
AMD has been absent from the X86 server market for so long that many of us have gotten into the habit of only speaking about the Xeon server space and how it relates to the relatively modest (in terms of market share, not in terms of architecture and capability) competition that Intel has faced in the past eight years.
Those days are over now that AMD has successfully got its first X86 server chip out the door with the launch of the “Naples” chip, the first in a line of processors that will carry the Epyc brand and, if all goes well, carry AMD back into the datacenter where it can reap some revenue and profits as companies look for alternatives – and we think lower cost alternatives – to what the world’s largest chip maker provides.
The Epyc chips have been a long time in the making, with five years of rethinking how to make a better core and a better system than it had done in the later generations of the Opteron processors that put AMD on the server processor map back in the early 2000s. The world has changed a lot since then, of course, but the two socket server still reigns supreme, and with the Epyc architecture AMD has hopes of shaking up the order of things and selling fully loaded one-socket Epyc systems head-to-head against the mainstream, mid-line Xeon E5 processors that are typically deployed in two-socket systems in the datacenters of the world today. It will also sell its two-socket machines against beefier Intel boxes, but forgo expanding its line to systems with four or more sockets using NUMA clustering as Intel does. AMD has been trickling out performance stats here and there, pitting the Epyc chips against Intel’s current “Broadwell” Xeon E5 processors, and it has also been banging the drum for hybrid setups that marry the Naples Epyc processors with its “Vega” Radeon Instinct GPU accelerator cards for running HPC and machine learning workloads.
It is an ambitious strategy, and it is not guaranteed to work, but it does fit the data of the market pretty cleverly and gives AMD a fighting chance to get a slice of the server pie once again. And once that happens, AMD can fund more research and development and try to take an even bigger chunk.
With the Epyc launch down in Austin, Texas, what we finally get is a look at the feeds and the speeds of the Naples processors as well as a sense of how these chips stack up against the current Broadwell Xeon competition. AMD is also unveiling some features tucked away in the processors, including some interesting encryption circuits on the memory controllers that lock down data in flight.
The First In A Family
The initial members of the first generation of Epyc processors are known as the Epyc 7000s, and the very naming suggests that there will eventually be other members of the family. But thus far, AMD has been mum about this. Having said that, we have been expecting a converged CPU-GPU chip with 16 cores and an advanced but trimmed down GPU, and this could still yet come to pass and be very interesting for workstations and certain classes of servers that need to provide hybrid compute but do so in a much smaller form factor and power budget – and at a much lower cost, too. But no one is talking about this chip, and what it might be any more. And as we have previously pointed out, AMD could create or acquire a chipset that allows it to gang up multiple two-socket nodes in a NUMA cluster to expanding the memory addressing (it has several designs of its own from years gone by to tap), but thus far the company has indicated that it is not interested in such scale up capability. Suffice it to say, there is room in the line for the Epyc 3000, Epyc 5000, and Epyc 9000 should AMD decide to move up and down the market.
For the moment, AMD is intent on turning on all of the features in the Epyc 7000s for all of its SKUs and using this openness to try to wrestle some share away from Intel, which demarcates its server chip SKUs by on many dimensions, including core count, frequency, memory addressability, memory speed, interconnect speed, threading, and a slew of other features. In the Epyc 7000 line, AMD obviously has different SKUs with different numbers of cores and different clock frequencies, which all processor chip makers need to do to make the fullest use of their manufacturing yields to drive revenues. But the covers are off on memory capacity and speed and I/O capacity and bandwidth.
Importantly, Dan Bounds, senior director of enterprise products, tells The Next Platform that the future “Rome” generation of Epyc 7000 processors will be socket compatible with the Naples sockets, which means that motherboard and system makers can re-use their systems with the future Rome chips that are anticipated in early 2018 according to the company’s roadmaps. While AMD is not making any promises about socket compatibility beyond that, it would probably be best for the company if that same socket was used for the “Milan” Epyc 7000 series expected sometime before 2020 (it looks like maybe late 2019 in the roadmaps). Bounds is not committing to any path, but did warn us not to jump to the conclusion that the Milan socket would be incompatible. AMD is keeping its options open, depending on how technologies change in the server racket and how its server partners would respond to such a change. The typical cadence is to keep a socket for two generations these days, but those making a commitment to Epyc may require more longevity, and that puts an engineering constraint on the future even as it makes the present more possible.
