
Hardware is, by its very nature, physical and therefore, unlike software or virtual hardware and software routines encoded by FPGAs, it is the one thing that cannot be easily changed. The dream of composable systems, which we have discussed in the past, is something that has been swirling around in the heads of system architects for more than a decade, and we are without question getting closer to realizing the dream of making the components of systems and the clusters that are created from them programmable like software.
The hyperscalers, of course, have been on the bleeding edge of trying to make hardware composable and malleable. But the advent of fast PCI-Express switching and fast and affordable silicon photonics links between system components is going to smash the server to put it back together again. Cisco Systems was way out front with composable systems with its UCS M-Series, which it discontinued last year, and Hewlett Packard Enterprise is banking on its “Project Thunderbird” Synergy composable infrastructure to give it an edge in systems that it needs to revitalize its IT business and provide some differentiation. A3Cube came up with an extension to PCI-Express that allowed it to create a compute and storage fabric that was somewhat malleable, and PLX Technologies, now part of Broadcom, had some extensions as well. But with the CCIX and Gen z protocols and updated PCI-Express 4.0 and then 5.0 coming out, we should expect to see row-scale clusters of systems that are less rigid than the systems and clusters we are used to.
Just like converged server-storage hybrids came out of the woodwork, we expect to see a slew of composable systems vendors pop up like mushrooms, flush with venture capital and their own twists on this idea. This time last year, a startup called DriveScale, created a special network adapter that allows compute and storage to scale independently at the rack scale, akin to similar projects under way at Intel, Dell, the Scorpio alliance of Baidu, Alibaba, and Tencent, and the Open Compute Project spearheaded by Facebook. And now a company called Liqid – somebody please show the marketing department where the spellchecker is – is jumping into the fray.
Liqid dropped out of stealth mode recently after getting its Series A funding round of $10 million; the company was founded two years ago and had already raised $9.5 million in a seed round. Company co-founder and CEO Jay Breakstone managed the flash memory product lines at PNY Technologies and was CEO at flash device maker Pure Silicon before starting up Liqid with Scott Cannata, Sumit Puri, and Bryan Schramm. The Denver area, where Liqid hails from and where many of its founders are from, is a hotbed of storage technology, with many disk drive and storage array vendors hailing from the area. Cannata, who is chief architect at Liqid, was working on storage clusters with virtualization layers at Crosswalk over a decade ago, and followed that up with stints at Atrato, LineRate Systems, and Sanmina-SCI where he created low-level storage software. Puri had several high level engineering jobs at Iomega, Fujitsu, Toshiba, and LSI Logic and heads up marketing at Liqid.
Having suffered through the issues that arise when compute, networking, and storage are tightly defined by a server node, the Liqid founders decided to do something about it, and rather than develop a proprietary interconnect, they decided that, like some hyperscalers today, they would base their rack-scale architecture on PCI-Express switching. (For comparison, Intel’s Rack Scale Design uses a mix of Ethernet and PCI-Express as its fabrics, and HPE’s Synergy initially used 40 Gb/sec Ethernet at the switch and 20 Gb/sec Ethernet on the server with 16 Gb/sec Fibre Channel out to external storage; it is now moving up to 100 Gb/sec Ethernet at the switch and 25 Gb/sec at the server.) To make systems composable – meaning, you can grab chunks of compute, memory, flash and disk storage, and networking from a pool in a rack and create an arbitrary bare metal server without a virtual machine hypervisor – Liqid had to tweak the PCI-Express protocol to make a composable fabric and it also had to come up with a management console to keep track of the assemblages of bare metal machines, which is called Liqid Command Center.
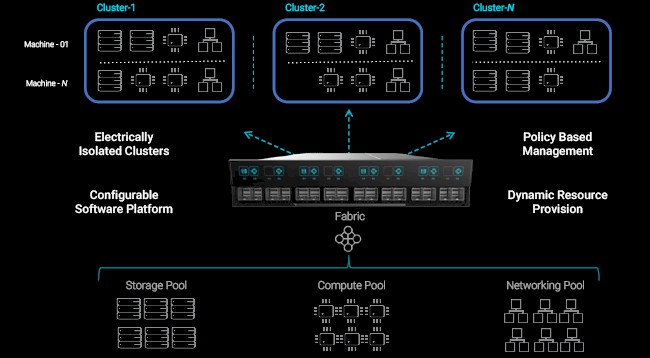
The fact that Intel has added PCI-Express as a fabric option with Rack Scale 2.1 a few months ago is significant, Puri tells The Next Platform, since it sets the stage for the rest of the industry. “This was an important move, since PCI-Express is that one common interconnect between all of these devices. The CPU has had PCI-Express coming in and out of the root complex for years, regardless of what you are using as your networking interface. Storage is now transitioning to native PCI-Express with NVM-Express, and now everything is on a common interconnect and there are latency benefits, too. That puts us in the lead for this PCI-Express style of composability.”
As it turns out, more than a few of the hyperscalers have their own PCI-Express top of rack switches, which they use for their own rack scale designs; generally, companies tend to use the PCI-Express switches from the former PLX Technologies, which is now part of Broadcom. PLX is also the dominant vendor of PCI-Express switches that are used to glue four, eight, or sixteen GPU accelerators to CPU complexes within single nodes. (Some designs use a mix of PCI-Express and NVLink to couple the compute elements together.)
Liqid has come up with its own PCI-Express top of racker, which uses multiple PLX chips and which also includes an Intel Xeon processor for local compute to do the manage the bare metal provisioning. The pools of compute are linked to this top of rack PCI-Express switch using HDMI cabling. Puri says that Liqid has been forced to build its own PCI-Express switch because one that fit the needs of its hardware composition software does not exist. Ironically, Liqid could have licensed a version of the homegrown hyperscale PCI-Express switches, which we suspect are used for flash and GPU clusters, but instead has made its own switch and is enthusiastic about porting its Liqid Command Center software to any and all PCI-Express switches that might come to market as the composable infrastructure market takes off. To the point, one hyperscaler has donated one of its PCI-Express switches to Liqid, and its software is running in the labs on that hyperscale TOR right now.

