

The best defense is a good offense, and as it turns out, the best offense is also a good offense. So while AMD is all polite-like in its presentations, rest assured that with the ever enwidening and embiggening Epyc server chip lineup, AMD is absolutely meaning to bring offense to Intel, the Arm collective, and any RISC-V upstarts that think it is a pushover.
Six new CPUs in the “Zen 4” family of chips – that is the fourth generation of the Zen core used in the Epyc processors – were unveiled this week, three with a streamlined Zen 4c core aimed at hyperscalers and cloud builders and three with 3D V-Cache to boost the L3 cache on the devices and thereby boost certain HPC workloads by around 1.7X. The Epyc family of server CPUs using the Zen 4 core types will have four distinct instantiations compared to one for the “Naples” Epyc 7001 generation from 2017 and the “Rome” Epyc 7002 generation from 2019 and two from the “Milan” Epyc 7003 generation that started rolling out in 2021. This is what Lisu Su, chairman and chief executive officer at AMD, called the company’s “Epyc journey” in her keynote opening up the Data Center & AI Technology Premiere hosted by the company in San Francisco yesterday.

From this point on, we can expect for every Epyc generation to have at least four variations, and if AMD makes an Instinct MI300C, as is rumored, that would make five. The rumored MI300C would have only Genoa compute chiplets, likely based on the Zen 4 cores, not the Zen 4c cores, married to somewhere between 128 GB and 256 GB of HBM3 memory, depending on if AMD used four-high or eight-high memory stacks and anywhere from four to eight stacks were activated on the package. The HBM3 specification allows for 16-high DDR5 chip stacks running at 6.4 GT/sec data transfer rates at a density of 64 GB, so in theory one could build a monster MI300 series package with 512 GB of memory and 8.3 TB/sec of aggregate bandwidth – all against a potential twelve chiplets with eight Zen 4 cores per chiplet for a total of 96 cores.
Such an Instinct MI300C – or MI400C based on the future Zen 5 cores – would certainly give the current HBM version of the “Sapphire Rapids” Xeon SP, known as the Max Series CPU, a run for the HPC and possibly AI host money.
Who knows if this will come to pass? It might be too much of a niche product for AMD to go for it. But if it does, that would be five variations in an Epyc generation.

We have four at this point, starting with the general purpose “Genoa” chips launched in November 2022 and moving into the “Bergamo” and “Genoa-X” chips launched this week, aimed at hyperscalers and cloud builders and technical computing workloads, respectively. We will see the “Siena” Zen 4 server chips later this year, aimed at telcos and other service providers and aimed straight at the Xeon D that is one of the bright spots in Intel’s Network and Edge Group, or NEX. And we have no doubt that many of us will mix up the ”Siena” and “Sierra Forest” codenames from AMD and Intel, respectively. Sierra Forest is Intel’s answer to Bergamo, and those future server CPUs will use its “energy efficient” E-cores rather than the “high performance” P-cores used in its general purpose Xeon SPs.
The Road To Bergamo Starts In the Cloud
To a certain extent, the heftiness of the X86 core is due to the need to support fatter chunks of code in legacy Windows Server and Linux workloads. For newer cloud native architectures that are based on microservices – meaning smaller chunks of code – that are linked over service busses and other mechanisms, having a big beefy core does not help improve system performance. These jobs tend to be less sensitive to L3 cache as well.

The monolithic applications that run well on more general purpose CPUs tend to have a lot of data locality and they also tend to get started on a machine and sit there, whirring away, and not necessarily anywhere near the capacity of the machine and not necessarily with a lot of contention for compute, memory, or I/O capacity. Not so cloud native applications, of which a lot of different and often ephemeral ones are crammed onto a single machine; they often do not have a lot of data locality, either, so big fat caches are not always a help.
So AMD worked with the hyperscalers and cloud builders to create a variant of the Zen 4 core that chopped out some cache and sometimes simultaneous multithreading (which introduces extra security risks because cores are sometimes shared by virtual machines) and reimplemented a completely ISA-compatible Zen 4c core to help them drive performance per watt rather than just performance as the general purpose Zen 4 cores in the Genoa chips do. Siena will drive dollar per performance per watt and longevity, both of which the telcos and service providers need and that anyone deploying systems to the edge will need, too. But we would add that for certain workloads hyperscalers are driven by the overall TCO more than other factors. We would also point out that Siena will not necessarily use the Zen 4 core. It could turn out that the Siena CPU will use the Zen 4c core, or a mix of Zen 4 and Zen 4c cores, on a single package. Why not? Cell phones do, so why not cell towers?
The Bergamo Zen 4c core is about 35 percent smaller than the Genoa and Genoa-X Zen 4 core is:

Because the Zen 4c cores are 35 percent smaller, AMD can cram more of them into an Epyc server socket. But AMD didn’t just cram more cores into the dozen compute complexes that are used on the biggest of the Genoa Epyc 9004 series processors. Rather, it reduced the number of compute cores dies, or CCDs, on the Bergamo chip from twelve to eight and jacked up the core counts on each CCD from 8 cores to 16 cores. This means the number of domains is smaller even as the core count increased from 96 cores to 128 cores on the package.