The Epyc 7000s are system-on-chip designs, which means they do not require an external chipset to operate in single-socket mode or two expand out to two-sockets with NUMA interconnects. All the necessary I/O for linking the sockets is on the chips, as are all of the controllers to link out to memory and peripherals. Conceptually, here is what the Epyc 7000 block diagram looks like:
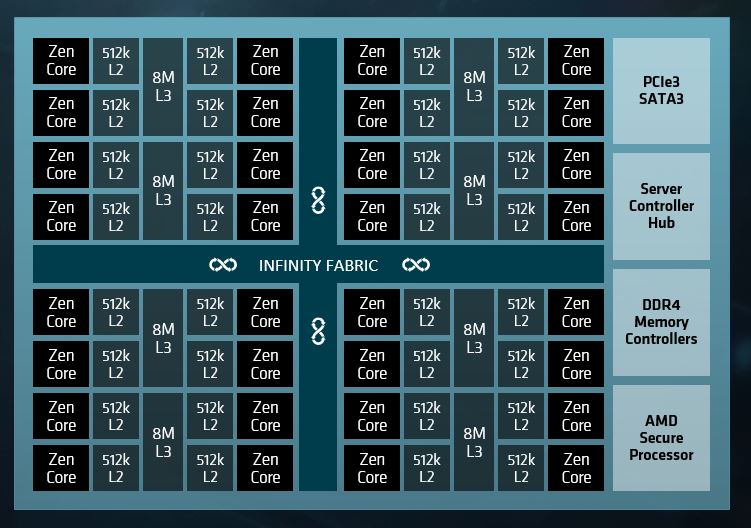
Do not take this diagram literally. The Epyc 7000 is actually comprised of eight separate processors that share a common socket and that are linked to each other through an on-package implementation of the Infinity fabric that is also used to scale out to a second socket, to main memory, to GPU accelerators, to flash storage, and to other PCI-Express 3.0 devices.
The computing elements on the Ryzen desktop and Epyc server chips are based on a four-core computing complex that looks like this:
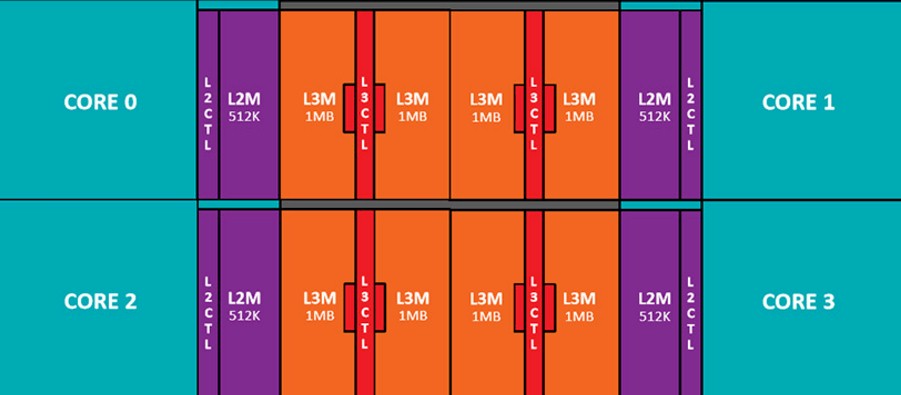
As you can see, the architecture uses a cores-out design, with the L3 memory controllers striped amongst the L3 cache and feeding into the L3 caches, which in turn are glued to the Zen cores by an L2 cache controller. The interconnect sits between all of these caches and cores and is used to link two four-core compute elements together; as far as we know, this is not the Infinity fabric as AMD talks about it. Each core has a 32 KB L1 cache and a dedicated 512 KB L2 cache, and there are eight slices of L3 cache that weigh in at 1 MB each that are segmented in 2 MB sections adjacent to each core but all cores can reach all caches (with varying latencies, of course). Two of these four-core compute elements are on a single chip, and there is no reason other than economics and yield that AMD did not just place all 32 cores on a single die. But placing eight cores on a die and then stitching them together using the Infinity fabric interconnect means that AMD can make a much cheaper 32-core socket than if it had did it as one 32-core monolith or even two 16-core segments.
