

If there is one thing that is consistently true about HPC clusters for the past thirty years and for AI training systems for the past decade, it is as workloads grow, the network becomes increasingly important – and perhaps as important as packing as much flops in a node as physically and thermally makes sense.
For AI training systems, nothing illustrates this better than the evolution of bespoke servers created by Meta Platforms, even way back in 2016 when it was still called Facebook and when it donated its first AI system design to the Open Compute Project that it founded in 2011. Such co-design of hardware and application software in the waning years of Moore’s Law was one of the central themes that led us to found The Next Platform, and here we are eight years on and the hyperscalers and cloud builders are still re-teaching us some of the lessons we learned a long time ago in the HPC arena with some interesting twists and turns that are unique to AI.
At the OCP Global Summit in Silicon Valley this week, Meta Platforms unveiled its new “Grand Teton” AI system and a companion “Grand Canyon” high capacity storage array based on disk drives, the designs of which will both be donated to the Open Compute Project so other manufacturers can create systems that are compatible with the iron Meta Platforms will be using for its own AI software stacks.
The full specifications of the Grand Teton system were not divulged, which is a shame, but we did get some insight from a blog posted by Alexis Bjorlin, vice president of infrastructure at the company, and the spec for the Grand Canyon storage array is actually available at the OCP. (Despite the fact that Meta Platforms has enough video streaming bandwidth to host billions of people, it chooses not to donate resources to OCP so anyone can attend the event virtually from anywhere. This year, people had to attend the OCP Global Summit in person, which we were unable to do. So, we can’t hustle in person to get more details, but rest assured, we are hustling from afar.)
Luckily, by poking around, we ran across a paper published by Meta Platforms back in April about the Neo system of hardware-software codesign that was used to create the prior generation “Zion” AI system from 2019 and the “ZionEX” system from 2021 that was its kicker and that the company has not said much about publicly until this year. Neo is a kind of memory caching hypervisor created by Meta Platforms that allows for flexible and scalable use of various parts of the memory hierarchy in clusters – all under software control. (The ZionEX design was contributed to the OCP, by the way, and it is now under the Zion 1.0 spec document. Grand Teton will be contributed to OCP in April 2023, according to sources at Meta Platforms. We don’t know what happened to the original Zion server spec.)
The ZionEX machines and the Neo cache memory hypervisor (that’s our terms for it, not Meta Platforms’ term) are used to train deep learning recommendation models (DLRMs), which are a key workload for modern businesses and in this case is used to try to figure out what ad and content to show to users across Facebook, Instagram, WhatsApp, and the rest of the stack.
The horsepower needs for DLRMs as well as for transformer models (used in natural language processing) is pretty intense, as these charts from the April paper show:
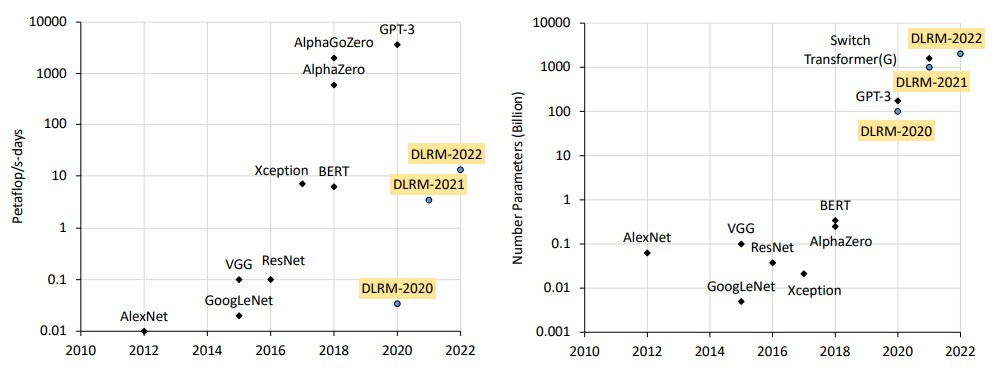
Meta Platforms has used the ZionEX clusters, which couple multiple Zion systems together, to train DLRM models ranging in size from 95 billion to 12 trillion parameters and delivering an order of magnitude speedup over simpler clusters of Zion machines. The original Zion design did not scale well, according to Meta Platforms, and often times a training run was trapped inside of one machine. But with ZionEX, Meta Platforms came up with a fully connected topology for GPUs that makes use of RDMA over Converged Ethernet to bypass the CPU networking stack and give GPUs full access to each other’s memory across the Ethernet fabric. (More on this later.)
