

There is nothing at all wrong with legacy application and system software as long as it can deliver scalability, reliability, and performance. Changing from one software stack to another is so difficult and so risky — the proverbial changing of the front two tires on the car while going down the highway at 75 miles per hour — that it just is not done unless it is absolutely necessary.
That is why you still see mainframes at the heart of financial services and insurance companies. That is why you still see third-party applications (mostly SAP, Oracle, and Infor) running on Unix servers from IBM, Hewlett Packard Enterprise, and even the former Sun Microsystems — these are mostly the core enterprise resource management, supply chain management, and customer relationship management applications at the top five thousand or so enterprises on Earth. And it is why you still see the Hadoop data storage and analytics stack lurking deep within the datacenters of the largest of the second wave of Internet startups, including LinkedIn, Facebook, and many others where interaction between users is the product. While making Hadoop scale as these services grew was difficult, it was not as difficult — history bears this out — as it would have been to find or build a better alternative. Such moves rarely bear the scrutiny of an honest cost/benefit analysis.
So it is with LinkedIn, the corporate social network provider that most of us use in some fashion in our work life to connect to colleagues. The company was an early and enthusiastic supporter of the Hadoop and Hadoop Distributed File System (HDFS) clones of Google’s ground-breaking MapReduce computational framework and Google File System (GFS), all of which we have written about in depth over the years. While the bloom may be off the Hadoop and HDFS roses to a certain extent, with other methods available for storing and processing vast amounts of unstructured and semi-structured data, the inertia of legacy forces the bigger users of any software stack to extend and expand what they have rather than exterminate what they are using.
This is why LinkedIn, which was acquired by Microsoft in July 2016 for $26.2 billion, has been largely left alone by its parent company from an infrastructure perspective and has been allowed to continue to invest in datacenters and systems to support. The company started moving its infrastructure from on-premises datacenters to Microsoft’s Azure cloud a few years ago, but that does not mean it will be dropping its homegrown Hadoop stack and replacing it with the Cosmos DB NoSQL datastore any time soon. (Microsoft took the better part of a decade to get its own manufacturing operations off of IBM’s proprietary AS/400 systems; Dell took almost as long to get its manufacturing operations off of Tandem database clusters after Compaq bought Tandem.) But we do think such a move is as inevitable as it is slow. Still, the ways that LinkedIn has been able to scale Hadoop are interesting in their own right, and provide a basis for understanding how to scale similar infrastructure.
In recent months, LinkedIn Engineering, the software engineering division of the company, has been lifting the veil a bit on its massive operations, which support 765 million users in 200 countries worldwide and drive $10 billion a year in revenues for Microsoft. (Given this, that crazy price tag for LinkedIn looks less ridiculous.) The Hadoop platform at LinkedIn stores everything that makes the LinkedIn professional network … well … work, and stores all of the data that comprises a knowledge graph that spans all members of the network in HDFS. Analytics are also run on this data to figure out relationships between people and companies and the applicability for job positions. (There is even a service on LinkedIn that can predict when your employees are getting ready to change jobs so you can help prevent that.)
Back in May, Konstantin Shvachko — a senior staff software engineer at LinkedIn who, among other things, was the principal software engineer for the Hadoop platform at its creator, Yahoo, during the five years it was being created, open sourced, and improved, and then was the principal Hadoop architect at eBay for a couple of years — did a blog post about the how LinkedIn had joined “the exabyte club,” with over an exabyte of storage across all of its Hadoop clusters. (We don’t know how many there are, but it is very likely dozens.) The largest Hadoop cluster at LinkedIn — which is probably the largest one in the world, certainly at a commercial entity if not a security agency for a major nation — has 10,000 nodes and weighed in at 500PB of storage capacity in 2020. The single HDFS NameNode for this monster can serve remote procedure calls with an average latency of under ten milliseconds, which is pretty good considering that this HDFS cluster has over 1.6 billion objects (that metric counts directories, files, and blocks together). The cluster has no doubt grown even more in the past year.
