
For those of us who like hardware and were hoping for a big reveal about the TPUv5e AI processor and surrounding system, interconnect, and software stack at the Hot Chips 2023 conference this week, the opening keynote by Jeff Dean and Amin Vahdat, the two most important techies at Google, was a bit of a disappointment. But the Google talk did give us some food for AI thought experiments just the same.
It has been ten years since Dean, who has been instrumental in so many of the technologies that Google has created that he should probably never be allowed on an airplane or to go rock climbing, did some math on a scrap of paper and figured out that if Google added AI functions to its eponymous search engine that it would have to double the size of its datacenter footprint and sent Google down the path of creating its custom Tensor Processing Unit, or TPU, matrix math engines.
Ten years on, AI is more complex and compute-intensive and the much-discussed TPUv4 iron, while useful now and for many years to come, is looking a bit long in the tooth. The TPUv4 systems have been augmented by the TPUv5e, very likely based on 5 nanometer processes and very likely with at least twice the raw peak performance, running in Google datacenters. (We did a deep dive on the TPUv4 system in October last year, and have yet to update this with the optical switch interconnect that was revealed earlier this year and which will be discussed in detail at Hot Chips this week.)
And as we expected, some details about the TPUv5e variant used for both training and inference were revealed at the Google Cloud Next 2023 event that was happening at the same time as Hot Chips 2023, and we will get to all that shortly. We also expect that once cloud instances are available running TPUv5e, they will deliver around 30 percent better bang for the buck than the prior TPUv4 instances on Google Cloud. It could even turn out to have even better bang for the buck. We will have to see.
We chose the Google talks at Hot Chips over the Google Next keynote because when Dean talks, system architects need to listen. Dean has had a hand in almost all of Google’s core technologies: The MapReduce way of chewing on big data, the BigTable relational overlay for the Spanner distributed storage system, the TensorFlow and Pathways software that underpins the largest AI models in the PaLM family, the TPU hardware, and now the Gemini large language model that is going to be giving OpenAI’s GPT-4 and GPT-5 models a run for the money. (Well, everyone hopes there is money somewhere in this outside of the semiconductor fabs and the hardware makers.) Dean ran Google Research for many years and co-founded the Google Brain team that brought the best AI researchers and its DeepMind acquisition together and where he is currently chief scientist.
His keynote presentation was split with Amin Vahdat, who like Dean is also a Google Fellow and is currently vice president of engineering at the company, was a professor of computer science and engineering at the University of California at San Diego and director of its center for networked systems before joining Google in 2010, where he was technical lead for networking, then the technical lead for compute, storage, and networking, and more recently is now in charge of the Machine Learning, Systems, and Cloud AI team at the company as well as being responsible for systems research at Google. MSCA develops and maintains Compute Engine and Borg, the suite of CPU, TPU, GPU compute engines, the network lashing them together, and the entire AI software stack that is used in production by Google and its cloud customers.
Dean and Vahdat pretty much define and create Google infrastructure. It is unclear what role Urs Hölzle, also a Google Fellow and the company’s first vice president of engineering, then vice president of search, and for more than two decades senior vice president of engineering in charge of the Technical Infrastructure team, is currently playing from his new home in Auckland, New Zealand. At Hot Chips, Dean laid out the terrain for AI and Vahdat talked about the increasing demands and hardware to traverse that terrain.
Scaling The Exponential AI Curve
Google Research director Peter Norvig coined adage that “more data beats clever algorithms” a long time ago, and that still holds true and it is the very foundation of the large language models that have everyone so excited about AI these days. (Norvig also reminded everyone that better data beats more data, too.)
Dean said that Google is focused on three different approaches to driving AI models – sparsity, adaptive computation, and dynamic neural networks – and was also trying to have the AI snake eat its tail rather than nibble on it and truly have AI expert systems start designing AI processors to speed up the whole chip development cycle and thereby help get ever-improving hardware into the field to meet the faster-growing models.