Presumably, given that the Grand Teton system will make use of the “Hopper” H100 GPUs, which have 3X to 6X the performance of the prior “Ampere” A100 GPUs used in the ZionEX machines, and also have 4X the host GPU bandwidth, 2X the network bandwidth, and 2X the power envelope that allows the Hopper GPUs to be used in the first place, the Grand Teton machines should help Meta Platforms scale its DLRMs even further and get results even faster on models that do not grow.
The Evolution Of AI Iron At Meta Platforms
One of the things that all of the hyperscalers and big cloud providers all figure out is that they need to co-design their hardware and software for their specific application stacks or those of their cloud customers, and moreover, they need to control the bill of materials and sources of parts in those machines so they can meet their capacity planning targets in a world where the supply chains have become destabilized by the coronavirus pandemic.
And so, Facebook started the Open Compute Project to try to take those issues on head on, and as it has transformed into Meta Platforms, the need for customer hardware has become only more acute. Which is why we have been poking a little fun at Meta Platforms for the past year for going to Nvidia and taking a most unbespoke system based on DGX servers and Mellanox switch infrastructure dubbed the Research Super Computer, or RSC for short. This is absolutely not the way Facebook and Meta Platforms do things, and if they are buying systems from Nvidia, it quite possibly be because that was the only way to get GPUs in a timely fashion.
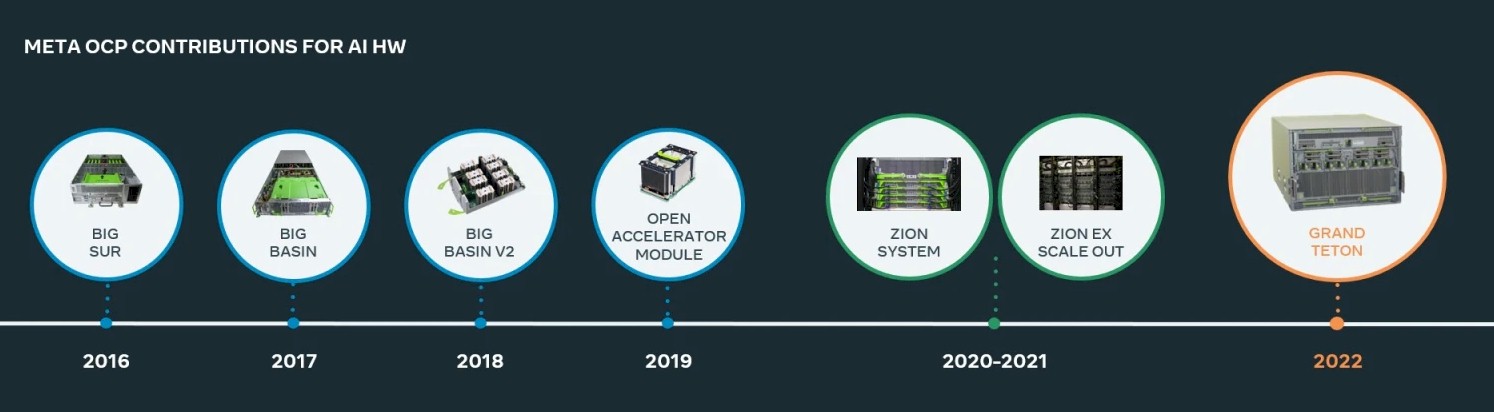
The GPUs for the Zion, ZionEX, and now Grand Teton servers all make use of the OCP Application Module (OAM) form factor, created by Facebook and Microsoft three years ago. The prior GPU-accelerated AI machines – which includes Big Sur from 2016, Big Basin from 2017, and Big Basin 2 from 2018 – all used PCI-Express GPU accelerators and did not make use of the Nvidia custom SXM sockets with their NVLink networking that Nvidia reserves for its highest performing systems.
