

Changing the compute paradigm in the datacenter, or even extending it or augmenting it in some fashion, is no easy task. A company, even one that has raised $720 million in seven rounds of funding in the past six years, has to be careful to not try to do too much too fast and lose focus while at the same time adapting to the conditions in the field to get its machines doing real work and proving their worth on tough tasks.
This is where machine learning upstart and wafer-scale computing pioneer Cerebras Systems finds itself today, and it does not have the benefit of ubiquity that the Intel X86 architecture or the relative ubiquity that the Nvidia GPU architecture have had as they challenged the incumbents in datacenter compute in the 1990s and the 2010s, respectively.
If you wanted to write software to do distributed computing on these architectures, you could start with a laptop and then scale the code across progressively larger clusters of machines. But the AI engines created by Cerebras and its remaining rivals, SambaNova Systems and Graphcore and possibly Intel’s Habana line, are large and expensive machines. Luckily, we live in a world that has become accustomed to cloud computing, and now it is perfectly acceptable to do timesharing on such machines to test ideas out.
This is precisely what Cerebras is doing as it stands up a 13.5 million core AI supercomputer nicknamed “Andromeda” in a colocation facility run by Colovore in Santa Clara, the very heart of Silicon Valley.
This machine, which would cost just under $30 million if you had to buy it, is being rented by dozens of customers who are paying to use it to train on a per-model basis with cloud-like pricing, Andrew Feldman, one of the company’s co-founders and its chief executive officer, tells The Next Platform. There are a bunch of academics who have access to the cluster as well. The capacity on Andromeda is not as cheap and easy as running CUDA on an Nvidia GPU embedded on a laptop in 2008, but it is about as close as you can get with a wafer-scale processor that would not fit inside of a normal server chassis, much less a laptop.
This is similar to the approach that rival SambaNova Systems has taken, but as we explained when talking to the company’s founders back in July, a lot of customers are going even further and are tapping SambaNova’s expertise in training foundation models for specific use cases as well as renting capacity on its machines to do their training runs.
This approach, which we think all of the remaining important AI training hardware vendors will need to take – that would be Cerebras, SambaNova, Graphcore, and, if you want to be generous, Intel’s Habana Labs division (if it doesn’t shut it down as part of its looming cost cuts) –is not so much a cloud or hosting consumption model as it is the approach IBM took in the 1960s at the dawn of the mainframe era with its System/360s. Back then, you bought a machine and you got white glove service and programming included with the very expensive services because so few people understood how to program applications and create databases underneath them.
Andromeda is, we think, a first step in this direction for Cerebras, whose customers are very large enterprises and HPC centers who already have plenty of AI expertise. But the next and larger round of customers – the ones that will constitute a real revenue stream and possibly profits for Cerebras and its AI hardware peers – are going to want access not just to flops, but deep expertise so models can be created and trained for very specific workloads as quickly as possible.
Here are the basic feeds and speeds of the Andromeda system:

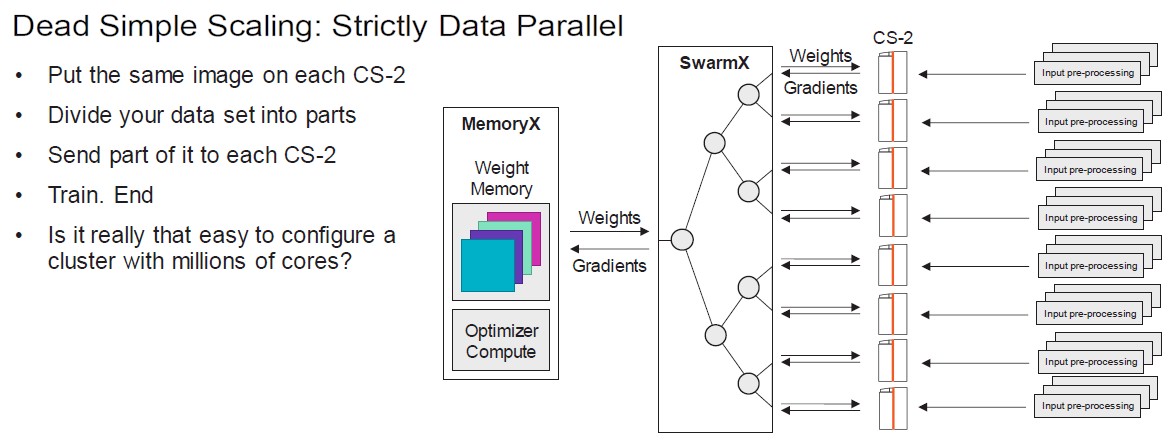
Each of the CS-2 nodes in the Andromeda cluster has four 64-core AMD Epyc processors in it that do housekeeping tasks for each of the WSE-2 wafers, which have 2.6 trillion transistors implementing 850,000 cores and their associated 40 GB of SRAM. That embedded SRAM memory on the die has 20 PB/sec of aggregate bandwidth, and the fabric implemented between the cores on the wafer has an aggregate bandwidth of 220 Pb/sec. Cerebras calls this mesh fabric linking the cores SwarmX, and a year ago this interconnect was extended over a dozen 100 Gb/sec Ethernet transports to allow the linking of up to 192 CS-2 systems into a single system image. Across those 16 CS-2 machines, the interconnect fabric has 96.8 Tb/sec of aggregate bandwidth.
