

There is a growing number of vendors big and small going hard to the hoop to make processors for artificial intelligence workloads. AI and machine learning are key enablers of automation and analytics that play an increasingly crucial role in a highly distributed IT environment that spans on-premises datacenters, public and private clouds and the growing edge space.
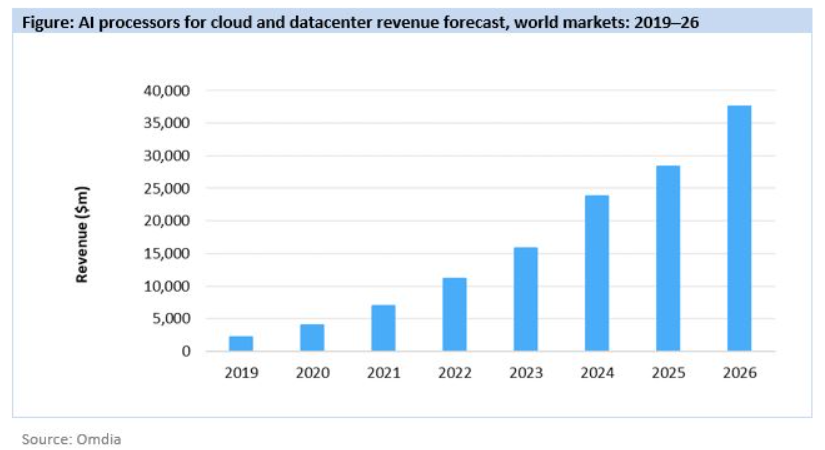
The market for AI chips continues to be dominated by the large established players. In a report last month, market research firm Omdia said Nvidia, which several years ago made machine learning central to its growth plans, continued to be the top vendor in 2020, holding an 80.6 percent share of the $4 billion in global revenue generated, with $3.2 billion. Omdia expects worldwide revenue for AI chips in datacenters and the cloud will hit $37.6 billion in 2026.
Such market grow is sure to attract chip makers. Intel in 2019 bought AI chip maker Habana Labs for $2 billion, looking to accelerate its efforts despite having bought Nervana Systems three years earlier. In April the San Diego Supercomputer Center said it was planning to install almost ten racks of Habana-based systems in its datacenter.
Others also have continued to build AI processors or infused their chips with AI features, including Google with its Tensor Processor Unit (TPU), AMD, IBM, Xilinx with its Edge AI Platform and Amazon and its AWS Inferentia AI inference chip for machine learning.
That said, there’s a growing number of smaller and startup chip makers that are looking to carve out a space for themselves in the market, focusing on areas ranging from performance to cost efficiency to flexibility. Some of the names are more familiar than others and include Graphcore, Ampere, Blaize, Cerebras, Groq, and SambaNova.
Count Esperanto Technologies in that list. The company was founded in 2014 and since then has collected $124 million through three rounds of funding, the last being $61 million in April. Esperanto in December 2020 announced the ET-SoC-1, a seven-nanometer machine learning processor based on the open RISC-V architecture. The chip maker said the chip would hold almost 1,100 custom cores in a small package, with the focus on driving performance by leveraging energy efficiency.
At the recent Hot Chips 33 virtual event, Esperanto founder and Executive Chairman Dave Ditzel unveiled details of what he called a supercomputer-on-a-chip that can be used either as a primary processor or an accelerator and is designed to fit into existing datacenters that demand power effiency in air-cooled environments.
The chip, which holds 24 billion transistors and is fabricated by Taiwan Semiconductor Manufacturing Corp., is designed primarily for machine learning inference workloads.
“Machine learning recommendation workloads in hyperscale datacenters have some of the most demanding performance and memory requirements,” Ditzel said in his presentation. “They have been largely run on x86 servers. Demand for additional performance is growing rapidly and rather than simply building more datacenters and buying more servers, customers would like a way to increase the performance for inference on servers they already have installed.”
These systems typically have a slot for a PCIe card that have power budgets of between 75 and 120 watts. Ditzel said that requirement essentially set the parameters for Esperanto’s machine learning chip. The company needed to build a PCI3-based accelerator card that used up to six of the vendor’s chips and no more than 120 watts.