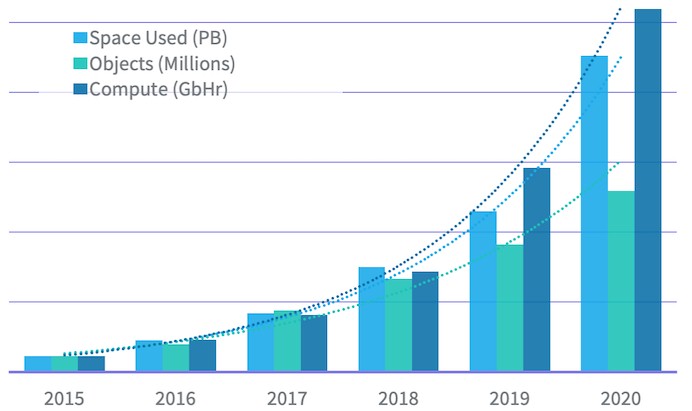
To give you a sense of what it is like to have to scale, in 2015 — a mere six years ago — LinkedIn had 20PB of data and had 145 million objects in that HDFS storage. Interestingly, LinkedIn measures compute capacity in how many bits of data are pulled through the server node RAM over time, and calculates a metric called Gigabit-Hours (GbHr), like the Kilowatt-Hours (KwH) used to gauge electricity usage. The expanding usage of machine learning in the past three years has upped the compute metric. In 2020, this compute performance metric hit 50 million GbHr, nearly 2x what it was in 2019, and we suspect it will nearly double again here in 2021.
LinkedIn is not explicit here, but it looks like it has a single cluster at 10,000 nodes that runs analytics and machine learning with 500PB of capacity through 2020, and then it has another collection of Hadoop clusters with another collective 500PB of capacity that runs its application and create the knowledge graph linking people to each other and companies over time.
In a new LinkedIn Engineering post this week Keqiu Hu, an engineering manager at LinkedIn, said that the Hadoop clusters grow at 2x per year. That does not necessarily mean the company will have a 20,000-node cluster, but rather that the node count will grow along with the storage and compute needs and then LinkedIn will have to partition those Hadoop clusters in a way that makes sense. And for a sense of perspective, all of LinkedIn would take probably a fifth of a datacenter. Each Azure region has multiple availability zones, which themselves have one or more datacenters capable of housing 100,000 servers or so. Microsoft has more than 60 regions, and likely a few hundred availability zones and therefore likely several hundred to close to a thousand datacenters. That puts Microsoft at somewhere between 5 million and 10 million servers, depending on how full those datacenters are with machinery. And that makes LinkedIn, with maybe 20,000 total nodes in 2020 and maybe 40,000 nodes as 2021 comes to a close, a drop in the bucket. Like maybe a half percentage point of the total capacity of Azure. So call that a half-drop in the bucket.
That’s how big Azure is compared to the biggest corporate social network in the world.
Every piece of software has its scalability limits, and LinkedIn reckoned that it was going to run out of scale on HDFS long before it was going to run out of scale on the YARN resource manager and job scheduler that came out in 2015 and that, unlike the original MapReduce method in prior Hadoop generations, split the resource management and job scheduling/monitoring work into two different daemons. HDFS started running out of gas in 2016, and LinkedIn created Dynamometer to measure HDFS NameSpace performance and to see how it will perform as more load is applied to an actual system. This software was subsequently open-sourced so others could benefit. YARN started running into trouble in 2019 as LinkedIn started pushing scale hard, and the company created DynoYARN to simulate load on YARN clusters at any size and with any workload. This DynoYARN modeler has been open-sourced as of this week, too. This simulator can model 1,200 Hadoop nodes on an eight-node physical cluster, which is a good ratio.