Liqid is, like the hyperscalers when they run their own internal workloads and outward-facing consumer applications, focused on bare metal implementations. (Those hyperscalers that do public clouds have a virtual machine layer on top of their clusters.) The reference design shown above was built in conjunction with Inspur. The Liqid PCI-Express switch is at the top, and there are two enclosures below that have a PCI-Express native backplane to link into the switch; one chassis has flash SSDs slotted in and the other has Ethernet cards slotted in. These are linked to the four two-socket Xeon server nodes through the PCI-Express switch, and the Liqid Command Center software carves up the cores and memory, the network bandwidth, and the storage into bare metal server slices of varying sizes as needed. The SSDs and network cards can be deployed to a virtual machine in units of one, which is about as granular as you can get without somehow virtualizing the devices.
The idea is that policies, rather than system administrators, will control how bare metal server slices are configured and change over time. So, for instance, companies could set a policy that when storage capacity or I/O operations per second reach 80 percent of their peak in the instance, then automagically add more storage to the instance. Ditto for network bandwidth. At the moment, memory and CPU capacity are tightly coupled on the motherboard, but hopefully that link will be broken soon and compute and memory will be pooled separately. The advent of 3D XPoint memory, which is persistent like flash but fast like and addressable like main memory, will help blur some of the lines here some. At some point, actual DRAM may be used more like Level 0 cache, we think.
We are always interested in scale here at The Next Platform, and Liqid has to scale to see widespread deployments. We have been enthusiastic about the possibilities of PCI-Express switching but the signaling has to be done over fairly short distances, with spans of maybe two or three racks if you want to stick to copper wires. But those limitations are going away with the advent of cheaper optical transceivers, says Breakstone, and early adopter customers of Liqid’s switches are using these optics already in the field trials.
“This is less about datacenter-to-datacenter connections and more about connections within the datacenter,” says Breakstone. “We have scenarios where customers are running across adjacent racks, and some others that are linking from one side of the datacenter to another. But we view this as something to keep within the aisle because we are using mini SAS cables, we have the ability to run active copper and passive copper and optical transceivers just as you would with traditional networking. As for signal loss over distance, we pretty much gave that covered at this point, and the beautiful thing about the latest PLX switches, they have a ton of capability that will allow for being able to handle errors over longer distances. The historical PCI-Express switches that you have seen in the past were not able to do this.”
The Liqid software can cluster up to 1,000 switches together into a single management domain, and this is a software limit in the initial release of the Liqid Command Center. All of the state information and location of all of the devices in such a cluster are stored in the distributed controller. The architecture supports many different topologies, but as an example, a large telecommunications company that is testing the Liqid switches and software has a cluster with 160 GPUs, 96 flash SSDs, and 48 25 Gb/sec Ethernet ports all running in a mesh topology, and they are pulling 32 GB/sec of bandwidth out of each compute node. Breakstone says that they can daisy chain the PCI-Express links on top of the mesh topology to create larger networks, and because it has a non-blocking architecture, the topologies that are familiar in traditional Ethernet and InfiniBand networking can also be used.
Each Liqid switch has limits of its own, imposed by the 255 device limit of the PCI-Express bus, which is why they have to be clustered. Suffice it to say, each Liqid TOR can handle hundreds of devices. By the way, Liqid can put two 24-port switches, with each lane supporting PCI-Express 3.0 x4 slots, in a 1U form factor.
Liqid is not releasing pricing on its PCI-Express switch, but says it will cost around the same as a comparable high performance Ethernet or InfiniBand switch plus the value gained from the composability. Liqid does not intend to sell these individually, Breakstone says. The idea is to partner with ODMs and OEMs to create rack scale setups and truck them into datacenter en masse. The idea is also to justify the cost of the Liqid software by the increased utilization of the assets under management, potentially lowering capital expenses, and the increased flexibility and automation of the management of those assets, absolutely lowering operational expenses. Breakstone says that the average utilization of datacenter assets is somewhere around 10 percent to 15 percent, and that the best in breed hyperscalers like Google see something like 30 percent utilization. Companies using Liqid are seeing 90 percent utilization.
These kinds of numbers are surely going to get some attention.
The Liqid PCI-Express switch and Command Center software is in beta testing now and will be generally available before the end of the year.

Ethernet Consortium Shoots For 1 Million Node Clusters That Beat InfiniBand
Here we go again. Some big hyperscalers and cloud builders and their ASIC and switch suppliers are unhappy about Ethernet, and rather than wait for the IEEE to address issues, they are taking matters in their own hands to create what will ultimately become an IEEE standard that moves Ethernet …
The Resurrection Of Cray And AMD In A Trifurcating HPC Space
Success in any endeavor is not just about having the right idea, but having that idea at the right time and then executing well against that plan. It is safe to say that in the traditional HPC simulation and modeling arena, the combination of the “Shasta” Cray EX supercomputer line, …

For CPU Makers and OEMs Alike, It’s A Platform View
Dell took a look at the two weeks between the rollouts by AMD and Intel of their latest server processors and, after some debate, decided to unveil its entire portfolio of new and enhanced systems – featuring the new chips from both vendors – at the launch of AMD’s latest …
1 Trackback / Pingback