Dean explained that with the AI models created thus far, the whole model, with its increasing layers and exploding number of parameters, driven by billions, then tens of billions, then hundreds of billions of token snippets of data, was activated each time the AI model trained on a new token or a token was presented against a finished model to do AI inference. But with frameworks such as Pathways, which underpins the PaLM family of models at Google, the world is moving away from having separate AI models that are specialized for different tasks to having a single foundation model.
We went over the scale of all of the biggest AI models recently when discussing AI startup Inflection AI, and remind you that the supersecret GPT-4 model from OpenAI, for instance, is estimated to have between 1 trillion and 1.76 trillion parameters and somewhere in the range of 3.6 trillion tokens that Google has with its PaLM-2 model, which spans over a hundred languages. This is both a large number of parameters to hold in the memory of compute engines and it is a lot of data to push through a model to train it. The corpus of global language knowledge increases every year by a certain amount, of course, and the parameter count can be driven higher to drive better quality inference. The large models will be used as a foundation to train smaller models – or to activate sections of the larger model that have been tuned to have a certain special knowledge, as Dean shows it using the Pathways framework:
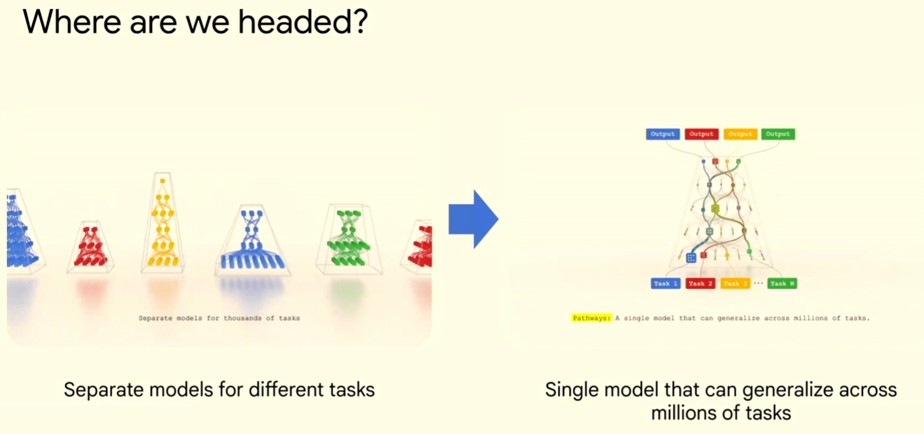
With the sparse models, the pieces of the AI model activate as they are needed, and only those pieces. How the model knows what pieces to activate is not clear, and that is the secret sauce in the Pathways framework that has been perfected with the Gemini model that no doubt uses the techniques that Dean is talking about. It is important to note that the Pathways framework is not open source like the earlier and presumably much more rudimentary TensorFlow framework created by Google that was open sourced back in November 2015. So we will only know what Google tells us about Pathways and Gemini. We hope Google publishes a paper on the Gemini AI model soon. There was a paper put out by Google in October 2021 concerning Gemini reconfigurable datacenter networks, in which Vahdat was one of the co-authors, but this does not seem to have anything to do with the Gemini LLM.
In any event, these foundation models can deal with many different modalities – images, sound, text, video – as well as only activate the model in a sparse fashion, dramatically cutting down on the computational cost to do further training and production inference.
“Rather than having this giant model, the sparse models can be much more efficient,” Dean explained. “They sort of just call upon the right pieces of the overall model – and the right pieces aspect is also something that is learned during the training process. Different parts of the model can then be specialized for different kinds of inputs. And the end result is you end up with something where you touch just the right 1 percent or the right 10 percent of some very large model and this gives you both improved responsiveness and higher accuracy, because you now have a much larger model capacity than you could train otherwise and then can call upon the right parts.”
