
Argonne National Laboratory has become a must-watch lab for those following the convergence of supercomputing and AI/ML. The lab has a number of systems from AI chip upstarts, including Cerebras (CS-1 system), a Graphcore machine, and a SambaNova appliance. The list will be extended with Groq hardware coming online soon, along with other devices over the course of the next year or two.
One of the goals of Argonne’s stretch across the AI startup ecosystem is to understand where more general purpose GPU-accelerated HPC might be better served by more AI-specific hardware—not to mention how these systems mesh with Argonne’s existing fleet of supercomputers.
Among the applications the lab’s teams are evaluating for AI/HPC double-duty are simulations and neural networks for cancer and Covid research in addition to large-scale cosmology simulations. In most published cases, the neural networks are augmenting or serving as surrogate modeling techniques for some of the most compute/data-intensive (expensive) parts of traditional scientific computing workflows.
If there is one thread that runs between many of the experimental AI/HPC workloads happening at Argonne on the SambaNova system now, it’s handling noisy data.
This is particularly the case in cosmology simulations, but other work, which we’ll get to into a moment, has the same problem, often on a grand scale in terms of data volume. While that denoising might sound like a small problem, in HPC terms, it’s an expensive one in terms of compute time/costs. Since it’s not part of a simulation’s outcome per se, it’s a way for AI/ML to enter into scientific workflows in way that adds efficiency and speeds time to result without mucking up the decades of work in code development for vast HPC simulations.
Prasanna Balaprakash, computer scientist at Argonne National Lab says that when it comes to “noisy” projects with this surrogate-level role in larger HPC applications, the SambaNova system has performed well with some clear advantages over GPUs in terms of data movement and avoiding context switching.
“Lots of data from the memory has to go into the cores for convolutional operations and then the context switching happens, results are stored in memory and data and weights are then moved back so pooling can happen,” Balaprakash explains. “SambaNova addresses these two issues via their DataFlow execution mechanism. The data from memory enters into the PMU (memory) and the PCU (compute) units. The convolutions are pooling are mapped onto these and the data flows from convolution to pooling without going back into main memory.”
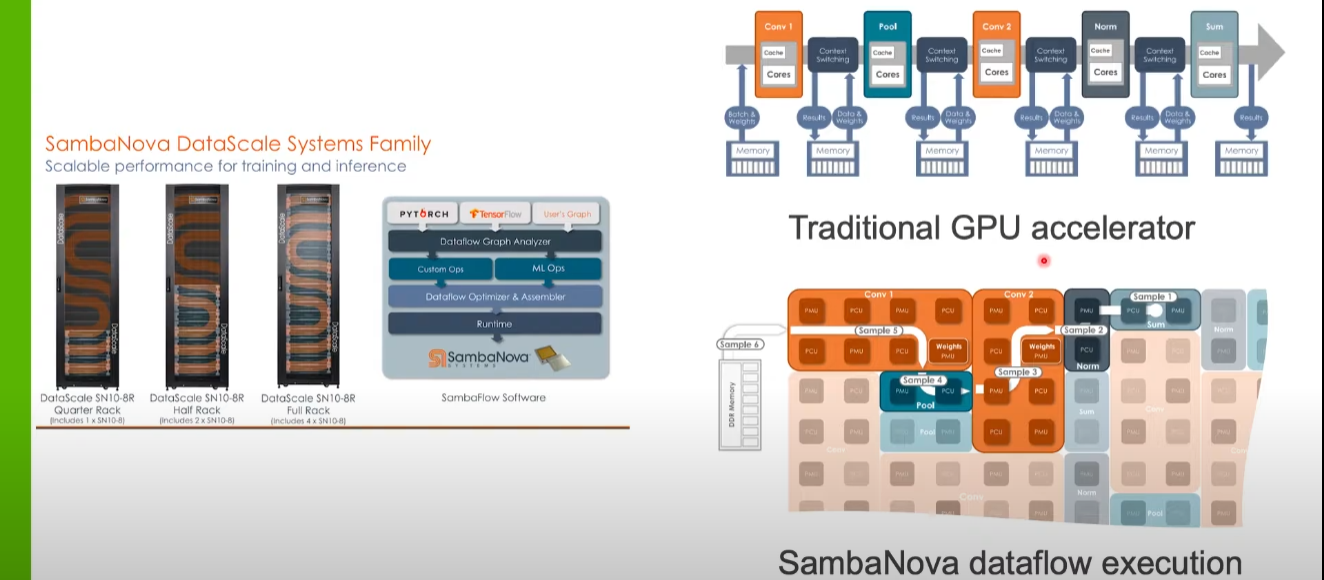
“By the time we’ve moved into the second convolution, the other data sample required for the first one can be pipelined and staged and operating at the convolution one layer. That means there’s no data movement from the PMUs to the PCUs to main memory and context switching doesn’t need to happen as much as it would with a GPU.”