Just like you can plug FPGAs together with high speed interconnects and run a circuit simulation as a single logical unit because of the high speed SerDes that wrap around the FPGA pool of configurable logic gates, the Cerebras architecture uses the extended SwarmX interconnect to link the AI engines together so they can train very large models across up to 163 million cores. Feldman says that Cerebras has yet to build such a system and that this scale has been validated thus far only in its simulators.
That SwarmX fabric has also been extended out to what is essentially a memory area network, called MemoryX, that stores model parameter weights and broadcast them to one or more CS-2 systems. The SwarmX fabric also reduces gradients from the CS-2 machines as they do their training runs. So the raw data from training sets and the model weights that drive the training are disaggregated. In prior GPU architectures, the training data and model weights have been in GPU memory, but with fast interconnects between CPUs and GPUs and the fatter memory of the CPU, data is being pushed out to the host nodes. Cerebras is just aggregating parameter weights in a special network-attached memory server. The SwarmX fabric has enough bandwidth and low enough latency – mainly because it is actually not running the Ethernet protocol, but a very low latency proprietary protocol – to quickly stream weights into each CS-2 machine.
By contrast, the 1.69 exaflops “Frontier” supercomputer at Oak Ridge National Laboratories has 8.73 million CPU cores and GPU streaming multiprocessors (the GPU equivalent to a core), and 8.14 million of those are the GPU SMs that comprise 97.7 percent of the floating point capacity. At the same FP16 precision that is the high end for the Cerebras precision, Frontier would weigh in at 6.76 exaflops across those GPU cores. AMD does not yet have sparse matrix support for its GPUs, but we strongly suspect that will double the performance as is the case with Nvidia “Ampere” A100 and “Hopper” H100 GPU accelerators when the Instinct MI300 GPU accelerators – which we will start codenaming “Provolone” as the companion to “Genoa” CPUs if AMD doesn’t give us a nickname soon – ship next year.
In any event, as Frontier is with its Instinct MI250X GPUs, you get 6.76 exaflops of aggregate peak FP16 for $600 million, which works out to $88.75 per teraflops for either dense or sparse matrices. (We are not including the electric bill for power and cooling, the cost of storage – just the core system.)
That’s a lot of flops compared to the 16-node Andromeda machine, which only drives 120 petaflops at FP16 precision with dense matrices but very much importantly delivers close to 1 exaflops with the kind of sparse matrix data that is common with the foundational large language models that are driving AI today.
Hold on. Why is Cerebras getting an 8X boost for its sparsity support when Nvidia is only getting a 2X boost? We don’t know yet, but we just noticed that and are trying to find out.
The WSE-2 compute engine only supports quarter precision FP16 and half precision FP32 math, plus a proprietary format called CB16 floating point format that has 6 bit exponents; regular IEEE FP16 has 5 bit exponents, and the BF16 format from Google’s Brain division has 8 bit exponents which makes it easier to convert to FP32 formats. So there is no extra boost coming from further reduced precision down to, say, FP8, FP4, or FP2. As far as we know.
At $30 million, the 16-node Andromeda cluster costs $250 flat per teraflops for dense matrices, but only $31.25 per teraflops with sparse matrices. It only burns 500 kilowatts, compared to the 21.9 megawatts of Frontier, too.
But here is the real cost savings: A whole lot less grief. Because GPUs are relatively small devices – at least compared with an entire wafer with 850,000 cores – running large machine learning models means chopping up datasets and using a mix of model parallelism (running different layers of the model on different GPUs that have to communicate over the interconnect) and data parallelism (running different portions of the training sets on each device and doing all of the work of the model on each device individually). Because the WSE-2 chip has so many cores and so much memory, the training set can fit in the SRAM and Cerebras only has to do data parallelism and only calculates one set of gradients on that dataset rather than having to average them across tens of thousands of GPUs. This makes it much easier to train an AI model, and because of the SwarmX interconnect, the model can scale nearly linearly with training data and parameter count, and because the weights are propagated using the dedicated MemoryX memory server, getting weights to all of the machines is also not a problem.
“Today, we can support 9 trillion parameter models on one CS-2,” says Feldman. “It takes a long time, but the compiler can work through them and it can place work and we can store it using MemoryX and SwarmX. We don’t do model parallelism because our wafer is so big that we don’t have to. We extract all of the parallelism by being strictly data parallel, and that is the beauty of this.”
