
Supercomputers are expensive, and getting increasingly so. Even if they are delivering impressive performance gains over the past decade, modern HPC workloads require an incredible amount of performance, and this is particularly true of any workload that is going to blend together traditional HPC simulation and modeling with some sort of machine learning training and inference. That is almost certainly going to require GPU acceleration, and GPUs are not cheap.
The days when supercomputer nodes were just homogeneous compute engines comprised of lots of CPU cores, the absolute minimum amount of DRAM main memory, and one or two network interface cards are gone. The situation has become a lot more complex, as different workloads require different ratios of CPU and accelerator compute and different mixes of network bandwidth and even fast access to flash storage. We are lucky, then, that PCI-Express fabrics based on the very fast 4.0 generation and soon on the even faster 5.0 generation, which will also support the CXL asymmetric coherence protocol created by Intel and now adopted by the entire IT industry, will be ready at just the time organizations need fast and wide PCI-Express networks to create composable collections of compute engines, storage, and network adapters.
As is the case with many technologies, HPC centers and other enterprises that run GPU-accelerated HPC and AI workloads, are taking a measured approach to adopting PCI-Express switch fabrics as a means to make their infrastructure more malleable and to drive better efficiencies. While this may be a little disappointing – we are always a little impatient for the future here at The Next Platform – it is not surprising given that people have decades of experience building distributed systems that are connected by Ethernet or InfiniBand switches and have very little experience podding up infrastructure using PCI-Express fabrics.
All good things take time.
During the SC21 supercomputer conference, we had a chat with Sumit Puri, co-founder and chief executive officer at Liqid, one of the several startups that is selling PCI-Express fabrics and composability software atop of it and arguably the one company that has gotten the most traction with this infrastructure disaggregation and composability idea that has been long in the making and that is as inevitable as taxes and a lot more fun than death.
We were talking with Puri about the very high cost of GPU and FPGA accelerators and how composable infrastructure like the Liqid Matrix software stack and now the two PCI-Express switching enclosures – one was launched during SC21, which we will get to in a minute – could possibly mean that a lot of modest-sized academic, government, and corporate supercomputing centers could forego InfiniBand or Ethernet entirely as the interconnect between their compute nodes. They could just use a PCI-Express fabric, which is faster, would be peer to peer across all devices linked to the hosts, and costs less than using traditional networks.
“Organizations like the National Science Foundation and Texas A&M University, which are building a composable supercomputer called ACES, are excited to be getting to a composable GPU environment,” Puri tells The Next Platform. “And we think that we are going to get them to leverage the PCI-Express fabric as the network, which is the next logical step. We are absolutely going to have those discussions, and the capability is there. This is just a discussion around architecture.”
Here is the funny bit of math here. Adding composability to any clustered system adds somewhere between 5 percent to 10 percent to the cost of the cluster, according to Puri, but we countered that at many organizations that might have only three or four racks of iron as their “supercomputer,” a PCI-Express 4.0 switched fabric can do the job, and with PCI-Express 5.0 switching, the bandwidth doubles and that means the radix can double, which could provide direct interconnect to somewhere between six racks and eight racks of gear. That is a sizeable system, particularly one that is accelerated by GPUs, and at the very least world represent a pretty hefty pod size even for capacity-class supercomputers that run lots of workloads.
To a certain extent, we think that capacity-class supercomputers – those that run lots of relatively small jobs all the time and in parallel – need composability even more than capability-class machines – those that run very big jobs across most of their infrastructure, more or less in a series. The diversity of workloads screams for composable accelerators – because different workloads will have different CPU to GPU ratios, and may even have a mix of CPU hosts and GPU and FPGA accelerators – and the very high expense of these CPUs and accelerators calls for their utilization to be driven up higher than is typical in the datacenter today. The average utilization of GPUs in most datacenters is shockingly low – anecdotal evidence and complaining from people we have talked to over the past several years suggests that in a lot of cases it is on the order of 10 percent to 20 percent. But with the pooling of GPUs on PCI-Express fabrics and sharing them in a dynamic fashion using software like Liqid Matrix, there is a chance to get that average utilization up to 60 percent or 70 percent – which is about as high as anyone can expect in a shared resource with somewhat unpredictable workloads.
“Here is the fundamental problem that HPC centers face,” Puri continues. “Different researchers bring different workloads to the machines and they have different hardware requirements. Under the old model, the orchestration engine asks the cluster for four servers with two GPUs apiece, and if the best that the cluster has is four servers with four GPUs apiece, half of the GPUs are not used. In the Liqid world, if SLURM asks for eleven servers with eleven GPUs a piece – and that is not a configuration that anyone in their right mind would ask for, but it illustrates the principle – within ten seconds Matrix composes those nodes, runs the job, and when it is done returns the GPUs to the pool for reuse.”
While that is neat and useful, coming back to using PCI-Express as the interconnect fabric, Puri confirms our hunch that this is easy and transparent. The way it works is that the PCI-Express fabric puts a driver on every server node that presents itself to the operating system and the applications as an InfiniBand connection, and the hosts underneath are just talking point to point with each other over the PCI-Express fabric. Importantly, the Message Passing Interface (MPI) message sharing protocol that most HPC applications make use of to scale out workloads runs atop this InfiniBand driver and is none the wiser, too. The point is, the incremental cost of composability can be paid for by getting rid of actual InfiniBand in pod-sized supercomputers measured on the order of racks. For systems with one or many rows, not so much, but there is probably a way to pod up racks and then interconnect them across rows to create a two-tiered InfiniBand network fabric. How useful this will be depends on the nature of the workload, of course. But other HPC interconnects do a similar kind of hierarchical architecture for the network, so it is not alien.
That brings us to the EX-4400 series enclosures from Liqid, which house PCI-Express switching and have room for either ten or twenty PCI-Express accelerators or storage devices. They look like this:

The devices inside the enclosures can be GPUs, FPGAs, DPUs, or custom ASICs – all they need to do is speak PCI-Express 4.0 and fit in the slots. The chassis has four ports to hook out to host systems and delivers 64 GB/sec of bi-directional bandwidth per port. The chassis has four 2,400 watt power supplies, two for the devices and two for backup. the EX-440 enclosures, which have Broadcom PLX PCI-Express switches embedded in them, are used to consolidate and virtualize connections to the accelerators in the enclosures.
In the simplest case, the PCI-Express fabric is used to link a lot of devices to a single host – more devices than would have been possible with a direct PCI-Express bus. In the case of one customer using GPU accelerated blockchain software, the customer needed 100 GPUs to run the blockchain workload, and by putting four GPUs in a server, that took 25 nodes. Using five EX-4420 enclosures, it only took five enclosures and five servers to yield that 100 GPUs, which took 20 servers out of the mix. And now the GPUs can be dynamically linked to each other and to the servers through the PCI-Express fabric whereas they were statically configured in the old way of doing it.
When you consider it costs roughly $1 per watt per year to pay for electricity on top of the cost of the servers themselves and the space they consume, being able to get rid of servers while retaining functionality and making the infrastructure more flexible is a triple win.
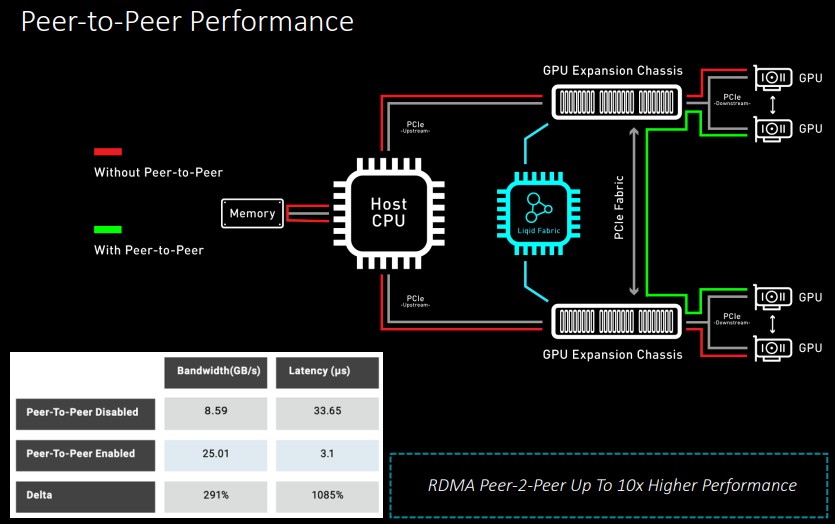
Perhaps the most important benefit, however, is the peer to peer nature of the PCI-Express fabric. “This is really what it is all about, this is the critical thing,” says Puri, “the ability of these devices to communicate without having to go back to the host processor. And when we do this for GPUs, for example, when we enable this datapath, the performance benefits are phenomenal. We see a 5X improvement in bandwidth and a 90 percent reduction in latency. This peer-to-peer communication is well understood with GPUs, but it will also work with other accelerators. And this is super important – it will allow GPUs and flash SSDs to communicate on that RDMA datapath.”
Liqid is working on benchmarks to show off this GPU-SSD link over the PCI-Express fabric, and the company is allowing customers to lash together up to four EX-4400 enclosures together to create larger peer-to-peer pools. They can be made even larger, in a ring, star, or mesh configurations. The hop between switches is only 80 nanoseconds for PCI-Express switches, so multitiered PCI-Express fabrics can be created to make ever-larger pools of devices. And with each generation, the radix of the PCI-Express switches doubles.
It would be interesting to see the two PCI-Express switch makers – Broadcom and Microchip – push this just a little bit harder. Then all hell could break loose in the datacenter … literally, and figuratively.
Liqid is adding a few customers a week and business is on the hockey stick upswing, according to Puri. Somewhere between 20 percent and 30 percent of the deals are driven by traditional HPC accounts, and these tend to be slightly larger deals and so the revenue contribution of HPC is a little bit larger. The remaining 70 percent to 80 percent of the deals that Liqid is doing come from disaggregating AI systems.


AMD Hits Intel Below The Belt In The Datacenter Wallet
What Intel calls “cloud digestion” as the cause of the massive pullback in spending in its Data Center Group is looking more and more like a case of “Epyc indigestion” for Intel, not for the hyperscalers and cloud builders. And the top brass at Intel should be thanking the heavens …

The Steady Hand Guiding AMD’s “Prudently Expanding” Datacenter Business
The old AMD – the one before Lisa Su took over – was often brilliant with its instruction set architecture and CPU designs, but sometimes perplexingly careless with its design choices and chip roadmaps. And so it had a bit of a boom-bust cycle in its epic battles with archrival …

Celestial AI Wants To Break The Memory Wall, Fuse HBM With DDR5
In 2024, there is no shortage of interconnects if you need to stitch tens, hundreds, thousands, or even tens of thousands of accelerators together. Nvidia has NVLink and InfiniBand. Google’s TPU pods talk to one another using optical circuit switches (OCS). AMD has its Infinity Fabric for die-to-die, chip-to-chip, and …
Be the first to comment