Balaprakash walked through a few applications to show where and how a custom AI acceleration system is being used in broader HPC workflows, beginning with gravitational lensing, which for the sake of brevity, is a phenomena in which light from a dense object (which could be another galaxy) detected by telescope bends around the object, creating a lensing effect.
For this, Argonne created a set of modules that included denoising, deblending (removing that object in front of the source) as well as a detection module to see if the object is noise or an actual galaxy with a regression module to get to the heart of what those lensed images show. The modularity means they can take slices as needed for different images and while it wasn’t trained end-to-end, it does allow Argonne to use more efficient segments of compute/memory for expensive denoising, deblending, and identification that can feed back into the larger simulations.
Another example of work using the SambaNova machine cuts through the noise of scientific data in a different domain. Scientists use beams of particles to scatter a nucleus to help understand those properties, something that changes with each element. This is an incredibly noise problem in itself, as is the inversion process to make the results useful. For this work, Argonne does have an end-to-end approach
“Doing inversion traditionally with simulations is very expensive, which is why we are interested in developing a surrogate model for this problem. We’ve developed a neural network methodology (based on a mix of gaussians) then apply that to the inversion. We take the network and leverage the mixed workload training mode of the SambaNova system and map the architecture to the SambaNova hardware. The data comes in, parts of the PMU and PCU are allocated and there is no context switching or data movement as we move from one module to another, there is no going back to main memory.”
Another area of interest for Balaprakash is doing forecasting across very large graphs, which would have to be heavily segmented to fit onto GPU memory.
One such experiment is using a non-segmented graph of the entire traffic system of the state of California to predict hourly flow of traffic. While the outcome of that work is not yet complete, it is noteworthy that Argonne is taking the few things the GPU might have problems with and testing it across different optimized AI hardware to gauge the difference.
These are still early days for custom AI hardware, and even earlier still for their era alongside traditional supercomputers. While denoising isn’t the most compelling showcase of AI systems talent, it’s a good start in that neural networks can prove their mettle in production settings on optimized hardware that shows it too can play well with large-scale systems and software.


Expanding The Search For A Range Of New Materials
Finding new functional materials for batteries and catalysts and lots of other uses is a major goal of researchers around the world. And the design and discovery of new materials often requires computer simulations running on the world’s fastest supercomputers using specialized software that can determine properties at the quantum …
HPE GreenLake: The HPC Cloud That Comes To You
Sponsored By its very nature, high performance computing is an expensive proposition compared to other kinds of computing. Scale and speed cost money, and that is never going to change. But that doesn’t mean that you have to pay for HPC all at once, or even own it at all. …

Software Has To Lead Hardware In The AI Dance
A lot of the people who are working at the many AI chip startups have a long history in processor development in the datacenter, and that is certainly true of the folks who founded SambaNova Systems. And this is a fortunate thing because these people can leverage some of the …
Be the first to comment