To be honest, one of us (Tim) did not fully appreciate the initial architecture choice Cerebras made and the changes announced to it last year, while the one other of us (Nicole) did. That’s why we are each other’s co-processor. . . .
To be very clear, Cerebras is not doing model parallelism across those 16 CS-2 nodes in any fashion. Youi chop the dataset into the same number of pieces as the nodes you have. The SwarmX and MemoryX work together to accumulate the weights of the model for the 16 nodes, each with their piece of the training data, but the whole model runs entirely on that subset of data within one machine and then the SwarmX network averages the gradients and stores the final weights on the MemoryX device. Like this:
The scaling that the Andromeda machine – it was very hard to not say Strain there – is seeing is damned near linear across a wide variety of GPT models from OpenAI:
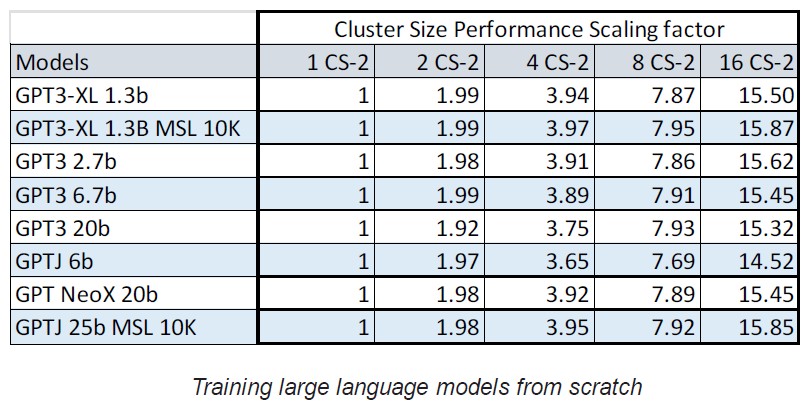
With each increase in scale, the time it takes to train a model is proportionately reduced, and this is important because training times on models with tens of billions of parameters are still on the order of days to months. If you can chop that by a factor of 16X, it might be worth it – particularly if you have a business that requires retraining often.
Here is the thing. The sequence lengths – a gauge of the resolution of the data – keep getting longer and longer to provide more context for the machine learning training. AI inference might have a sequence length of 128 or 256 or 384, but rarely 1,024 but training sequence lengths can be much higher. In the table above, the 1.3 billion GPT-3 and 25 billion GPT-J runs had 10,240 sequence lengths, and the current CS-2 architecture can support close to 50,000 sequence lengths. When Argonne National Laboratory pit a cluster of a dozen CS-2s against the 2,000-GPU “Polaris” cluster, which is based on Nvidia “Ampere” A100 GPUs and AMD Epyc 7003 CPUs, Polaris could not even run the 2.5 billion and 25 billion GPT-3 models at the 10,240 sequence level. And on some tests, where a 600 GPU partition of Polaris was pit against the Dozen machines, it took more than a week for the Polaris system to converge when using a large language model to predict the behavior of the coronavirus genome, but the Cerebras cluster’s AI training converged in less than a day, according to Feldman.
The grief of using Andromeda is also lower in another way: It costs less than using GPUs in the cloud.
Just because Andromeda costs around $30 million to buy doesn’t mean that a timeslice of the machine is proportional to its cost, any more than the price that Amazon Web Services pays for a server directly reflects the cost of an EC2 instance sold from the cloud. GPU capacity costs are all over the map on the clouds, on the order of $4 to $6 an hour per GPU on the big clouds, and for an equivalent amount of training for GPT-3 models Feldman says that the Andromeda setup could cost half of that of GPUs – and sometimes a lot less, depending on the situation.
Happy Among The Accelerators
At least for now, Cerebras is seeing a lot of action as an AI accelerator for established HPC systems, often machines accelerated by GPUs and doing a mix of simulation and modeling as well as AI training and inference. And Feldman thinks it is absolutely normal that organizations of all kinds and sizes will be using a mix of machinery – a workflow of machinery, in fact – instead of trying to do everything on one architecture.
“It is interesting to me that this sounds like a big idea,” says Feldman with a laugh. “We build a bunch of different cars to do different jobs. You have a minivan to go to Grandma’s house and soccer practice, but it is terrible for carrying 2x4s and 50 pound bags of concrete and a truck isn’t. And you want a different machine to have fun, or to haul logs, or whatever. But the idea that we can have one machine and drive its utilization up to near 100 percent is out the window. And what we will have are computational pipelines, a kind of factory view of big compute.”
And that also means, by the way, that keeping a collection of machines busy all the time – and getting the maximum value out of the investment – is probably also out the window. We will be lucky, says Feldman, if this collection of machinery gets anywhere between 30 percent and 40 percent utilization. But this will be the only way to get all kinds of work done in a timely fashion.




Be the first to comment