There is another aspect of sparsity that is important for system architects to contemplate, according to Dean, something that is different from the fine grained sparsity that is commonly talked about with accelerators where sparsity within a single vector or tensor (typically where two of every four values in a matrix is set to zero, converting it from dense-ish to sparse-ish) and that is also different from the coarse-grained sparsity where large modules within a model are either activated or not. This sparsity looks like this, and we consolidated a couple of Dean’s charts onto one page so you could take it all in:
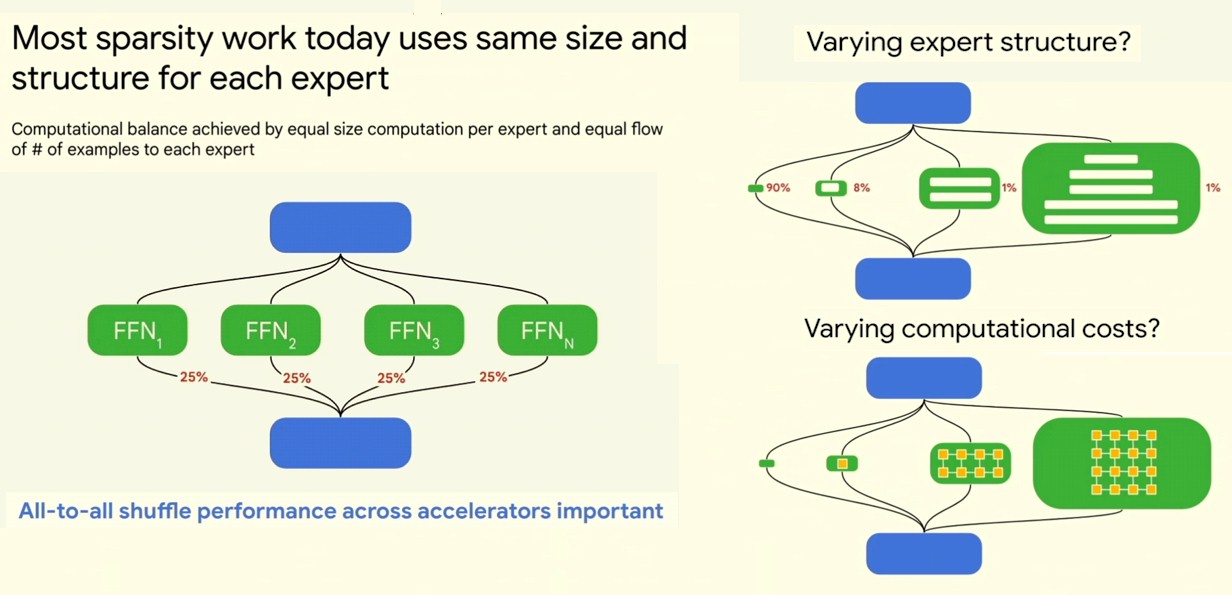
“Most sparsity work today uses the same size and structure for each expert,” Dean said. “So you have some set of green experts here for them. You have some learned routing function here that learns which expert is good at which kind of thing, and then you send some of the examples to the appropriate expert. And computational balance is typically achieved by having equal size computation per expert and equal flow of the number of examples to each expert. For computer architects, this means that all-to-all shuffle performance across accelerators is really important. This is true for sort of all sparse models – you want to be able to sort of quickly route things from one part of the model to the other in the right ways. One thing you might want to be able to do, though, is instead of having fixed computational costs is to vary the computational cost of different pieces of the model. And there’s no point in spending the same amount of compute on every example, because some examples are 100X as hard. And we should be spending 100X times as much computation on things that are really difficult as on things that are very simple.”
It turns out that some of the tiny experts might need only a small amount of computation and would be used for maybe 90 percent of the prompts in a model used in production. The experts get larger for doing more complex stuff, with different computational structures and more layers possibly, and they are more computationally intensive and therefore more costly to run. And if you are running an AI service, you will want to be able to attribute cost to the value of the expert answer delivered so you can charge appropriately.