Here is what the back of the package showing the four dies looks like:

One of the issues that many of us are thinking about is what the latency and bandwidth is between those chiplets on the package, and how this may – or may not – impact performance. We don’t have any information about the latencies to move data across these segments of the Naples processor package, but AMD did supply us with some information about the bandwidth, as follows. Take a look:

From this chart, we see that the bisectional bandwidth across the Infinity fabric links (there are four per chiplet) within the package is the same as the memory bandwidth for each Epyc 7000 socket. The NUMA interconnect running over half of the 128 PCI-Express 3.0 lanes when they are used to create a two-socket Epyc system provide the same 170 GB/sec of bandwidth. As the slide above suggests, AMD thinks there is plenty of bandwidth between the chiplets and across the sockets; what we want to know is what the relative latencies are between the chiplets on the die and across those two sockets. We would also like to get a sense what happens when the system is loaded up with lots of peripheral I/O – for instance, when the machine is loaded up with lots of GPU accelerators and flash memory – and also has a workload that has a lot of communication across those chiplets and sockets.
The new Secure Memory Encryption feature allows for memory to be partitioned and the segments to have their data encrypted in a way that does not impact application performance because the AES-256 cryptography is done in hardware, right on the memory controllers. This encryption is only available for memory that plus into the DIMM slots, which right now means DDR4 memory but in the future could mean NVDIMMs or 3D XPoint memory. Any encryption that is needed for flash or disk storage – data really at rest – has to be done with software-based encryption running on the CPU or offload accelerators added to the system. This SME feature, says Bounds, is aimed at securing all memory accesses, but is particularly useful for clients that are setting up multitenant systems where it is particularly bad for one user to see the data of another. This memory encryption works hand-in-glove with Secure Encrypted Virtualization, which encrypts the data stored on virtual machine instances on top of hypervisors. All of this functionality is transparent to the operating system and hypervisors and does not require any changes to applications. “This is the security that you can actually use,” says Bounds.
The Feeds And Speeds And Slots And Watts
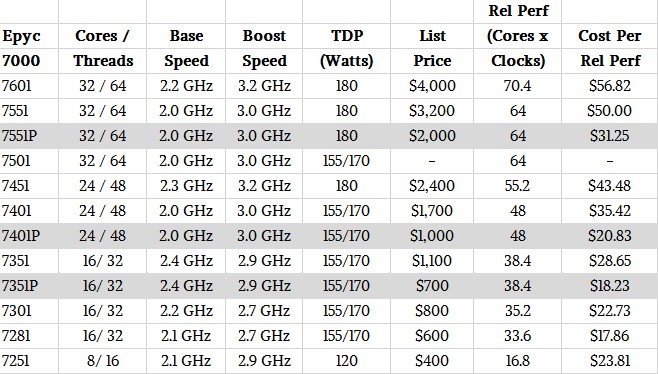
With the Epyc 7000s, all processors can be used in systems with either one or two sockets, but AMD has a few SKUs that are tuned up specifically to make the single socket a little extra juicy. Those chips designed with the extra bang for the buck for single-socket work have a P at the end of their names.
Each Epyc 7000 socket has eight memory channels, each with two DIMMs hanging off of it, and using 128 GB memory sticks (which no one does), the memory capacity can reach 2 TB per socket. With much less expensive 32 GB memory sticks, 512 GB is quite reasonable, and this is a very good amount of memory per socket. The Epyc 7000s can run with either 2.4 GHz or 2.67 GHz main memory, and in certain models, using the faster memory results in a 170 watt TDP instead of the 155 watt TDP. Clearly, the memory controllers have to work harder in some models to run faster and it is generating more heat.
Here is how the Epyc 7000s stack up against each other:
AMD has stacked up the Epyc 7000s against the current Broadwell Xeons, and at a given price point, it thinks it can deliver somewhere between 45 percent and 60 percent better bang for around the same bucks.
Here is how AMD thinks its Epyc 7000s in single-socket configurations perform on integer workloads, as gauged by the SPECint_rate_base_2006 part of the SPEC suite of CPU tests.