After that, the performance of the card needed to be “substantially higher than the performance of the x86 host CPU,” with computation rates of 100 to 1,000 TOPS, he said. In addition, while a lot of inference can be done with an 8-bit integer, the card also had to be able to support 16- and 32-bit floating point data types. It also should have at least 100GB of storage and 100MB of on-die memory.
“Computation mixed with very large, sparsely accessed data is challenging because the latencies to off-chip memory are very large, which may cause processing to stall,” Ditzel said. “Finally, because of machine learning workloads evolving rapidly, fixed-function hardware can quickly become obsolete, so the use of more general-purpose, programable solutions is highly recommended.”
What Esperanto developed is a chip that includes 1,088 of its power-efficient ET-Minion in-order cores, each of which sports a vector tensor unit, and four ET-Maxion out-of-order cores. The ET-SoC-1 providers more than 160 million bytes of on-chip SRAM, interfaces for large external memory with low-power LPDDR4x DRAM and eMMC Flash and compatibility with PCIe x8 Gen4 and other I/O interfaces.
Most important, the chip can drive peak rates of 100 to 200 TOPS and operate at less than 20 watts, which means six of the chips would come in under the 120-watt power budget. This comes from the route Esperanto took in the design of the chip, Ditzel said.
“Some of the other solutions use one giant hot chip that uses up the entire power budget of the accelerator card,” he said. “Esperanto’s approach is to use multiple low-power chips that still fit within the power budget. There are a limited number of pins that one can practically put on a single chip package, so one-chip solutions cannot go wide to get memory bandwidth and often end up with expensive memory solutions. Esperanto’s approach distributes to processing and I/O across multiple chips. As more chips are added, performance increases, memory capacity increases, memory bandwidth increases and low-power and low-cost DRAM solutions become a practical solution.”
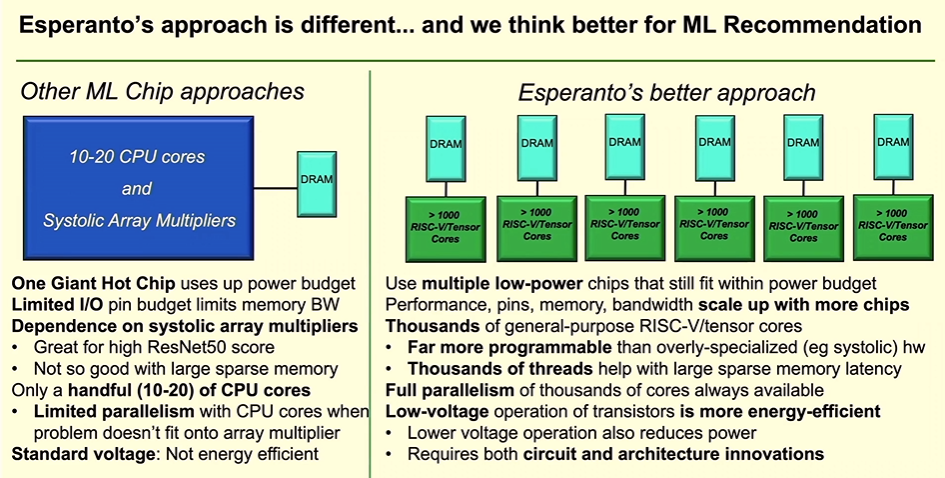
Single-chip solutions also tend to push for highest operating frequencies that lead to high power and low efficiency. Esperanto decided that transistors — particularly 7nm FinFETs — are more power-efficient when operating at low voltages, which reduces operating power. Esperanto engineers had to innovate around circuits and modify the RISC-V core to create a high-performance accelerator with no more than six chips and using no more than 120 watts, Ditzel said.
They turned down the close to reduce the operating frequency to 1GHz. They also could cut the operating voltage by at least a factor of two, but robust operations at low voltage s difficult.