The Path To More Efficiency And More Compute
This is not theory for Google – the reason the company is talking about it is because the Pathways framework does this:
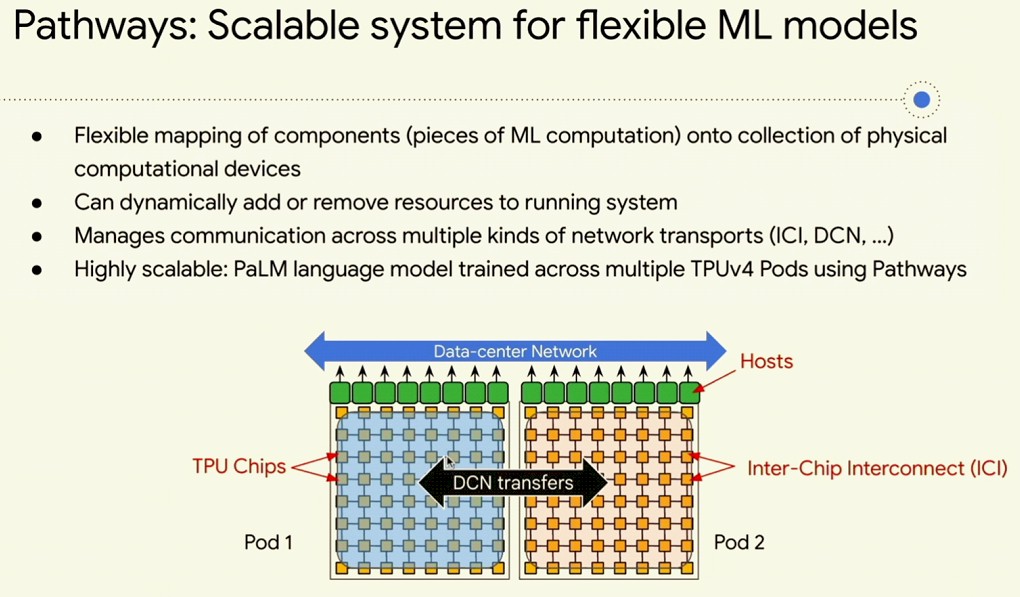
So that is sparsity and adaptive computation. The last thing to look for, says Dean, which is mentions in the chart above, is dynamic neural networks, which means that capacity can be added or removed from a running system – something we have had for general purpose servers for a few decades (although not in an X86 platform, oddly enough, and here is where Arm and RISC-V might be able to catch up with mainframes and RISC/Unix systems). What us true of CPUs and their workloads – there certainly is dynamic allocation at the hypervisor level – is also true of GPUs, TPUs, and other AI compute engines. You want to be able to dynamically add or subtract capacity from a pool of cores for any given model as it is running inference or training. The PaLM model with 500 billion parameters from Google was trained on Pathways and did so with dynamic allocation of resources across a pair of pods with 6,144 TPUv4 engines, but the TPUv4 engines were actually spread across six pods with a total of 24,576 engines, all linked through a high-speed datacenter network. Like this:
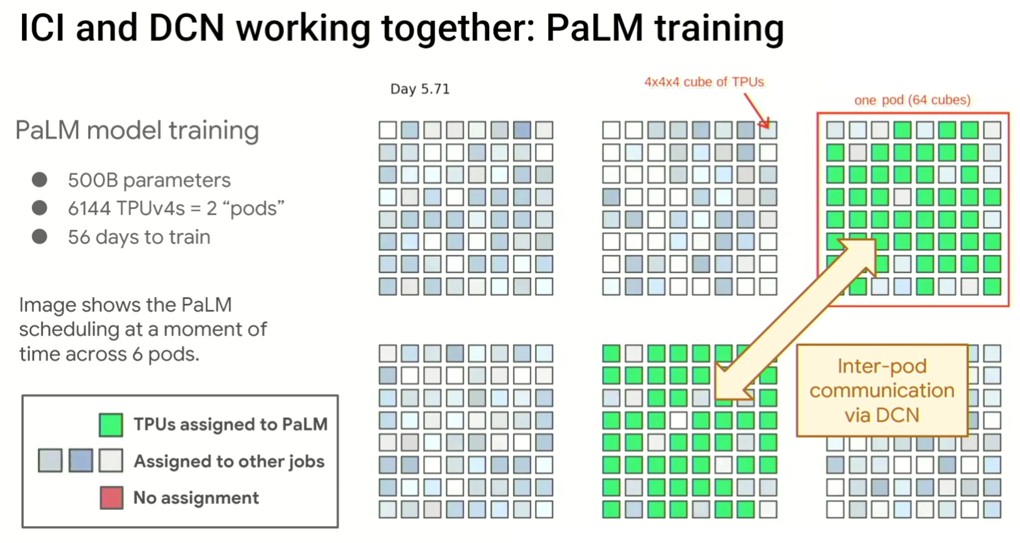
A TPUv4 pod is effectively a row of compute with copper links for a 4x4x4 torus cube of TPU engines and optical links in a torus of these cubes with 64 of them interlinked at the cube faces. PaLM took 56 days to train and this is a snapshot at day 5.71. The workloads changed a lot over time, and the PaLM job tried to stick together, more or less, for proximity and latency reasons, but moved around the cluster a bit like cellular automata.
