
To hardware or not to hardware, that is a real question for vendors peddling all kinds of software in the datacenter.
To get a bigger slice of the revenue and to help accelerate its installations, composable infrastructure and switch maker Liqid is grabbing the hardware bull by the horns and building out whole systems, called Think Tanks, with CPU and GPU compute as well as flash storage and networking and AI software stacks as well as its own PCI-Express switching hardware and its Matrix composable fabric software to accelerate its business.
By transforming itself into a systems vendor, Liqid is bucking a trend in the datacenter. Some relatively new companies, particularly storage vendors like Nutanix, Pure Storage, and Vast Data, started out as appliance vendors so they can limit the support matrix of hardware when they are a startup. They decide to go software-only because hardware is a pain in the neck and has very little profit margin in it, and because a certain percentage of their customers want to run on infrastructure out in the cloud or on OEM iron certified by their IT staff and under a discount and upgrade regime they already have in place.
“Selling bags of parts can be difficult, as you know,” George Wagner, director of product and technical marketing at Liqid, tells The Next Platform. “We have been selling our fabric and our enclosures and our add-on software and now our “Honey Badger” flash storage, and customers see the value in all of these. But at the end of the day, they are wondering how to put this all together.”
Or, we think more precisely, how they can get out of having to put this all together into a system. And so, with Think Tank, Liqid has decided to jump into the systems supply chain and design and have manufactured its own systems, which of course have the Matrix composable fabric at the heart of the compute and storage, and bridging over its EX-4400 PCI-Express enclosures, which launched in November last year and which have room for either ten or twenty PCI-Express devices that are disaggregated and linked to external servers as if they were local to the host machines by the Liqid Director switch and compute complex, where the Matrix fabric runs.
Here is the lineup of the Think Tank machines:

The compute capacity in the nodes is set at one or two CPUs for the machines ranging from four to sixteen GPUs, and has two nodes, with four CPUs, in a machine that spans up to 32 GPUs. All of the point-to-point capacities of CPU and GPU are configurable at the PCI-Express layer, and companies that want a higher ratio of CPUs or GPUs can add more of any given node; they may need more compute nodes, director switches, or PCI-Express enclosures, of course.
Here are the salient characteristics of the base Think Tank X4 system and then the larger machines that are built up from it:
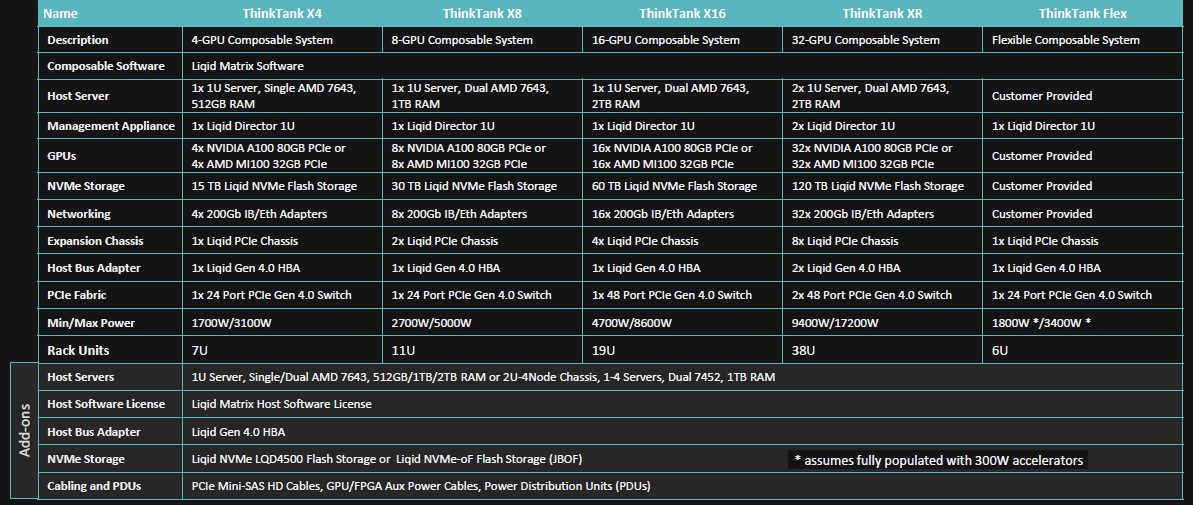
The Think Tank X4 is 7U high in the rack and has a one socket server eating 1U of that plus a 6U EX-4400 enclosure, which has a 1U server embedded inside of it to act as the director for the matrix software. The PCI-Express switching and PCI-Express peripherals occupy the rest of the enclosure. The host server in the Think Tank X4 has a single 48-core AMD “Milan” Epyc 7643 running at 2.3 GHz. There are four GPUs in the system, and they can be either Nvidia “Ampere” A100s or AMD “Arcturus” MI100 accelerators; the