

Why does Google need another database, and why in particular does it need to introduce a version of PostgreSQL highly tuned for Google’s datacenter-scale disaggregated compute and storage?
It is a good question in the wake of the launch of the AlloyDB relational database last week at the Google I/O 2022 event.
The name Google is practically synonymous with large scale data storage and manipulation in myriad forms. The company created the MapReduce technique for querying unstructured data that inspired Hadoop, the BigTable NoSQL database, the Firestore NoSQL document database, and the Spanner geographically distributed relational SQL database. These tools were used internally at first, and then put on Google Cloud as the Dataproc, Cloud BigTable, and Cloud Spanner services.
Relational databases are back in vogue, due in part by Google showing that a true relational database is can scale with the advent of Spanner. And to try to encourage adoption of Spanner on the cloud, Google last year created a PostgreSQL interface for Spanner that makes it look and feel like that increasingly popular open source database. This is important because PostgreSQL has become the database of choice in the aftermath of Oracle buying Sun Microsystems in early 2010 and taking control of the much more widely used open source MySQL relational database that Sun itself took control of two years earlier.
The reason why Google needs a true version of PostgreSQL running in the cloud is that it needs to help enterprise customers who are stuck on IBM DB2, Oracle, and Microsoft SQL Server relational databases as their back-end datastores for their mission-critical systems of record get off those databases and not only move to a suitable PostgreSQL replacement, but to also make the move from on-premises applications and databases to the cloud.
That is the situation in a nutshell, Andi Gutmans, vice president and general manager of databases at the search engine, ad serving, and cloud computing giant.
“Google has been an innovator on data, and we have had to innovate because we have had these billion user businesses,” says Gutmans. “But our strength has really been in cloud native, very transformative databases. But Google Cloud has accelerated its entrance into mainstream enterprises – we have booming businesses in financial services, manufacturing, and healthcare, and we have focused on heritage systems and making sure that lifting and shifting applications into the cloud. Over the past two years, we have focused on supporting MySQL, PostgreSQL, SQL Server, Oracle, and Redis, but the more expensive, legacy, and proprietary relational databases like SQL Server and Oracle have unfriendly licensing models that really force them into one specific cloud. And we continue to get requests to help customers modernize off legacy and proprietary databases to open source.”
The AlloyDB service is the forklift that Google created for this lift and shift, and don’t expect for Google to open up all of the goodies it has added to PostgreSQL because these are highly tuned for Google own Colossus file system and its physical infrastructure. But, it could happen in the long run, just as Google took its Borg infrastructure and container controller and open sourced a variant of it as Kubernetes.
As we have pointed out before, the database, not the operating system and certainly not the server infrastructure, is arguably the stickiest thing in the datacenter, and companies make database decisions that span one or two decades – and sometimes more. So having a ruggedized, scalable PostgreSQL that can span up to 64 vCPUs running on Google Cloud is important, as will be scaling it to 128 vCPUs and more in the coming years, which Gutmans says Google is working on.
But that database stickiness has to do with databases implementing different dialects of the SQL query language, and also having different ways of creating and embedding stored procedures and triggers within those databases. Stored procedures and triggers essentially embed elements of an application within the database rather than outside of it for reuse and performance, but there is no universally accepted and compatible way to implement these functions, and this has created lock in.
That is one of the reasons why Google acquired CompilerWorks last October. CompilerWorks has created a tool called Transpiler, which can be used to convert SQL, stored procedures, and triggers from one database to another. As a case in point, Gutmans says that Transpiler, which is not yet available as a commercial service, can convert about 70 percent of Oracle’s PL SQL statements to another format, and that Google Cloud is working with one customer that has 4.5 million lines of PL SQL code that it has to deal with. To help with database conversions, Google has tools to do data replication and scheme conversion, and has provided additional funding where they can get human help from systems integrators.
AlloyDB is not so much a distribution of PostgreSQL as it is a storage layer designed to work with Google’s compute and storage infrastructure.
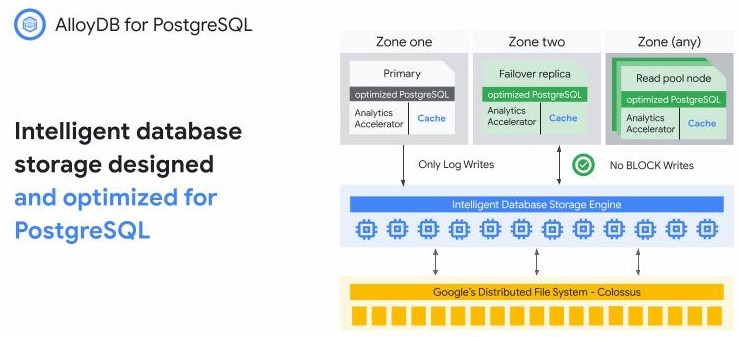
And while Google has vast scale for supporting multi-tenant instances of PostgreSQL, you will not that it doesn’t have databases that span hundreds or even thousands of threads. IBM’s DB2 on Power10 processors, which has 1,920 threads in a 240-core, 16-socket system with SMT8 simultaneous multithreading turned on, can grab any thread that is not being used by AIX or Linux and use it to scale the database, just to give you a sense of what real enterprise scale is for relational databases. But we are confident that is Google needed to create a 2,000-thread implementation of PostgreSQL, it could do it with NUMA clustering across its network and other caching techniques or by installing eight-way X86 servers that would bring 896 threads to bear with 56-core “Sapphire Rapids” Xeon SPs and 1,204 threads to bear with 64-core “Granite Rapids” Xeon SPs. (Again, the operating system would eat a bunch of these threads, but certainly not as much as the database could.) The latter approach – using NUMA-scaled hardware – is certainly easier when it comes to scaling AlloyDB, but it also means adding specialized infrastructure that is really only suitable for databases. And that cuts against the hyperscaler credo of using cheap servers – and only a few configurations of them at that – to run everything.