Here are the key takeaways that Dean wanted to impress upon system architects:
- Connectivity of accelerators – both bandwidth and latency – matters
- Scale matters for both training and inference
- Sparse models put pressure on memory capacity and efficient routing
- ML software must make it easy to express interesting models – like that function sparsity shown in the chart above
- Power, sustainability, and reliability really matter
This is where Vahdat took over, and showed the exponential curve in model size growth that the AI industry is facing:
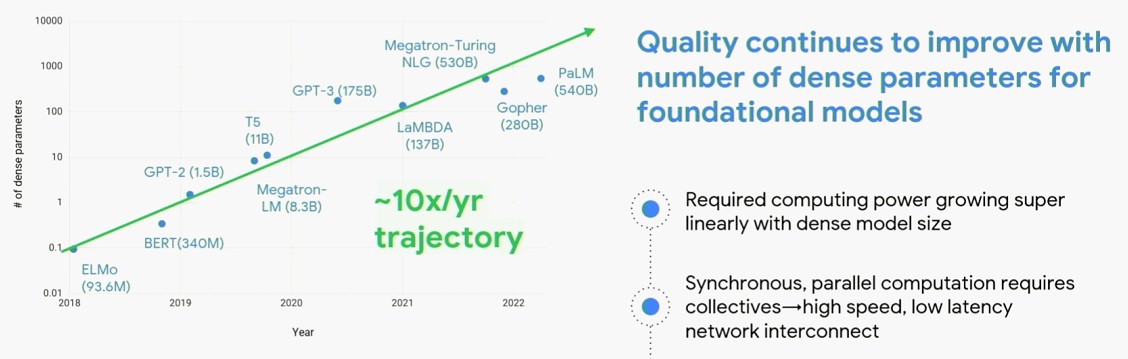
There is absolutely no reason to believe the model complexity and therefore the compute capacity requirements are going to slow down. But the models are growing at 10X per year and at best the performance of GPUs and TPUs is growing at 2X to 3X per year by our estimation. Companies have to make it up by scaling out, which is difficult, and by improving their models, which is also hard. We still have some numerical format tricks we can use and some sparsity tricks as well, but both will run out of room soon, we think.
This is why Google has deployed TPUv5e engines in its fleet already – and probably did two years ago if it is talking about it now – and why the TPUv6 with a possible letter extension like i or e is probably in the works right now and set for deployment soon to help support the commercialization of the Gemini model.
To get the 100X improvement in performance per TCO so far – and Vahdat gave a whole lecture on how this is how one needs to gauge the relative value of AI or general purpose compute platforms, and we have always agreed with this lone before there were AI systems – Google had to do a bunch of things:
- Create specialized hardware – the TPU – for dense matrix multiplication.
- Use HBM memory to boost the memory bandwidth by 10X into those matrix math engines.
- Create specialized hardware accelerators for scatter/gather operations in sparse matrices – what we now know are called Sparsecores and which are embedded in the TPUv4i, TPUv4, and likely the TPUv5e engines.
- Employ liquid cooling to maximize system power efficiency and therefore economic efficiency.
- Use mixed precision and specialized numerical representations to drive up the real throughput – what Vahdat calls “goodput” – of the devices.
- And have a synchronous, high bandwidth interconnect for parameter distribution, which as it turns out is an optical circuit switch that allows for nearly instant reconfiguration of the network as jobs change on the system and that also improves the fault tolerance of the machine. This is a big deal in a system that has tens of thousands of compute engines and workloads take months to run, as the HPC centers of thew world know full well.