Meta Platforms, like many hyperscalers, is trying to stay as far away from proprietary as it can – which again, makes the acquisition of the RSC system as well as Meta bragging about building a virtual supercomputer based on Nvidia A100 GPUs on the Microsoft Azure cloud both very peculiar. In fact, that is why Microsoft and Meta Platforms created the OAM form factor in the first place.
AMD and Intel are both supporting OAM form factors with their GPUs – AMD with its prior “Arcturus” Instinct MI100 series from November 2020 and its latest “Aldebaran” Instinct MI200 series that started rolling out a year later. Intel is supporting the OAM form factor for its “Ponte Vecchio” Xe HPC discrete GPU accelerators that are, frankly, long overdue.
Nvidia has never discussed this, but it did custom variants of the PCI-Express versions of its “Pascal” P100 and “Ampere” A100 GPU accelerators in the OAM form factor for Meta Platforms for Zion and ZionEx servers. We presume that it will do the same for H100 devices used in the Grand Teton system. We also presume that Nvidia makes OAM-compatible GPU accelerators for Microsoft.
The reason why Meta Platforms might be buying AI clusters in the cloud from Microsoft or DGX systems lock, stock, and barrel from Nvidia might simply be that Nvidia made a certain number of OAM-based GPUs for these two companies and that was it until the H100 started shipping.
From Zion To Grand Teton
The best way to understand what the Grand Teton system might be – a lot of the details have yet to be revealed by Meta Platforms – is to look at Zion and ZionEX and then see how these designs have evolved, and why.
The Zion system was interesting for a few reasons, and not just because of the OAM form factor and reconfigurable PCI-Express switching fabric topology that was inherent in the design. This Zion machine was unabashedly about both the CPU and the GPU, and their respective fat and slow plain vanilla DDR and skinny and fast HBM memories. And moreover, it was Facebook (not yet Meta Platforms at the time) that compelled Intel to add BF16 half-precision floating point math to the AVX-512 vector engines in the “Cooper Lake” Xeon SP processors, thus matching the BF16 floating point available on the GPUs of the time.
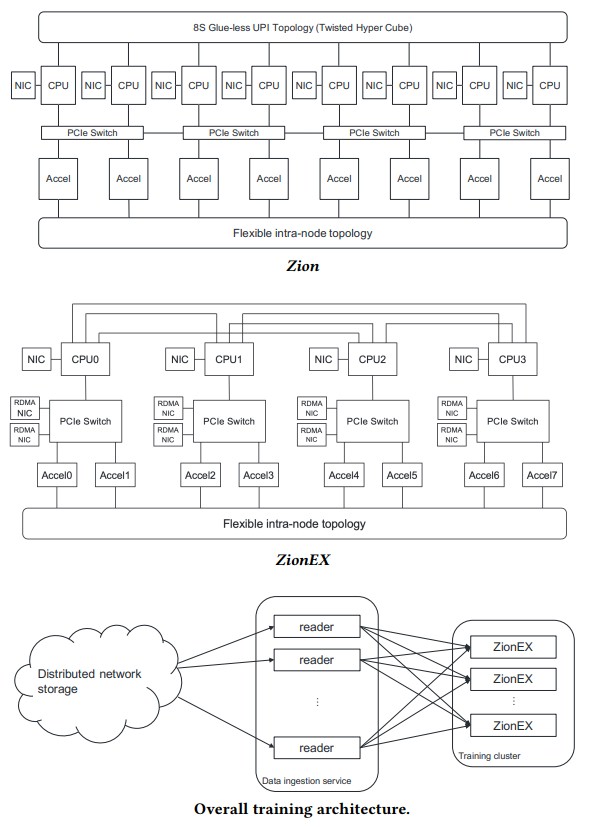
By having these memories and a common data format and processing methodology, Facebook could simplify some of its machine learning dataflows and transformations. And to be very specific, the eight CPUs of the Zion server node, with 6 TB of memory meant that terabyte-scale DLRMs could have all of their embeddings in main CPU memory while the computational parts of the DLRM could be moved to the GPUs and spoon-fed data into their HBM memory as immediately needed from that CPU main memory as well.
