

Last fall ahead of the SC21 supercomputing conference, AMD said it was going to be the first of the major compute engine makers to add 3D vertical L3 cache to its chips, in this case to variants of the “Milan” Epyc 7003 series of processors that debuted in March 2021 called the “Milan-X” chips. And today, just ahead of the kickoff of the annual Nvidia GPU Technical Conference, AMD is playing spoiler and adding four fat-cache Milan-X variants to the third generation Epyc 7003 series of CPUs.
The technique for adding 3D vertical L3 cache to the processor complex is very interesting, and gives us a preview into how chip real estate might be better utilized in the near future in all kinds of chips. And we think that chips used to create compute engines will not be just 2D or even 2.5D, but will increasingly have a 3D element to them – not all of the elements of the complex at first, mind you. But in this way, compute engines are getting to be less like suburbs and are becoming more like major cities – and for much of the same economic and temporal reasons, as it turns out, that drive cities to reach for the sky.
As we have previously reported, the Milan-X processor represents AMD’s need to diversify its CPU, GPU, and now FPGA lineup to capture more of the compute engine market, which is getting more diverse as Moore’s Law runs out of gas and hardware has to be tailored to specific workloads.
At the very least we think that there is a good possibility that going forward there will be “X” variants of all CPU and maybe even GPU generations that sport 3D V-Cache. But the vertical L3 cache approach could also open up more real estate in the two dimensions of the server CPU socket so it could be used to add more cores or larger I/O dies across compute complex.
But that is a topic for another day. For now, we want to focus on how AMD has constructed the 3D vertical L3 cache for the Milan-X variants, what the new SKUs of the Milan lineup are with the X designation, and how the chips compare to regular Milan CPU complexes. We will do a performance analysis versus the “Ice Lake” Xeon SP processors from Intel in a follow-up article.
A Big Vertical Jump
In this case, the Milan-X chips are aimed at boosting the performance of electronic design automation, computational fluid dynamics, finite element analysis, and structural analysis simulations – all of which scale their performance very well when given extra L3 cache to keep the processors on a CPU busy, as it turns out.
“This isn’t a hammer looking for nail,” explains Sam Naffziger, corporate fellow and product technology architect at AMD. “This is a very well-considered, strategic plan to make our server processors much more competitive and offer much higher performance.”
The slowdown in Moore’s Law has hit different parts of the compute engine differently, and at different times, and Naffziger described the situation before getting into the specifics of how 3D V-Cache was constructed and before Ram Peddibhotla, corporate vice president of product management for datacenter products at AMD, talked about the four new Milan-X SKUs, giving us enough insight to calculate some relative performance ratings for Milan versus Milan-X for the four HPC workloads that Milan-X is aimed at.
“Caches are wonderful things,” Naffziger continues. “They provide very low energy, low latency local storage that for many applications services their bandwidth demands. Going outside of the chip to memory or off-die to other storage devices costs a lot of energy and it costs a lot of latency.”
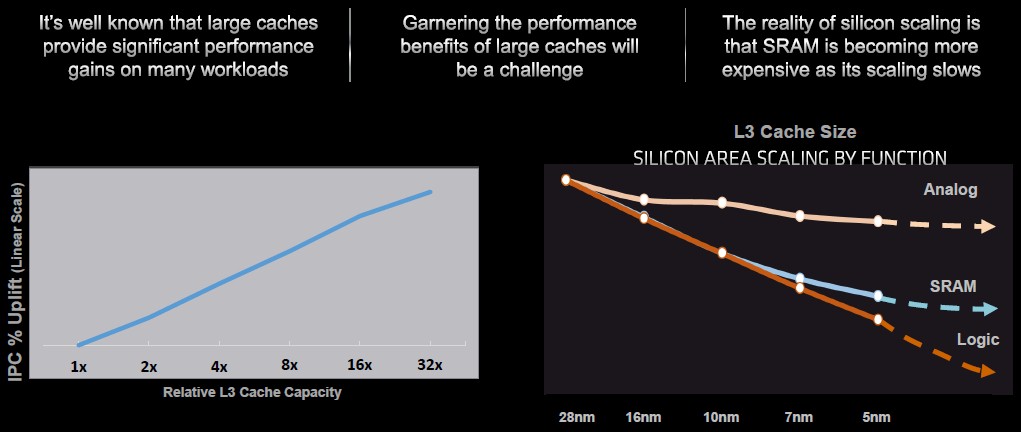
There is, as Naffziger shows in the chart above, a direct correlation between the increasing size of cache and the increasing of instructions per clock (IPC) for a CPU core. But the problem is that the rate of scaling of the SRAM that is used to make L3 caches is slowing, like happened for the I/O portions of the CPU complex (which comprise memory controllers and other I/O controllers) several years ago, as you see on the right hand side of the chart. The logic part of the compute complex – the cores and their L1 and L2 caches – have been scaling pretty well by comparison. The fact that analog, digital, and SRAM components are scaling at different rates – or have hit the Moore’s Law wall at different times, more accurately – is why AMD moved to a chiplet architecture that put the memory and I/O die on a 14 nanometer and then 12 nanometer process and pushed core dies to use 14 nanometer and then 7 nanometer processes.