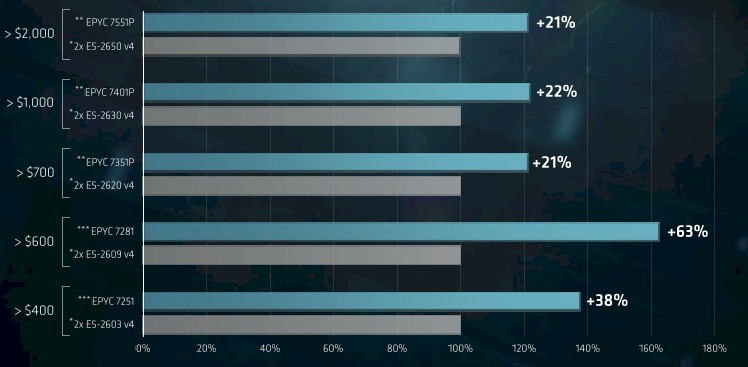
And here is how AMD did its comparisons for beefier two-socket configurations of the Epyc 7000s:
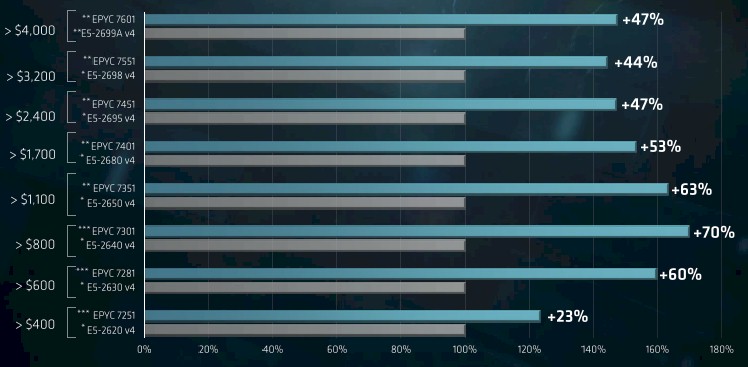
It is going to take some time to figure out if these comparisons make sense or not, and what we are really dying to do is make comparisons with the impending “Skylake” Xeons, which are due next month. But clearly, even with the performance gains we expect from Skylakes (around 8 percent or so improvement in instructions per clock plus more cores) AMD is going to still be able to compete against the Skylakes. Particularly if Intel doesn’t change its pricing.

The Server Recession Ends, And Both Intel And AMD Won
Anyone who thinks that Intel is easy to kill need look no further than the historical trends of the Mercury Research market share statistics that we see each quarter. Data for the third quarter of 2024 was just announced, and we have paired this with historical trends in shipments and …
Intel And AMD Make X Less Of A Variable For X86 Processors
One of the oldest ideas in humanity – and one that may have predated language as we know it – is that the enemy of my enemy is my friend. Another adage is that he who has the gold makes the rules, and in the datacenter market these days, the …

What Happens When Hyperscalers And Clouds Buy Most Servers And Storage?
We have a long-standing joke that dates from the early 2000s, when the hyperscalers – there were not yet cloud builders as we now know them – started having hundreds of millions of users and millions of servers and storage arrays to run applications for them at the same time …
“The Epyc 7000 is actually comprised of eight separate processors that share a common socket and that are linked to each other through an on-package implementation of the Infinity fabric that is also used to scale out to a second socket, to main memory, to GPU accelerators, to flash storage, and to other PCI-Express 3.0 devices.”
No That’s 4 Zeppelin dies(Max for EPYC currently) with each Zeppelin die supporting 2 memory channels per Zeppelin die with those 8 Zen cores grouped into 2 CCX Units of 4 Zen cores per CCX Unit, at 2 CCX units per Zeppelin Die. The Zeppelin die’s 2 CCX units communicate via the Infinity fabric CCX unit to CCX unit as well as to CCX units on other Zeppelin Dies on the same MCM and to other CCX units on other Zeppelin dies across the socket freeway to the other socket and its MCM complement of Zeppelin dies and their CCX units. The Infinity fabric interstate also goes to GPUs(Vega Town) and it’s thousands of NCU(Next Compute Units) and more than likely that Infinity fabric interstate will go to FPGA/other localities and even other mainboards and clusters(EPYC supports OpenCAPI and other protocols also).
Please if you can try at all times to use AMD nomenclature and naming conventions as well as endeavor to create a glossary of relevant AMD definitions so there can be a common language with common AMD terminology or confusion will reign supreme.
AMD seem focused on Data Center. Did AMD mention any partnership with Cray or HPE in HPC business ? Inventec solution seems rather impressive (100 Tflops in 2U rack !). May be are they waiting for massive rampup from GloFo to provide enough epyc/instinct chiplets for that particular market ?
What’s the difference between regular and P versions (e.g. 7401 and 7401P) of EPIC CPUs (except price)?
P is a single socket model, without P is a dual socket.
Yup. I thought I made that clear in the story. . . (smile)
It looks like Epyc and Vega are seriously competetive with Intel and Nvidia.
Skylake-SP doesn’t seem to have any advantages over Epyc, only disadvantages with their new Platinum, Gold, Bronze segmentation.