As you can see, the eight Cooper Lake Xeon SPs in the Zion are gluelessly linked by Intel’s UltraPath Interconnect (UPI) in a twisted hypercube topology (which means there is one hop between six of eight CPUs, but two hops between the two others.) The 100 Gb/sec network interfaces hang off of the CPUs, and there are four PCI-Express switches that are embedded on the OAM board that creates the reconfigurable fabric to link the GPUs to each other and to the CPUs.
The eight-way CPU server within Zion is actually comprised of four two-socket “Angels Landing” CPU cards, each with up to 1.5 TB of memory and four 100 Gb/sec Ethernet NICs supporting the OCP 3.0 specification for mezzanine cards. Stacked on top of that was the “Emerald Pools” GPU chassis, which had four PCI-Express 4.0 switches to interconnect the eight OAM GPUs to each other and to each of the eight CPUs in the Zion system.
With the ZionEX system, the specs of which you can see here, Facebook put an intermediate switching layer between the GPUs and the CPUs, which did a few things. First, the PCI-Express switch complex in the middle, called “Clear Creek,” four PCI-Express 4.0 switches, eight 200 Gb/sec Ethernet NICs to lash the Zion nodes together, and room for sixteen E1.2 or M.2 flash drives for local storage. (Each PCI-Express switch has up to four NVM-Express flash drives.)
While Facebook didn’t talk about this at the time, the Zion and ZionEX machines could be configured with one, two, or four two-socket CPU compute sleds and did not have to have the full complement of four sleds. And in fact, with the ZionEX, four sockets in two sleds was the default and one sled was permissible if the DLRM model didn’t need more than that CPU compute and DDR4 memory capacity.
Here is a much better schematic of ZionEX that shows the hierarchy of connections:

While the Zion and ZionEX machines have multiple independent subsystems, the Grand Teton system has a single motherboard that all of the components – CPUs, GPUs, PCI-Express switches, and network interface cards – all plug into.
This makes for a more reliable system, with fewer cables and connections and fewer things that can go wrong. In fact, the Grand Teton design eliminates external cabling entirely except for power and network.

The feeds and speeds of the Grand Teton system are being kept under wraps right now by Meta Platforms, and it will be interesting to see what CPUs and GPUs it chooses. Our guess, given Facebook’s long dependence on Intel Xeon D processors for infrastructure workloads, is that Grand Teton will use “Sapphire Rapids” Xeon SPs for CPU compute, PCI-Express 5.0 switching, and the option of Nvidia, AMD, or Intel GPUs.
This certainly fits. The Cooper Lake Xeon SPs had PCI-Express 3.0 x16 links out to the Clear Creek switch node, and shifting these to PCI-Express 5.0 x16 links yields 4X the host to switch bandwidth. Using PCI-Express switches as a fabric on the Grand Teton system board would balance this out, and shifting to 400 Gb/sec RoCE Ethernet for network interfaces on the switches interfacing with the GPUs and to 200 Gb/sec Ethernet ports on the CPU hosts would give the 2X compute and data network bandwidth the Meta Platforms blog is talking about.
Perhaps most interesting is that the Grand Teton system can take twice the heat, and Bjorlin explained in her blog post why this is a big deal.
“The power trend increases we are seeing, and the need for liquid cooling advances, are forcing us to think differently about all elements of our platform, rack and power, and data center design,” Bjorlin explained. “The chart below shows projections of increased high-bandwidth memory (HBM) and training module power growth over several years, as well as how these trends will require different cooling technologies over time and the limits associated with those technologies.”