“We had to make a number of circuit and architecture changes,” he said. “Operating at gigahertz levels and low voltage required designing with a very small number of gates per pipeline stage. … Esperanto had to make both circuit and architecture changes for L1 caches and register files. Even with these changes, there is still a gap of over 50x, and the only way to make up this difference is to reduce that dynamic switching capacitance, dynamic switching capacities, the capacity for each transistor and wire and how frequently those switch. To reduce those, you must have a very simple architecture with very few logic gates. This is where RISC-V was a great solution for base instruction set as it can be implemented with the fewest logic gates of any commercially viable instruction set. We also had to design our vector tensor unit very carefully.”
Ditzel showed the graph illustrating the power efficiency of the Esperanto chip, measuring inferences-per-second-per-wat at different operating voltages.
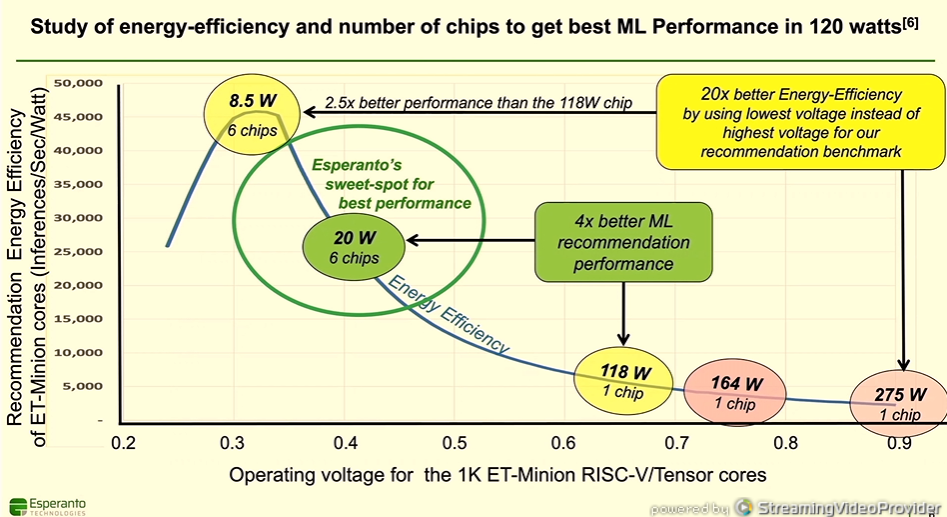
With the ET-Minion Tensor cores operating at the lowest voltage and at 8.5 watts, Esperanto was able to fit six chips into the accelerator card at well below the 120-watt limit, driving 2.5 times better performance than a single 118-watt chip solution and 20 times better power efficiency than 275-watt point.
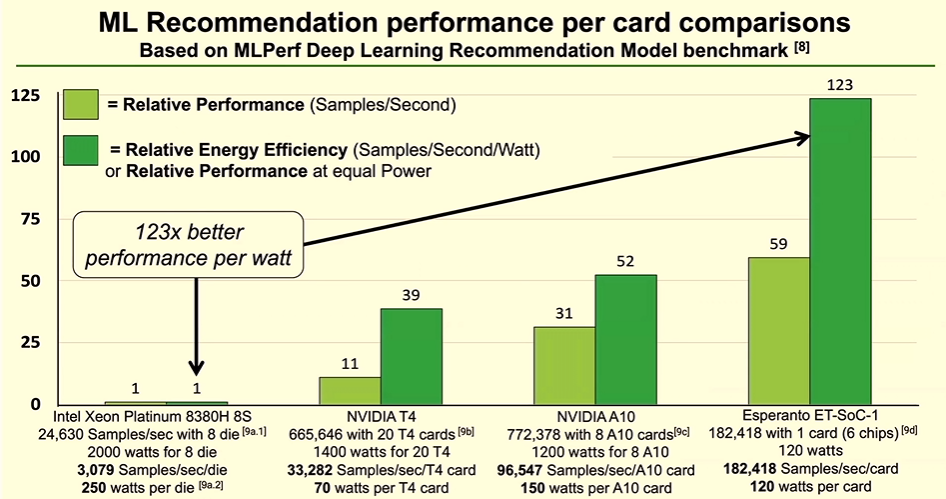
Ditzel also showed performance comparisons. For benchmarking, Esperanto used the MLPerf deep learning recommendation model, pitting the chip against Intel’s eight-socket Xeon Platinum 8380H server processor and Nvidia’s A10 and T4 GPUs. As seen below, Esperanto’s chip delivered 59 times the performance of the Intel processor and 123 times the performance-per-watt and out-performed the two Nvidia GPUs, he said. Similar results came from using the ResNet-50 inference benchmark, according to Ditzel.
