to the OS and apps about how much local memory it has and where. That’s what I would do, anyway. Where’s Charles Fan of MemVerge? Are you reading this Charles?
PCIe 8.0 is up in the air! What we learned from BRCM during OCP2023 iS that THEY are pushing for expedition of PCIe 7.0 and roll out the prodouct portfolio along with it. My take is that PCIe 6.0 might be skipped, not 7.0. Thoughts?
Well, it has been a few weeks and things are changing fast. I would think that PCI-Express 6.0 would just about be cooked now so maybe they are just trying to accelerate PCI-Express 7.0 and get the cadence up. I would do the same thing for PCI-Express 8.0. There is more money to be made replacing Nvidia NVLink with a standard than selling a bunch of PCI peripherals, if they can pull this acceleration off.
Cool. We can do a sanity check in October again and I am sure they will have more to say, 🙂
Any updates on that follow-up article with regards to the partnership with AMD and Broadcom on the AFL tech?
It’s on my to-do list. . .