The secure memory encryption is also going to mean Epyc has the advantage over Intels hardware backdoored AMT chips and competes with Oracle’s SPARC for a fraction of the cost, using x86 hardware.
I can imagine how cheaply one could build a very competent supercomputer with all AMD at this point. The only disadvantages I see compared to Volta are: lack of FP64 and lack of tensor cores.
However, given that you can buy 12 Vega GPUs for the price of one V100, it might not be such a big deal. You could also get 5x Vega for the price of one P40, and Vega is better on paper.
SPARC M7 is 2-3x faster than the fastest Intel X86, all the way up to 11x faster in database and other enterprise benchmarks. It is true that EPYC is closing in on the SPARC M7 for a fraction of the cost. It is also true that SPARC M7 scales up to 16 sockets. EPYC scales to 2-sockets. So for the largest workloads such as large SAP installations, you have no other choice than SPARC. POWER8 also scales up to 16-sockets, but POWER8 is slower than Intel Xeon. EPYC totally demolishes POWER8 and competes with POWER9. If POWER9 is only 2x faster than POWER8 then EPYC beats POWER9 as well.
Oh and apparently AMD has 48bit physical addressing, so you could make a 256TB shared memory system, as opposed to Intel Skylakes 46bit 64TB maximum.
I wonder if HPE/SGI would use these Epyc CPUs for a UV style system.
Seems like this could be a huge advantage for AMD in shared memory systems.
Even Lisa seems blown away by the possibilities open to AMD’s architecture and products, and most of all by it’s apuS. “This is just the start.”
I muse about the humble apu’s possible server roles?
They do seem to get spectacular opengl results, as I would expect from such tight integration of the two processors.
An epyc mcm could hold 4x raven ridge dies, each w/ 32 CU vegaS & 4 cpu cores.
If as you say, Fabric can link to other moboS, then it could link to multiple embedded raven ridge products afaik?
Yes, raid nvme ports on an hbcc equipped Vega (as exists in $5k ssg pro Vegas) could be a huge asset for; reducing bus congestion, huge memory address, …..
I was thinking “what would HPC systems using Epyc actually look like?” and came up with a couple interesting thoughts.
2TB of 8 channel RAM per socket would allow for a good byte/flop ratio. I can imagine an all-CPU system for analytics or other applications that run well on latency optimized cores, as opposed to GPU friendly workloads, using HDR Infiniband in a topology that minimizes latency for large memory footprint workloads.
Just 512 nodes would give 1PB of DRAM, and with all the PCI-e lanes you could easily put several TB of Samsung Z SSDs for high QoS, low latency storage. That should be on par with a Skylake Optane setup.
For machine learning workloads, the big Vega GPU has plenty of FP16 and 32 performance, and if I’m not mistaken, it has its own NVMe controller on it, so it could have its own nonvolatile near storage.
A two socket Epyc server with 4TB of RAM and a few Vegas with SSDs attached to both the CPUs and GPUs should be quite good for deep learning workloads. It would be like a DG-X1 minus the DP FLOPS and tensor cores. Probably a fraction of the price too, if the $1,100 price of Vega Frontier is any indication.
Lots of very interesting stuff from AMD for a change. I can’t wait to see how their stuff performs with AI and HPCG type workloads.
I’m sure I’m not the only one that noticed … Based on the Atkins report recomendations of a balanced HPC system, 8-core Epyc cpu looks like a perfect match. Not to mention the price 😉
For a long time hpc people were complaining about lack of memory bandwidth in modern systems. Now we’ll finally have a system with 8 cores, 8 dimm channels and lots of IO available. Looks like latencies will be the the make-or-break for this configuration. I’m sure Dr.Bandwidth will have some interesting things to say here 🙂
The Atkins Report is from 2003.
More recently AMD has said in their Video ( https://youtu.be/5MPlS8RF0zE?t=1h37m25s ) titled “A New Era in the Datacenter” that an AMD 7601(32 Cores) supports 6 Radian Instinct Cards (150 TFlops FP16 from 384 Compute Units) and the Video shows a 1U with 4 Instinct Cards in it.
The “balance” you want depends upon the Workload. The “problem” you don’t want is a Bottleneck – the 7601 works with 6 Instinct Cards, no bottleneck.
The MI25 Cards aren’t being released until Dec ’17 and pricing remains unannounced – the bottom end Card is U$1K.
IF the MI25 is less than U$3K the a 100 TFlops System will cost under U$20K – something else probably not considered in the Atkins Report. Just 10 years ago we’d be lucky to get one TFlop on the Desktop.