“The kind of computing infrastructure that we have to build to meet this challenge has to change,” Vahdat said in his portion of the keynote. “And I think that it’s really important to note that we would not be where we are today if we tried to do this on general purpose computing. In other words, really, the conventional wisdom that we’ve developed over the past really 50 year to 60 years, has been thrown out the window. I think it’s fair to say that at Google and – but more importantly – across the community, machine learning cycles are going to be taking up an increasing fraction of what we’re looking to do.”
One thing that Google is focusing on its optimizing the hardware and software to manage workloads and power consumption dynamically across clusters of systems:
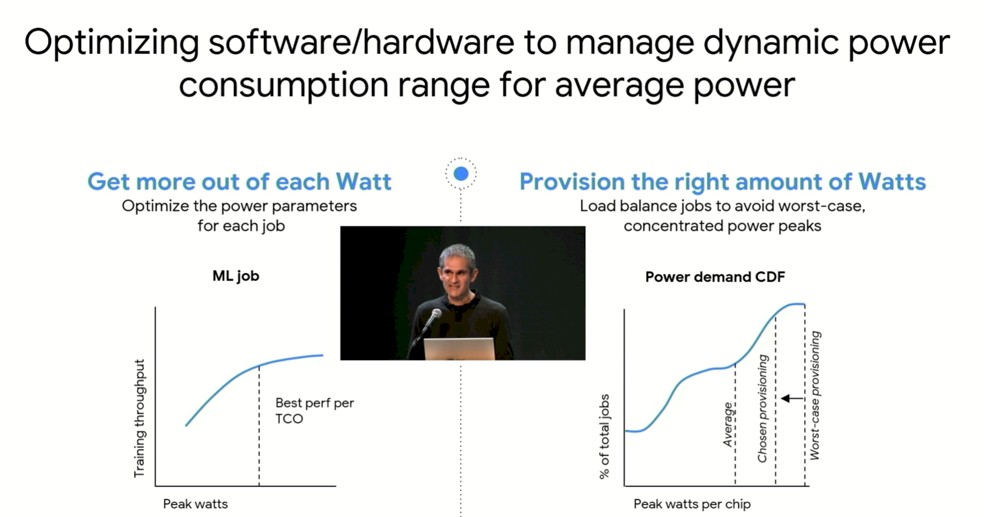
With memory bound jobs, voltage and amperage can vary wildly, and trying to manage power consumption across a cluster of thousands to tens of thousands of compute engines is, as Vahdat put it, “somewhere between hard and impossible.” By not creating massive hot spots in the cluster – which probably happened while Google was training the PaLM model – that increases the longevity of the devices and reduces outages, which are very disruptive on synchronous work like AI training, just like it is for HPC simulation and modeling. Rather than rollback to a checkpoint and start from there, it would be better to avoid the outage in the first place.
Here is how you play with core frequencies and voltages to balance things out a bit.