LinkedIn likes to have 95 percent of its analytics jobs finish in ten minutes or less, and with the DynoYARN tool it ran a simulation to find where performance would run off the rails so actual workloads don’t do this as LinkedIn is trying to make money. Here is what it kicked out in a recent simulation:
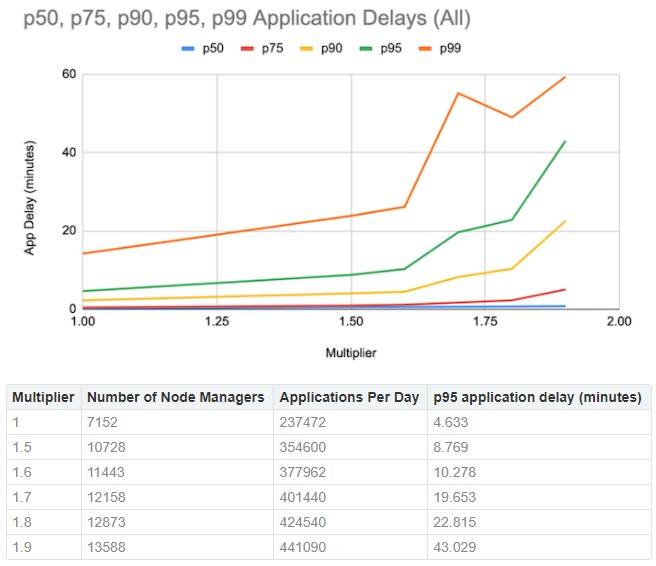
This data shows the interplay of the number of YARN node managers and the number of applications it can run against the 95th percentile time to run the applications. In this case, application scale and node scale with each other, on slightly different vectors. The baseline in the chart above is a cluster with 7,152 node managers and it can handle 237,472 applications per day and do it all within a 95th percentile window of 4.63 minutes. Boosting the workload by 50 percent required 10,728 nodes and the 95th percentile window rises to 8.8 minutes. Another ten percent more workload pushes it outside of the window.
What the tool does not seem to do is tell you how to add more nodes and get more performance, too.
To deal with the scale issue, LinkedIn is partitioning its Hadoop infrastructure into 5,000-node sub-clusters and then federating the clusters in such a way that workloads can flow over the sub-clusters as needed, all controlled by a load balancer that LinkedIn has developed called Robin. (As in “round robin,” we presume.) Robin tells YARN what clusters can do what work, and YARN allocates the work to the appropriate clusters. It is a little more complicated than that, since LinkedIn has a workflow orchestration engine called Azkaban that turns workflows into YARN submissions so end users don’t have to talk to YARN at all. This is akin to the Borg resource manager, container controller, and job scheduler at Google that was created to orchestrate MapReduce jobs and GFS data and that inspired parts of the Kubernetes container controller that Google open-sourced in 2014.
Here is the tradeoff of using Robin, which is neat. Because each sub-cluster in the analytics cluster has only 5,000 nodes, only half of the 500PB of data that LinkedIn has amassed for analytics is available for any analytics job. And to keep from developing I/O bottlenecks and hot spots across the HDFS infrastructure, nodes on the two subclusters had to be striped across the racks in its datacenters, with half of the data in each rack coming from one cluster and the other half coming from the other cluster — rack striping, as LinkedIn calls it. This apparently works well — for now — with the rack and pod setups that LinkedIn has.
And now, LinkedIn’s engineers are trying to figure out how to lift and shift its 10,000 node Hadoop cluster to Azure, and how to deal with noisy neighbor issues (go bare metal and don’t share is our answer) as well as figuring out how to rout Robin across on premises servers and cloud instances and figuring out how to add disk utilization awareness to the YARN job scheduler. At some point, says LinkedIn, Robin will be open-sourced as well, but not until it has a bit more features and finish.

The Opposite Of Snowflake: Analytics Without The Data Warehouse
As we have pointed out before, large enterprises have to deal with a different kind of scale issue than the hyperscalers, and in many ways, the hyperscalers have it easier. The hyperscalers have dozens of core applications that they have to run at massive data scale – pushing up to …

Why the Fortune 500 is (Just) Finally Dumping Hadoop
Remember how, just a decade ago, Hadoop was the cure to all the world’s large-scale enterprise IT problems? And how companies like Cloudera dominated the scene, swallowing competitors including Hortonworks? Oh, and the endless use cases about incredible performance and cost savings and the whole ecosystem of spin-off Apache tools …
Automagically Moving Legacy Hadoop To The Cloud
Always on the lookout for the kernel of a new platform, we chronicled the steady rise and sharp fall of Hadoop as the go-to open source analytics platform. In fact, we watched it morph into a relational database of sorts only to end up being cheap storage for unstructured data. …
Be the first to comment