While SRAM has “scaled nicely” at the 7 nanometer node, looking ahead Naffziger says that it is “falling off the curve.” Moreover, just adding a larger and larger L3 cache to any processor has its own challenges. If AMD wanted to double or triple the L3 cache on a compute complex die (CCD) makes that chiplet a lot larger, which reduces the area available for the cores within a given space. The yield of a chip is somewhat proportional to its size, so larger chips would have lower yields, too, which affects the cost of the chip. And finally, making the L3 cache bigger in two dimensions means the distance across the cache is bigger, which increases the latency of the cache and therefore can actually hinder the performance gains out of the compute engine.
And so AMD worked with Taiwan Semiconductor Manufacturing Co to come up with the 3D V-Cache.
You night be thinking that with the 3D V-Cache AMD is just copying the same L3 cache segments that are on the Milan CCD and pasting it twice in two layers above the CCDs and then connecting them through-silicon vias (TSVs) much as DRAM is stacked up and linked using TSVs to make HBM memory commonly used in GPU accelerators and now some CPUs. But that is not how it is done, and AMD has been a lot more clever than that.
AMD took the L3 cache design on the Milan CCDs and completely removed the ring bus to create the X3D vertical cache segment. And when it did that that, AMD could make the vertical L3 cache memory twice as dense. (The bus and tags eat up that much real estate, which was surprising to us.) The signal TSVs pointing up from the Milan die out of the 32 MB of L3 cache on the CCD were there from the beginning (they are dark silicon on the plain vanilla Milan chips). The signal TSVs pointing down from the 64 MB X3D L3 cache add-on match up perfectly to the upward pointing TSVs on the Milan chip and they are welded together chemically, copper to copper, using a hybrid bonding technique, like this:
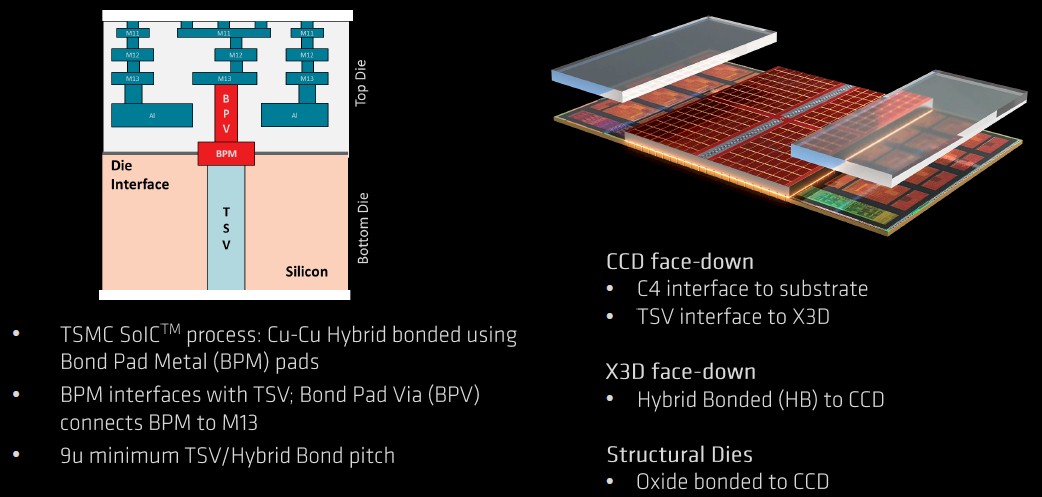
From the point of view of the Milan CCD cores in the Epyc 7003 package, the latency to a vertical L3 cache segment is essentially the same as the latency to the L3 cache on the Milan CCD. (Brilliant, that.)
The 3D V-Cache can only be stacked above the Milan CCD cache segments and for heating and cooling reasons, it cannot be stacked above the cores in the CCDs. And given the uniform latency provided by going 3D, thanks to the sharing of the ring bus on the Milan CCDs, you wouldn’t want to do this any other way. Dummy structural dies are oxide bonded to the parts of the CCDs that have the Milan cores so that heat transfer up to the heat sink above the Milan-X package remains the same. Depending on the load on the Milan-X dies, they dissipate between 225 watts and 280 watts, with the 280 watt rating being the top-end allowed on the SP3 socket used with “Rome” Epyc 7002 and Milan Epyc 7003 processors.
That 3D V-Cache in the Milan-X chips can be enabled with a BIOS update, which is great for OEMs and ODMs, who do not want to have to qualify new motherboards or systems to use the Milan-X processors. The L3 cache memory bandwidth, at more than 2 TB/sec, is unchanged because the L3 ring bus structure has not really changed with the vertical cache addition. And just with the regular Milan chips, the Milan-X allows for all of the L3 cache to be allocated to a single active core if that floats your boat.