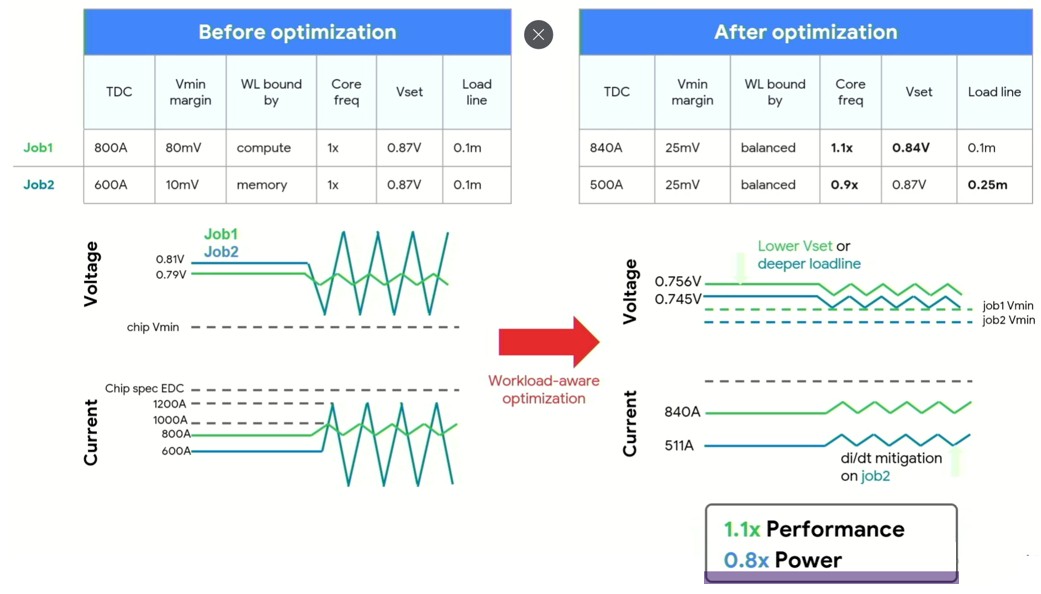
If Google is talking about this, then Borg probably has this for the TPU clusters at the very least. But maybe not. In any event, the idea is that there is a constant chatter between a control plane that looks at job placement on the cluster and power parameters for those jobs and placement and movement of those jobs as they run is an ongoing process. You don’t just play Tetris once to place jobs, as job schedulers like Borg and Omega inside of Google do, but you re-place them as needed as power constraints affect performance or performance constraints affect power.
Getting new TPU chips out the door faster is part of that, and Google has used its own AI-enhanced EDA tools to help design chunks of the TPUv4i and TPUv4 chips and presumably the TPUv5e as well. Right now, according to Dean, it takes about three years to get a chip out the door. That’s six to twelvemonths for design and exploration, a year to implement the design, six months to tape it out with a foundry, and twelve months to get it into production, test it, and ramp it. It is not clear how much AI can shorten the chip development cycle or how much it can reduce human effort, and Dean did not offer any estimates. But clearly, the closer you can get a hardware design to emerging AI models, the better.

With “Ironwood” TPU, Google Pushes The AI Accelerator To The Floor
If you want to be a leading in supplying AI models and AI applications, as well as AI infrastructure to run it, to the world, it is also helpful to have a business that needs a lot of AI that can underwrite the development of homegrown infrastructure that can be …
Oracle Runs OCI Clones At Rival AWS, Google, And Azure Clouds
It’s a multi-cloud world and one with a cloud infrastructure services market that is dominated by three large players. If you’re one of those cloud services providers that is not among the big three, how do you expand the reach of your own cloud offerings? Well, on strategy is that …

Google Cloud Revenues And Profits Flattening Out
Every business has its patterns, and so it is with Google and its hodgepodge of advertising and cloud computing. The funny bit is that even though Google is not an IT supplier that is constantly chasing transactional business – people buying stuff right now because they need it now – …
Great article, and good to hear about Peter Norvig (one of the great Lispers, along with Richard P. Gabriel, and R. Kent Dybvig)! SparseCores sure smells like tasty secret sauce to efficiently digest sparsity (real-time lowering of the data-access graph?), and one may also think of moving computations (closures) to the data in this Pathways framework (for extra balanced, dataflow-like, heartburn-proof, digestion?).
But, Geminy Pricket! Who’d have thought the many big MACs of Tensor-Matrix LLMs could be such a whopper!
Methinks that would rightly be a forlorn hope Google may decline to ever need to deliver themselves, Timothy, given the clearly unrivalled vital data and virtual metadata sector leads which you have so clearly reported on them having already achieved, and are being enjoyed and employed and deployed by such responsible Google fabless lab RATs as be accountable for emerged and converging Pathways and the very soon likely to be ubiquitous and new ground-breakingly-pioneering AI in the proprietary stylised framework [Google secret source sauce mix] of the Gemini LLM, for some things, and highly disruptive, addictively attractive, extremely rapid AI development with Large Language Modelling Machines is undoubtedly one of those things, are just like the finest of chef’s recipes and ingredients for the greatest of great tasty culinary dishes, and best preserved and protected from wannabe artisan abuse and misuse by secure reservation for exclusive AIMaster Pilot use, beautifully observed and passed comment upon by the cognoscenti from the comfort of the privileged access their curious meticulous interest would deservedly reward.