In physical design, Esperanto groups eight ET-Minion cores, called a Neighborhood, which enabled the company to save power through architectural improvements, such as enabling the eight cores to share a single large instruction cache rather than each having their own. Each eight-core Neighborhood form a 32-core Minion Shire, which are connected via an on-chip mesh interconnect on each Shire.
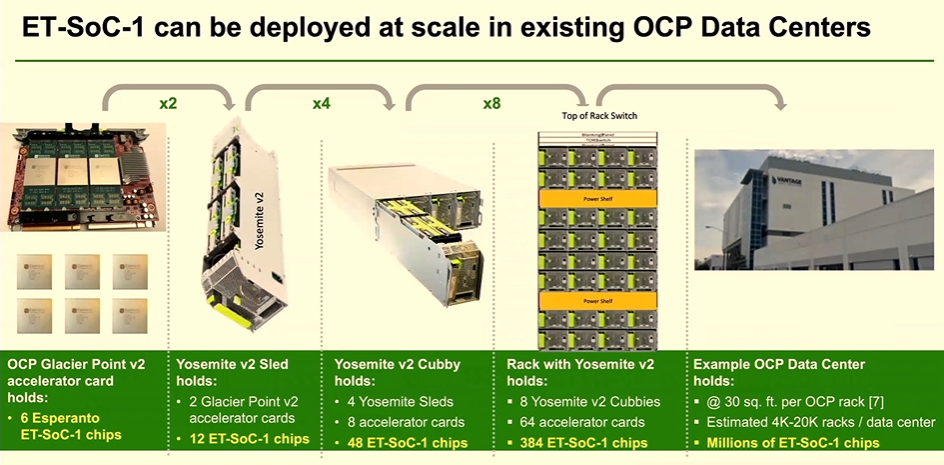
Ditzel spoke about how the ET-SoC-1 can be used in systems, including those supporting the Open Compute Project’s (OCP) Glacier Point V2 designs, with a card offering 6,558 RISC-V cores, up to 192GB of RAM and up to 822GB/sec of DRAM bandwidth. Extrapolating that out over sleds and racks, Ditzel said an OCP datacenter could hold millions of Esperanto cores.
The company supports C++ and PyTorch and such machine learning frameworks as Caffe2 and MXNet. Ditzel said Esperanto had recently received silicon in its labs and its readying testing. An early access program is scheduled for later this year.

Maybe Nvidia Should Buy VMware Instead Of Intel
It is hard to imagine how anyone could run Nvidia better than it is being run right now. Even if the $40 billion acquisition of Arm Holdings falls apart because of regulatory concerns, nothing about Nvidia’s current strategy has to change for it to become even more of a powerhouse …
AMD Is Beating Nvidia At Its 2017 Game, But The Game Has Moved On
Hold on a second. Nvidia’s sales of chips and systems to supercomputer centers are not as big as we might be thinking. Not even close. Nvidia may have pioneered the idea of GPU acceleration for HPC simulation and modeling applications. It may have supplied the vast majority of the compute …

HPC In 2020: AI Is No Longer An Experiment
If we could sum up the near-term future of high performance computing in a single phrase, it would be more of the same and then some. Although no “revolution” is in the horizon, the four major trends of the past decade – the expansion of artificial intelligence technology, processor diversification, …
They certainly chose a strange namesake… An idealistic, carefully constructed language that lost out to an already-existing, organically-arising alternative.
Also, how can the chip be composed of only 24 million transistors yet contain 160 MB of SRAM? I assume it’s supposed to be 24 billion transistors?
Ah yup, that should be 24 billion. It’s fixed, thanks.
Apart from Dave Ditzel, any other staff over from Transmeta (his previous gig)?