So what exactly did Google do to PostgreSQL to create AlloyDB? Google took the PostgreSQL storage engine and built what Gutmans called a “cloud native storage fleet” that is linked to the main PostgreSQL node, database logging and point in time recovery for the database runs on this distributed storage engine. Google also did a lot of work on the transaction engine at the heart of PostgreSQL and as a result, Google is able to get “complete linear scaling” up to 64 virtual cores on its Google Cloud infrastructure. Google has also added an “ultra fast cache” inside of PostgreSQL, and if there is a memory miss in the database, this cache can bring data into memory with microsecond latencies instead of the millisecond latencies that other caches have.
In initial tests running the TPC-C online transaction processing benchmark against AlloyDB, Gutmans says that AlloyDB was 4X faster than open source PostgreSQL and 2X faster than the Aurora relational database (which has a PostgreSQL compatible layer on top) from Amazon Web Services.
It’s Not Just About Performance
And to match the high reliability and availability of those legacy databases such as Oracle, SQL Server, and DB2, Google has a 99.99 percent uptime guarantee on the AlloyDB service, and this uptime importantly includes maintenance of the database. Gutmans says that other online databases only count unscheduled and unplanned downtime in their stats, not planned maintenance time. Finally, AlloyDB has an integrated columnar representation for datasets that is aimed at doing machine learning analysis on operational data stored in the database, and this columnar format can get up to 100X better performance on analytical queries than the open source PostgreSQL.
The PostgreSQL license is very permissive about allowing innovation in the database, and Google does not have to contribute these advances to the community. But that said, Gutmans adds that Google intends to contribute bug fixes and some enhancements it has made to the PostgreSQL community. He was not specific, but stuff that is tied directly to Google’s underlying systems – like Borg and Colossus – are not going to be opened up.
So now Google has three different ways to get PostgreSQL functionality to customers on the Google Cloud. Cloud SQL for PostgreSQL is a managed version of the open source PostgreSQL. AlloyDB is s souped up version of PostgreSQL. And Spanner has a PostgreSQL layer thrown on top – but it doesn’t have compatibility for stored procedures and triggers because Spanner is a very different animal from a traditional SQL database.
Here is another differentiator. With the AlloyDB service, Google is pricing it based on the amount of compute and storage customers consume, but the IOPS underpinning access to the database are free. Unmetered. Unlike many cloud database services. IOPS gives people agita because it cannot be easily predicted, and it can be upwards of 60 percent of the cost of using a cloud database.
AlloyDB has been in closed preview for six months and is now in public preview. General availability on Google Cloud is expected in the second half of this year.
Which leads us to our final thought. Just how many database management systems and formats does a company need?
“We think of ourselves as the pragmatists when it comes to databases,” says Gutmans, who is also famous as the co-founder of the PHP programming language and the Zend company that underpins its support. “If you look at the purpose built database, there is definitely a benefit, where you can actually optimize the query language and the query execution engine to deliver best in class price and performance for that specific workload. The challenge is, of course, that if you have too many of these, it starts to become cognitive overload for the developers and system managers. And so there’s probably a sweet spot in the middle ground between monolithic and multimodal. You don’t go multimodal completely because then you lose that benefit around price, performance, use case specific optimization. But if you go too broad with too many databases, it becomes complicated. On the relational side, customers definitely have at least one relational database and in many cases they also are dealing with legacy database. And with those legacy databases, we are definitely seeing more and more interest in standardizing on a great open source relational database. Document databases provide a lot of ease of use, especially under web facing side of applications when you want to do things like customer information and session management with a very loose schemas, to basically have a bag of information about a customer or transaction or song. I am also a big fan of graph databases. Graph is really going through a renaissance because not only is it very valuable in the traditional use cases around fraud detection and recommendation engines and drug discovery and master data management, but with machine learning, people are using graph databases to extract more relationships out of the data, which can then be used to improve inferencing. Beyond that, we have some other database models that, in my opinion, have some level of diminishing returns, like time series or geospatial databases.”
PostgreSQL has very good JSON support now, so it can be morphed into a document database, and it is getting geospatial support together, too. There is a reason why Google is backing this database horse, and getting it fit for the race. It seems unlikely that any relational database could have a good graph overlay, or that a graph database could have a good relational overlay, but that latter item is something to think about another day. . . .




Great article.
“It seems unlikely that any relational database could have a good graph overlay, or that a graph database could have a good relational overlay, but that latter item is something to think about another day. . . .” Check relational.ai