Now that you see how the 3D V-Cache was added to the Milan complexes, here is how the Milan-X SKUs stack up against the Milan chips announced a little more than a year ago:
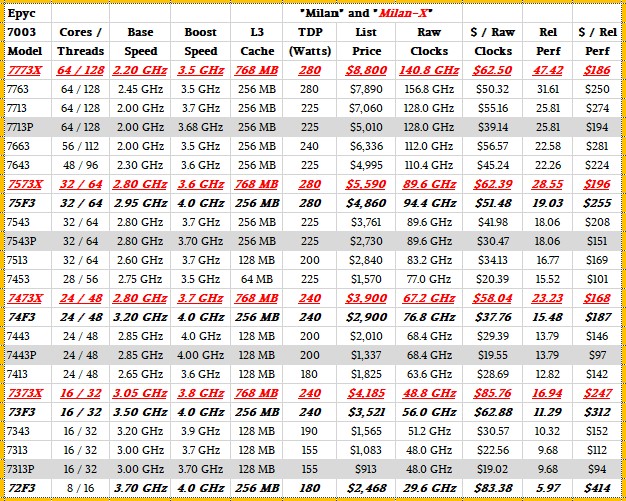
The four Milan-X chips in the Epyc 7003 series lineup are shown in bold red italics. AMD reiterated that on the Synopsys VCS EDA tool, running a simulation of an unspecified AMD graphics card, the 16-core Milan-X chip, the Epyc 7373X, performed 66 percent more RTL verification jobs in an hour than the regular 16-core Milan-X chip, which we presume was the HPC variant known as the Epyc 73F3. But in November, when the Milan-X chip was previewed, AMD said that the Milan-X chips provided an average of a 50 percent performance boost over their Milan equivalents. And so we have used a 1.5X factor to reckon the relative performance between the Milan-X and their Milan F series kin (where there is one).
As you can see, in many cases the clock speed on the cores in the Milan-X are slowed relative to the speed on the closest equivalent Milan chip, which lowers the raw performance, and then the overall performance of the Milan-X chip comes out way ahead by the tripling of the L3 cache without adding any cache latency. On the chips, the wattages for the Milan-X are the same as for the Milan equivalents, do this performance boost passes straight through as a performance per watt increase of 50 percent; on the other two Milan-X chips.
So the net effect is that even with a price increase moving to the Milan-X that ranges from 10.8 percent to 34.5 percent, depending on the Milan-X SKU, the price/performance improves by 20.8 percent to 25.6 percent for three of the Milan-X SKUs. The Epyc 7473X is a bit pricey relative to its performance boost and the bang for the buck only improves by 10.3 percent. Tell AMD to drop the price of the Epyc 7473X by $700 to $3,200 and to drop the price of the Epyc 7373X by $200 to $3,185 and all will be in perfect alignment when it comes to price/performance.
Here is an interesting bit of information that Peddibhotla shared about which Milan-X SKUs were aimed at what workloads, and this makes sense if you think about how sensitive certain HPC workloads are not only to L3 cache but to clock speed:

One last thing when considering the Milan-X chips. If you take a Milan-X and throw other kinds of workloads at it, ones that are not as sensitive to the size of the L3 cache, then you are going to get far worse bang for the buck. The clocks get slower and the chip gets more expensive, and the net loss in price/performance can be dramatic. You can get a gauge of this within the Milan family by using the cost per raw aggregate clock cycles metric in the table above, which does not adjust for IPC changes across generations and which does not include the effect of the 3D V-Cache boost for the four HPC workloads outlined above.
Remember that our relative performance is reckoned against performance of the four-core “Shanghai” Opteron 2387 processor running at 2.8 GHz, which had a mere 6 MB of cache and which cost a mere $873 when it came out in November 2008. You can see how the Milan-X chips stack up against these Shanghai chips as well as against the two prior Naples Epyc 7001 and Rome Epyc 7002 processors here.
Stay tuned for an analysis comparing the Milan-X Epyc 7003s from AMD to the Ice Lake Xeon SPs from Intel.

AMD “Dimensions For Success” In The Datacenter
Only two quarters ago, AMD’s datacenter business – meaning sales of Epyc CPUs plus Instinct GPU accelerators – broke through $1 billion. And it was a big deal. If current trends persist, this business will break through $1.5 billion in the first quarter of 2022 and $2 billion in either …
A Deep Dive Into Datacenter And Server Spending Forecasts
Spending on AI systems in 2024 just utterly blew by the expectations of the major market researchers and those who dabble in metrics like we do. There has just been an unprecedented amount of spending, mostly for systems that are accelerated by Nvidia GPUs. It remains to be seen how …
Datacenter Will Be AMD’s Largest – And Most Profitable – Business
Two and a half years into the global coronavirus pandemic we all have upgraded our home IT infrastructure. And after several fibrillatory interest rate shocks by the major governments to try to curb inflation in the world economy, spending on PCs has consequently taken a nose dive. And a glut …
Be the first to comment