
Machine learning inference models have been running on X86 server processors from the very beginning of the latest – and by far the most successful – AI revolution, and the techies that know both hardware and software down to the minutest detail at the hyperscalers, cloud builders, and semiconductor manufacturers have been able to tune the software, jack the hardware, and retune for more than a decade.
The Arm architecture, which is a relative newbie in the datacenter, has some pretty impressive chippery coming out of Ampere Computing, Amazon Web Services, Fujitsu, and a few others on the way, but the same amount of tuning for inference has not been done, and with very different instruction sets and chip architectures, this takes time. Or, some very talented software engineers who already know how to do it.
Lucky for Ampere Computing, it partnered with just such a set of talented software engineers from a startup called OnSpecta, and it liked the company’s AI inference engine so much that it just bought the company – for an amount of cash that has not been disclosed, as is typically the case when companies acquire startups.
Ampere Computing is the current best bet one can make for an independent vendor of Arm-based server CPUs, albeit they are only aimed at hyperscale and cloud builder workloads. The company has very tight partnerships with Oracle, Microsoft, Baidu, and Tencent, who are in various stages of deployment with the company’s Altra and AltraMax processors, which we profiled here, and a roadmap with an annual cadence of feature additions and performance expansion, which these upper echelon customers require. For the company to capitalize on the substantial investment that The Carlyle Group poured into Ampere Computing to acquire the assets and some of the team of the former Applied Micro, one of the real innovators in Arm server chips that didn’t get to escape velocity because, frankly, it didn’t have enough money to do the job.
In late 2018, Oracle said in filings with the US Securities and Exchange Commission that it paid $40 million to Ampere Computing to get a less than 20 percent stake in the chip designer bought a 20 percent stake in Ampere Computing for $40 million, which means probably means the company has raised about $180 million from other sources, the bulk of which came from The Carlyle Group. The private equity firm that controls Ampere Computing has not disclosed its funding, so no one is sure. Ampere Computing has more than 500 employees and is well on its way to unicorn status; we shall see how much money it can make selling chips.
That is what the acquisition of OnSpecta is all about, Jeff Wittich, chief product officer at Ampere Computing, tells The Next Platform. “We were already working with OnSpecta, and this acquisition will allow us to focus more on the intrinsic hardware piece while at the same time allowing us more flexibility with machine learning. At the end of the day, we are looking to sell CPUs and the software they have developed just makes our CPU performance leadership class in the inference space. I want to sell CPUs, and this will help us do it.”
When poked, Wittich admitted that Ampere Computing was not necessarily interested in selling the OnSpecta software stack to competitors, but the company will honor its agreements and said further that the software works on X86 CPUs as well as for accelerating the inference performance of hybrid CPU-GPU machines, too. On X86 machines, the speedup of the OnSpecta Deep Learning Software (DLS) inference engine is around a factor of 2X, and on the Ampere Computing Altra and AltraMax CPUs the speedup is around 4X, according to Wittich, and specifically he is comparing a 28-core “Cascade Lake” Xeon SP processor with the DLBoost mixed precision enhancements for the AVX512 vector engines to the an 80-core Altra processor with much more modest math units, but a lot more of them. Wittich adds that with the OnSpecta DLS stack tuning the inference, an Altra can outperform an Nvidia T4 GPU accelerator by about 4X on inference work.
OnSpecta was founded in 2017, and has about a dozen employees, according to Wittich. It had a seed round of funding in 2019 and two convertible notes (a kind of debt that can be converted to stock), one each in May 2019 and January 2020, from WestWave Capital. The amount of this funding has not been disclosed. The company has two founders, and both are serial entrepreneurs. The first Victor Jakubiuk, the company’s chief technology officer, who got his bachelor’s and master’s degrees in computer science from MIT and then worked at its Computer Science and Artificial Intelligence Laboratory, eventually bringing out a startup called DataNitro, which created an accelerator for Microsoft Excel in Python, through the YCombinator incubator. Jakubiuk was also co-founder and CTO at Contact.ly, a company that integrates enterprise-grade customer relationship management systems with social networks.
