

A database technology called Bigtable that search engine giant Google launched internally more than a decade ago and has spent the ensuing years perfecting as the underpinning of its search engine and advertising business is going commercial. The software is not being open sourced and is not available for running on the servers in your datacenters, but Google has exposed Bigtable as a service on its Cloud Platform public cloud, pitting it against the Relational Data Services, DynamoDB, and Redshift data stores at Amazon Web Services and the SQL and NoSQL services available on Microsoft Azure.
Bigtable was invented by Google in 2004, and it was created explicitly by the company to take its MapReduce method of compute against its Google File System and turn it into something that had more of a look and feel of a traditional database. MapReduce and GFS have been emulated by Hadoop and its Hadoop Distributed File System, of course, and similarly Bigtable has been the inspiration behind the DynamoDB NoSQL database that Amazon created as the back-end for its online retailing operations when its SQL databases ran out of scale (several years after Google put Bigtable into production) and also for the Cassandra NoSQL datastore created by Facebook a few years after that for the very same reason. Google had Bigtable in production for two years before it put out a paper describing how it had dealt with database scaling issues with the database software layer. (Interestingly, Avinash Lakshman, the founder of stealthy storage startup Hedvig, worked on both the DynamoDB and Cassandra projects.) Neither Bigtable nor DynamoDB are open source, but Cassandra code is out there in the wild and is currently commercialized by DataStax.
Amazon put DynamoDB up on its public cloud in 2012 as a service and AWS continues to have a lead in terms of breadth and depth of services. But Google is no slouch and knows a thing or two more about scale than AWS does, particularly for petascale database work. And the company is touting its performance edge on NoSQL as a competitive advantage.
As the name suggests, BigTable takes the unstructured data housed in a file system like GFS and makes it look like a giant database table or spreadsheet from the point of view of programmers and applications. BigTable’s successor – and that is not precisely the right word, just like Omega is not precisely the successor to Google’s Borg job scheduling program but is much more of an augmentation of it – is a geographically distributed database called Spanner, and it runs atop of BigTable and a follow-on to GFS called Colossus, which is a geographically distributed file system.
BigTable is a key element of Google’s Mesa data warehouse, which is used to ingest and store the telemetry from its AdSense, AdWords, and DoubleClick advertising systems, which have an immense amount of data that they have to ingest. The Mesa database has petabytes of data and has to update millions of rows per second of data and process billions of queries per day that access trillions of rows of data.
In fact, Bigtable is underneath nearly all of Google’s services, including its core search as well as Gmail collaboration and Analytics web analytics.
Cloud Bigtable is the public cloud variant of the internal Bigtable software used by Google, and it is distinct from BigQuery, an ad-hoc query service for read-only data that Google launched in 2010 and that is based on the Dremel query add-on for MapReduce and GFS/Spanner. It is also different from Google’s Megastore, a hybrid database that blends the scalability of NoSQL with the programmability of a traditional relational database.
Cloud Bigtable is distinct in that it has been tweaked to look like the HBase distributed database layer that runs atop the MapReduce and HDFS combination in Hadoop. By adopting the HBase APIs from Hadoop, Cloud Bigtable is therefore compatible with scads of Hadoop applications that run atop HBase. Using HBase is a whole lot easier than writing MapReduce scripts in Java by hand and dispatching them to Hadoop, which is why Facebook created it in the first place, and importantly, the bulk ingestion and export tools that speak HBase will work with the Cloud Bigtable service.