If you get down into the microarchitecture of the Zen 4 and Zen 4c architectures, not much really changes, so this chart is included below mostly because it is funny:

Yup, L3 cache is cut from 4 MB per core to 2 MB per core. Gotcha.
The Bergamo chips are known as the Epyc 97X4 series, and the X means “variable number” not the same as the X used in Milan-X and Genoa-X processors to mean “those with 3D V-Cache.” Perhaps calling those with the V-Cache Milan-V and Genoa-V would have been better? Anyway, here are the three Bergamo SKUs:

It was interesting to us that Alexis Black Bjorlin, who is vice president of infrastructure at Meta Platforms and who we talked to recently about its homegrown MTIA AI inference compute engines, took the stage with Su and kept talking about comparisons between Milan Epycs and the new Bergamo Epycs. That says two things. First, the company that coerced Intel into creating the Xeon D server chip to meet its performance per watt goals for its own edge serving already has “hundreds of thousands” of Epyc servers running “thousands of applications.” And second, with a factor of 2.5X performance improvement – we presume that is throughput performance – it sure as hell doesn’t look like Meta Platforms is going to skip the Bergamo chips in the Zen 4 generation to await Sierra Forest, the kicker to the Xeon D.
Looking at the top bin parts, the Bergamo Epyc 9754 chip, which costs $11,900 a pop when bought in 1,000-unit trays, has 128 cores running at 2.25 GHz and has about 25 percent more relative performance oomph – that’s cores times clocks times generational IPC uplift compared to a baseline “Shanghai” Opteron 2387 with four cores running at 2.8 GHz – than the than the Genoa Epyc 9654, which has 96 Zen 4 core running at 2.4 GHz and which costs $11,805. When you do the math, that is 19.3 percent better price/performance.
The Bergamo Epyc 9754S turns off simultaneous multithreading and drops the price to $10,200, and this is the one we think the hyperscalers and cloud builders will go for, which yields a 30.9 percent improvement in bang for the buck (and so by definition). The Epyc 9734 is a unique beast in that it has 112 cores running at 2.2 GHz and is not really comparable to any particular Genoa SKU. But at $9,600, it offers 6.9 percent more performance than a 96-core Genoa Epyc 9654 and 24 percent better bang for the buck.
If you don’t need the cache, don’t spend the cash. But if you need even more cache for your technical workloads that are cache sensitive, AMD has you covered with Genoa-X.
The Cache Triple Play
We are not going to going to go over the intricate details of the 3D Vertical Cache, or V-Cache for short, all over again. The process is similar to that used with the Milan-X chips, which launched in March 2022. This picture sums it up nicely:
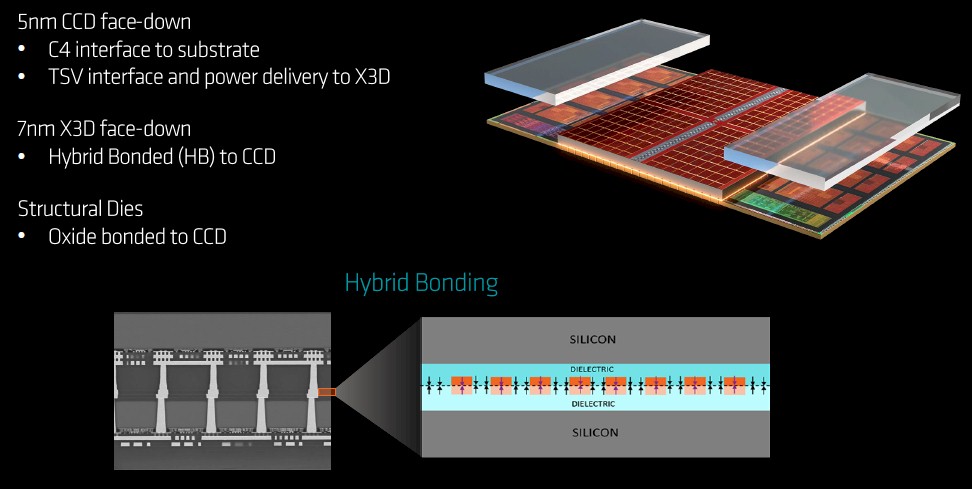
The Genoa chips, like the Milan chips before them, have TSV interfaces that allow an L3 segment to be flipped and stacked on top of the L3 cache area in the center of a Genoa compute core die. The L3 cache cannot be stacked on top of the Genoa cores themselves, which are etched in a 5 nanometer process. And even though the 3D V-Cache segment is etched in a 7 nanometer – both from Taiwan Semiconductor Manufacturing Co – the separate L3 cache has twice the density and therefore offers 64 MB of capacity compared to the 32 MB of cache on the Genoa complex itself. That gives you 96 MB per CCD, and with a dozen CCDs on a socket, that is up to 1,152 MB of L3 cache – remember when having 1 GB of main memory was a big deal? – on the top-bin Genoa-X part with 96 cores.
On technical workloads – think electronic design automation, computational fluid dynamics, finite element analysis, and structural analysis – the 3D V-Cache yields somewhere around 1.7X more performance, a little bit better than on the Milan-X, which was around 1.6X. In the table below, which shows the Genoa-X SKUs in blue bold italics underlined, our relative performance figures show the 1.7X uplift for the oomph to give us a way to calculate relative price/performance compared to the plain vanilla Genoa CPUs.
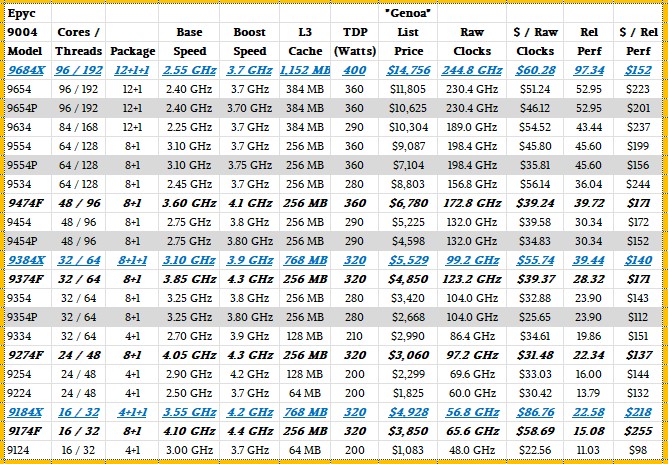
On the 96-core parts, the bang for the buck improves by 32 percent even as the cost of the Genoa-X, at $14,756, is 25 percent higher. The delta in price/performance is only 22.2 percent on the Epyc 9348X compared to the Epyc 9374F, and is only a little better than the standard Epyc 9354 part. But the performance increases are there, and technical customers want that performance.
On last thing. This spider graph below is great for framing the Genoa, Genoa-X, and Bergamo chips against each other in a visual fashion:

Up next, we will take a look at the competitive analysis that AMD has cooked up for the Genoa, Genoa-X, and Bergamo chips against Intel’s Sapphire Rapids and Ampere Computing’s Altra Max Arm CPUs, and try to assess how they might stack up to the forthcoming 192-core “Siryn” AmpereOne CPUs from Ampere Computing. And while we are at it, we will ponder the Graviton3 Arm server CPUs from Amazon Web Services against Bergamo as well.
We really want to get a sense of how CPUs plus HBM play against CPUs with lots of L3 cache, which are the two different approaches that Intel and AMD are taking to tackle technical workloads. Imagine if a CPU had 3D V-Cache and HBM3 memory. . . .




Is the Zen-4c 16 Core CCD a unified 16 core design where all 16 cores have access to the CCD’s Full Complement of L3 cache or is that just 2, 8 core CCX units on one CCD there with a topology that’s similar to Zen-2’s and each CCX-Unit(Even ones on the same CCD) having to communicated with each other via the I/O Die in a roundabout way? And that would require the least amount of re-engineering but still have 8 cores sharing the same L3 with the other 8 core CCX on the same CCD looking logically like a separate CCD as far as the logical topology was concerned. And I have read some semianalysis content about Zen-5c being a new Unified 16 Core design with what was called “ladder” L3 cache and some new unified 16 core CCD topology there. AMD needs to Include a CCD and I/O die Topology Diagram with for Each Zen generation to avoid confusion there with regards to the CCX/CCD core groupings and how they communicate via the I/O die on Zen-2/later Zen generations. The Zen-1 Zeppelin Die was the only Zen generation where the Compute-Complex-DIEs actually directly communicate with each other as there was no I/O die on that Zen-1/MCM Topology.
Interesting article, I can see the clouds and HPC (my main interest really) going for the new servers.
What would 3D-vcache AND HBM3 on the same CPU package look like?… like the MI300C, 96 Genoa core variant. The 6nm I/O dies that the CPU dies are stacked on will have cache.
More or less, yes.