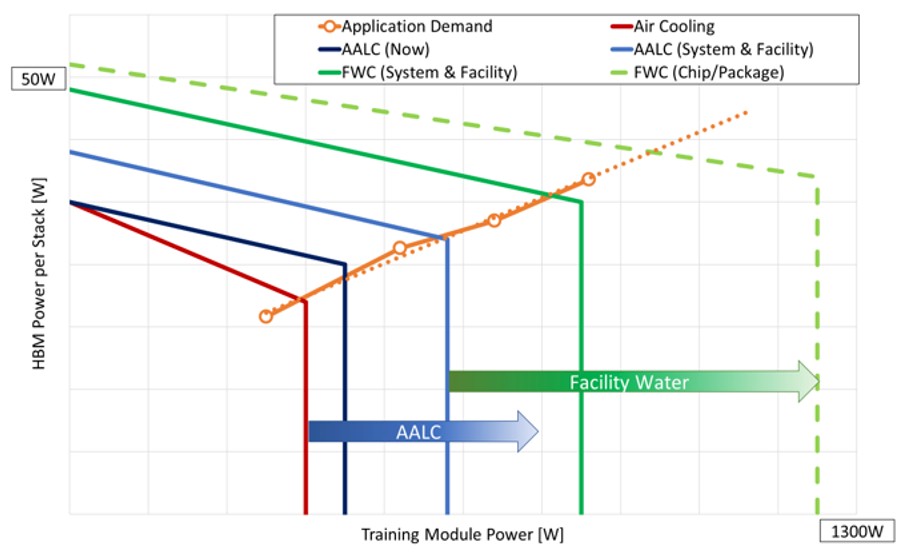
With air-assisted liquid cooling (meaning liquid cooling that moves heat around inside the chassis before it is dumped into the hot aisle of the datacenter) and facility water cooling to take away heat even more efficiently from the racks, Meta Platforms is showing how this design can accommodate hotter GPUs and HBM memory stacks and push out to 1,300 watts per socket and still meet the crazy demand for more capacity for its DLRM systems.
Filling The Grand Canyon With Data
Meta Platforms mentioned in passing a companion upgrade to its current “Bryce Canyon” storage array, called “Grand Canyon,” which supports both hard disk drives and flash modules. The specs for this were released on September 14, and you can see them here.

The Grand Canyon storage array has room for 72 drives in a 4OU OpenRack enclosure, split into two control planes. Each control plane has a “Barton Springs” microserver with a single 26-core “Cooper Lake” Xeon SP processor, 64 GB or 128 GB of DDR4 memory, a pair of 2 TB E1.S flash units, Broadcom SAS controllers and extenders, and a 50 Gb/sec OCP 3.0 network interface that will eventually be upgraded to 100 Gb/sec. This is dense storage, not necessarily fast storage.

Accelerated Databases In The Fast Lane
Hardware accelerated databases are not new things. More than twenty years ago, Netezza was founded and created a hybrid hardware architecture that ran PostgreSQL on a big, wonking NUMA server running Linux and accelerated certain functions with adjunct accelerators that were themselves hybrid CPU-FPGA server blades that also stored the …
Can Nvidia Be The Biggest Chip Maker In The Datacenter?
Next year, with the launch of the “Grace” Arm server processors, Nvidia will have all of the compute and networking bases it cares about in the datacenter covered, and it will be selling its technology at a rapid pace. Nvidia already has a larger datacenter business than AMD has – …
Chip Roadmaps Unfold, Crisscrossing And Interconnecting, At AMD
After its acquisitions of ATI in 2006 and the maturation of its discrete GPUs with the Instinct line from the past few years and the acquisitions of Xilinx and Pensando here in 2022, AMD is not just a second source of X86 processors. Now, without question, it is a formidable …
Cooper Lake? I thought that was dropped. Was it produced just for Facebook?
Just for 4-way and 8-way machines, conversely just like Ice Lake was just for 2-way machines. Both were supposed to be full product lines.
“Meta today announced its next-generation AI platform, Grand Teton, including NVIDIA’s collaboration on design.”
https://blogs.nvidia.com/blog/2022/10/18/meta-grand-teton/
Cheap MAINFRAME wanna be!!!
Get smart – GO BIG IRON!!
;-]