The other co-founder is OnSpecta’s chief executive officer, Indra Mohan, who got his bachelor’s in technology from the Indian Institute of Technology and an MBA from Harvard and then did nearly a decade selling digital trading systems at Teknekron Systems, which was acquired by Reuters. After that, Mohan had a string of companies, which were sold off, one of the biggies was Interweave, founded back in the dot-com era, which did web-based querying and reporting and which he sold to Cognos (now part of IBM).
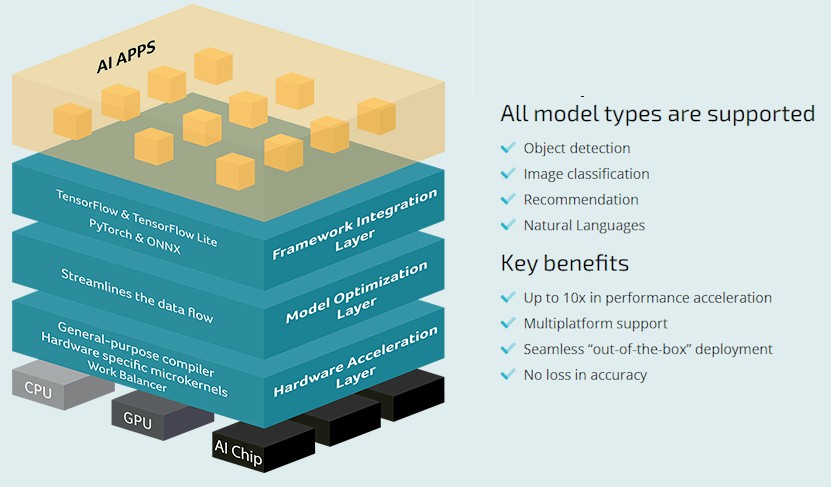
The DLS software stack has three layers. Working from the top down, the framework integration layer presents a consistent and optimized view up to the machine learning frameworks; the current ones supported are TensorFlow, PyTorch, and ONNX, which covers a lot of bases, but others will be added in the future according to Wittich. In the next layer down in the DLS stack from OnSpectra, optimizations are done at the neural network layer, and depending on the workload – say image recognition or a recommendation engine – it organizes the data in such a way that it can talk up to the frameworks and down to the iron in exactly the right manner to make the full use of the hardware’s compute elements, caches, and memories. The hardware acceleration layer is a mix of microkernals and a compiler that actually speaks the instruction set of the CPU, GPU, or custom ASIC supporting inference, and it optimizes the inference model code coming into the compute engine to drive the performance higher than it might otherwise be.
A lot of this kind of tuning is done by hand at hyperscalers and cloud builders and AI researchers, and the whole idea of OnSpecta is that it this is done seamlessly and automagically for those who are not necessarily wanting to get down into machine code to drive performance. This is for everyone else, and if the performance is good enough with DLS, then they won’t have to worry about doing it by hand on a new Arm architecture – which is an important point and which is why Ampere Computing is just buying the company. It can’t afford to wait.
We also think that everything that was just said about inference can eventually be applied to machine learning training or even traditional simulation and modeling workloads, in CPU-only setups or in hybrid setups with a mix of CPUs and accelerators of one kind or another. Wittich conceded this in theory, but was not able to talk about the company’s specific plans in these areas. What he did admit is that the OnSpecta stack makes the job of porting inference codes from X86 CPUs and Nvidia GPUs a whole lot easier, which is why it has been available on the A1 instances on the Oracle Cloud for some time now.


Ampere Aims For The Clouds With Altra Arm Server Chip
At this point in the history of information technology, there is no way to introduce a new processor that does not appeal to the hyperscalers and cloud builders. But it is another thing entirely to design a chip aimed only at these customers. And that is precisely what Ampere Computing, …

The Year Ahead In Datacenter Compute
For more than a decade, the pace of the server market was set by the rollout of Intel’s Xeon processors each year. To be sure, Intel did not always roll out new chips like clockwork, on a predictable and more or less annual cadence as the big datacenter operators like. …
The Looming Arm Server Battle Between AWS And Microsoft
Wouldn’t it be funny if Google ends up being the stalwart supporter of the X86 architecture among the hyperscalers and cloud builders? Amazon Web Services has been pushing its Graviton line for the past several years, and has had Graviton2 in production since March last year and is still previewing …
Be the first to comment