new “Aldebaran” MI210 and 250X GPUs from AMD, which debuted last November, are not yet available, but they are on the way. And presuming that Nvidia launches its “Hopper” GH100 GPUs next week, as is widely expected, we anticipate that once Liqid can get its hands on some, they will also be added to the Think Tanks. The EX-4400 has a 24-port PCI-Express 4.0 switch embedded in it, and the host system has four 200 Gb/sec network interfaces (either Quantum InfiniBand or Spectrum-3 Ethernet from Nvidia) and 15 TB of flash capacity from a single Honey Badger card that Liqid has designed for its own use.
The base Think Tank X4 system with four MI100 accelerators costs $150,000, which is half the price of Nvidia’s DGX-A100 system. On certain workloads – single precision floating point – four AMD MI100s can hold their own against four Nvidia A100s, but on other mixed precision, matrix math, and FP64 floating point, the A100s can best them – especially when considering the sparsity support that helps goose AI workloads. We shall see how the Nvidia Hopper GPU stands up to the Aldebaran GPU.
To expand the Think Tank system, all you do is stack ‘em up and interconnect them, and the fabric will let as many as 32 of the GPUs to be linked to any granularity of CPUs in the system. The whole idea behind disaggregation and composability is not only to get the right ratio for any particular AI training or inference job, but to allow the configurations to change as the AI workload pipeline changes, and free up expensive GPU and flash resources to be used to do other work. The neat thing – and we need to drill down into this at some point, is the native ioDirect peer to peer software layer Liqid has created to let any GPU talk to any other GPU or any flash adapter in the fabric without the overhead of the host CPUs getting in the way.
Depending on the GPUs that workloads are deployed to, the hosts can run Nvidia’s EGX Stack or AMD’s ROCm stack and the TensorFlow, PyTorch, or Kokkos machine learning frameworks. And while the Think Tank branding implies that this is for artificial intelligence only, there is no reason why GPU-accelerated HPC simulation and modeling workloads cannot run on these machines, and Wagner says that it is chasing HPC centers that don’t want to cobble their machines together, too.

Nvidia: There’s A New Kid In Datacenter Town
Unless you were born sometime during World War II, you have never seen anything like this before from a computing system manufacturer. Not the rise of Sun Microsystems, EMC, and Oracle during the Dot Com Boom, who were transformative to the commercialization of the Internet. And if the current trends …
The Next 100X For AI Hardware Performance Will Be Harder
For those of us who like hardware and were hoping for a big reveal about the TPUv5e AI processor and surrounding system, interconnect, and software stack at the Hot Chips 2023 conference this week, the opening keynote by Jeff Dean and Amin Vahdat, the two most important techies at Google, …
Inside Tesla’s Innovative And Homegrown “Dojo” AI Supercomputer
How expensive and difficult does hyperscale-class AI training have to be for a maker of self-driving electric cars to take a side excursion to spend how many hundreds of millions of dollars to go off and create its own AI supercomputer from scratch? And how egotistical and sure would the …
Be the first to comment