Like DynamoDB at AWS and the Redis Cache and DocumentDB services at Microsoft Azure, the Cloud Bigtable service is fully managed – customers don’t load software on virtualized infrastructure and then load their data. Rather, Google opens up the plumbing and lets customers pump their data into Cloud Bigtable and it manages where the data is stored and processed transparently, giving customers the storage, compute, and networking capacity they need for their jobs. Cory O’Connor, product manager in charge of Cloud Bigtable, said in a blog post that customers can create a Cloud Bigtable cluster in a under ten seconds and that the backend systems will automatically scale as data is added. Google is also replicating the data that customers pump into Cloud Bigtable for durability and is encrypting the data as it comes in and out of the service and when it is as rest on the mix of disk and flash drives that underpin the Google Storage service on Cloud Platform.
Sources at Google tell The Next Platform that Cloud BigTable has exabytes of storage dedicated to it, and that a single database in use by customers can scale into the range of hundreds of petabytes. This is a lot of data, but for some large enterprises – especially those in financial services or cloud-native applications with zillions of users – this is the new normal.
The big thing that Google is emphasizing with its NoSQL server is performance and price.
“Now the decade of work we put into NoSQL is available to everyone using GCP,” Urs Hölzle, senior vice president of the Technical Infrastructure team at Google who steers its hardware and software development, commented on the announcement. “One way it shows that we’ve been working on this longer than anyone else: 99% read latency is 6ms vs ~300ms for other systems.”
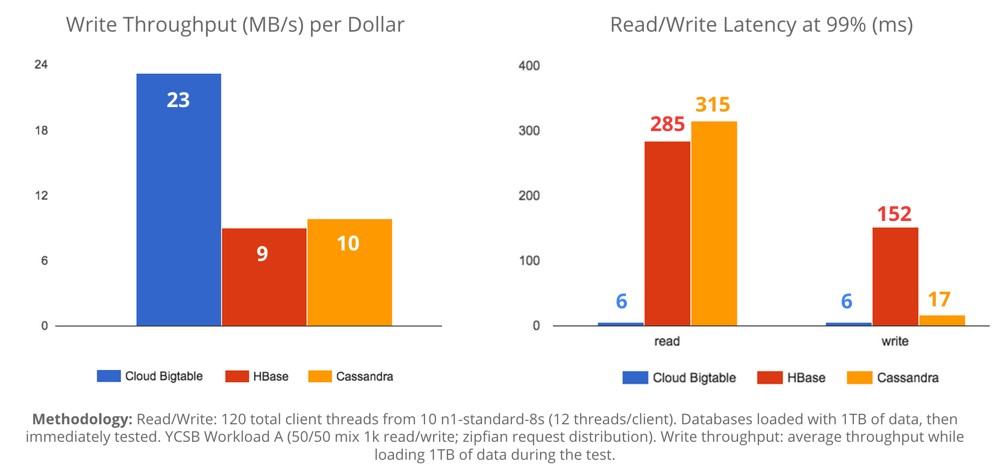
To size up Cloud Bigtable, Google’s engineers pitted it against HBase running on top of Hadoop as well as the Cassandra NoSQL datastore on a 1 TB database. That’s pretty modest size, of course, but not an unusual size for databases in the enterprise. The test that Google ran put Cassandra and HBase on Hadoop on Cloud Platform and pit the Yahoo Cloud Serving Benchmark (YCSB) against these datastores as well as Bigtable. As you can see from the chart, Cloud Bigtable is showing more than twice the write performance (as measured in MB/sec) per dollar as the HBase and Cassandra alternatives. The read latency that Google is able to show with Cloud Bigtable is, as Hölzle pointed out, incredibly lower than for HBase and Cassandra. Cassandra does a bit better on writes in terms of closing the gap, but BigTable is still winning. The other thing to consider is that Bigtable includes management by Google itself, while firing up Hadoop and HBase or Cassandra on Cloud Platform is something customers have to manage themselves – and this is not free.
Cloud BigTable is available now in beta from a number of Google regions today. It is only available in selected regions right now, and only with SSD flash backing it. Google will be adding support for storing data on disk drives within its Cloud Storage. Customers have to buy three nodes of capacity for Cloud Bigtable at a cost of 65 cents per node per hour with the nodes delivering 10,000 queries per second of performance and 10 MB/sec of data transfer each. SSD storage for the data that is exposed as a NoSQL datastore by the Cloud Bigtable service will cost 17 cents per GB per month, and on disk drives (which will obviously offer lower performance) it will cost only 2.6 cents per GB per month. There is some overhead for indexing that will go on top of the raw data customers store in Cloud Bigtable. As is standard in cloud services, it costs nothing to pump data into Bigtable, but it costs money to move data out or between Google datacenter regions, on the order of pennies per GB per month.


Google And Dell Pave The Way For File Data In The Cloud
A year ago, Dell Technologies made a significant push deeper into the fast-growing hybrid cloud space, unveiling its Dell Technologies Cloud initiative that includes hybrid cloud platforms that take advantage of the tight integration of technologies from Dell and VMware, which is majority owned by the larger company. The platforms …

With Huge Costs, Efficiency Is The Key To Mainstreaming Generative AI
The hype around generative AI is making every industry vibrate at an increasingly high pitch in a way that we have not seen since the days of the Dot Com boom and sock puppets. With promises of more automation and significant cost savings that could come to areas like customer …

A Tale Of Three Cloud Builders, All Seeking Dominance
While Amazon Web Services has first mover advantage when it comes to building a compute and storage cloud, it would be a mistake to believe that the division of the world’s largest online retailer can rest on its laurels. AWS has to work hard every day to make its cloud …
Be the first to comment