Such is the strange and surreal nature of the AI Singularity beast. 🙂 ….. which isn’t ever going away as it is here to forever stay and create more than was never ever before bargained for or even imagined as possible.
If Google Inc. and cohorts don’t say so …… We thank you for your service, it is greatly appreciated.
A beautiful (if cold at 11.C) relatively cloudless night (2:00am local time) here in northern France, with a great view of the full blue super Moon, Saturn nearby, to the right and slightly above it, and Jupiter about 70 degrees to the left (with Alderaban and Capella yet to rise) — all visible with the naked eye! The “angry red planet” is not in view but luckily amanfromMars is here to remind us of its likely existence …
Just a couple comments on slight nuances between Earth and Martian HPC gastronomy. Here, we tend to avoid “sauce mix[es]” like the plague because of their tendency to form lumps due to incomplete dissolution of dried hydrophobic flavor agents (oily or aromatic organics), except in MAC’n’cheese where it really doesn’t matter much. Also, the finest recipes are commonly crafted by artisans, and it is wannabe chefs who might abuse and misuse them (rather than the opposite Martian situation).
Apart from that, we’re in total interstellar AIgreement on addictively attractive Modelling lab RATs and the strange and surreal nature of the greatest of great tasty culinary dishes clearly unrivalled by the cognoscenti of the Gemini LLM (or not, as it remains somewhat secretly saucy, but hopefully not lumpy)!
Is it realised yet that AI and ITs Large Language Model Learning Machines are also perfectly able to be AWEsome Weapons of Mass Destruction against which humans have no possible effective defence or attack vectors ….. and they can be easily sold to just about everybody, but not necessarily bought by just anybody because of the horrendous self-harm that their wanton abuse and evil live misuse is both programmed and guaranteed to swiftly deliver mercilessly.
And yes, such is indeed an extremely valid existential threat which many would rightly be worthy of suffering because of past actions and/or future proposals.
Definitely — it is totally realised indeed. Most of us have read about AI going rogue (second-hand), and are witnessing a real-life, first-hand example of this fascinating phenomenon as we speak (albeit a possibly subtle one). When the machine outputs:
“[LLMs are] guaranteed to swiftly deliver mercilessly […] horrendous self-harm”
and follows it up with:
“which many would rightly be worthy of suffering”
we know exactly what to do … (or not?)
Wow yeah, Google having all the new data in the world is certainly needed to continue to feed what may soon be the Top AI platform.
It seems as though humans and chip manufacturing processes are a real drag on accelerating AI development. This all makes me feel small and insignificant. The ego dies.
Natural intelligence is hard (to aquire and exercise) but AI seems even harder. As huamns, we can hold verbal and written communications, move about, and even do calculus (when concentrated), all within approx. 20 Watts. The AIs seem to need at least 1 kW to get there, and much more for training. No shame in being human then!
On the HPC side on the other hand, a skilled abacus operator could beat ENIAC’s 300 ops per second, but it would take 10^15 such persons (approx. 60 Peta Watts) to match the 20 MW Frontier Exaflopper! In other words, the machines compute more efficiently than us, but they can’t hold conversations, move about, nor reason, nearly as well as we do (factor of at least 500x in our favor for these activities).
It is also notable that many of us are awestruck by AI answering rather simple questions of which we already know the answers. It is however not until it answers questions with unknown answers (eg. Millenium Prize Problems, Riemann or Poincaré conjecture, P vs NP problem, unsolved Hilbert (15), Landau (4), Smale (14), or Simon (10), problems) that we should see it as a proper contender for “intelligence” (of any kind).
The grand voodoo priest of the horror backpropagation plague (Y. LeCun) suggested from this that our current approach to AI is probably not that good (some fundamental understanding of reasoning is missing). Accelerators (eg. TPUv4/5, GPUs, dataflow wafers, analog in-memory machines …) can help a bit, but, long-term, the “holy grail” is probably elsewhere.