
There is an old joke that in the post-apocalyptic world that comes about because of plague or nuclear war, only two things will be left alive: cockroaches and Keith Richards, the guitarist for the Rolling Stones. As it hails from New York City, you can understand why Cockroach Labs, the upstart software company that is cloning Google’s Spanner distributed relational database, chose that particular bug to epitomize a system that will stay alive no matter what. But, they could have just as easily called it RichardsDB.
When discussing Google’s cloud implementation of Spanner, which launched in beta earlier this week, we promised that we would have a sit down with the people behind the CockroachDB effort, who not coincidentally all hail from the search engine giant and who all worked on key parts of the software infrastructure that sets Google apart. We think that CockroachDB has the potential to shake up the database market, and not just because the people behind it understand deeply what Google did but more importantly because they have come to understand the very different approach that is necessary to commercialize the ideas that are embodied in Spanner and that are being coded into a free and open source CockroachDB.
Cockroach Labs has the potential to be Yahoo’s Hadoop and HDFS to Google’s MapReduce and Google File System, but in a database market that is ripe for change and among enterprise customers who want simplicity from complex systems and they want them to scale instantly, easily, and geographically.
Spencer Kimball, co-founder and CEO at Cockroach Labs, lays the gauntlet gently on the New York City sidewalk, not seeing the need to throw it down. “We are not satisfied as a company to fast follow Google forever, Kimball tells The Next Platform. “I think this has been a tremendously smart thing for us to do because Google spent the better part of a decade developing Spanner, and they came to the conclusion that they needed it and then they evolved it through blood, sweat and tears and a huge number of use cases. And what they came up with is a solution that they are moving all of their major use cases towards, and this is a fundamental bellwether of where the industry is going. But we are not going to be content to only fast follow them.”
Kimball and his co-founders, Peter Mattis and Ben Darnell, all hail from Google and they know plenty about how Google’s hardware and software infrastructure works. Kimball is the co-creator of the open source GIMP graphics editing tool, which he created while at the University of California at Berkeley during the dot com boom more than two decades ago. Mattis was his roommate in college and the other creator of GIMP, and both joined Google and both worked on the Colossus distributed file system that is the successor to the original Google File System that gave the company such an edge over its rivals in the search engine and then the ad serving business. Darnell worked with Kimball and Mattis at a company called ViewFinder a few years back (which they sold to Square) and did his own stint at Google and several other companies before that and is now chief technology officer at Cockroach Labs; Mattis is vice president of engineering. And the three things they have in common is that they used Google’s Colossus file system and then BigTable and Spanner databases and wanted to use it for new projects. But it wasn’t open source. So in late 2014, they decided to clone it.
In the past two years, the three former Google software engineers have raised $26.5 million in their first two rounds of venture funding, led by Benchmark Capital and Index Ventures with a little sweetener from Google Ventures, by the way, and a half dozen others. The company has 33 employees at this time and is building fast. The CockroachDB distributed database went into alpha testing in 2015, soon after the company was founded, has been in beta testing throughout 2016. The company is getting set to have its formal 1.0 release at the end of the first quarter – so within the next month. If you are wondering why Google might have launched its Cloud Spanner service ahead of its own Next ’17 conference in two weeks, it might have been to try to steal a bit of thunder from CockroachDB, its open source clone.
Spanning The Enterprise
There are multiple problems that Spanner and its CockroachDB clone are trying to solve all at the same time, and Google has fifteen years of experience, building its Megastore and BigTable database services and the Spanner geo-replicated evolution of BigTable, on which Kimball, Mattis, and Darnell can draw upon (not literally, but metaphorically, just like Doug Cutting at Yahoo was inspired by MapReduce and GFS to create Hadoop and HDFS) to create an open source and enterprise-grade alternative to Spanner.
All applications need some means of storing data, either in a raw format or in a database with some structure wrapped around it to make it indexable and more easily and more quickly searchable. Way back when, Google would run a data service in a single datacenter, and it would fail for whatever reason and that service would be out and an application would be offline. This was obviously unacceptable. In the next stage of Google’s evolution, which is where most enterprise companies are at today, it set up a backup systems and constantly replicated its databases to a separate datacenter. For mission critical applications, most enterprises have a standby set of hardware and software ready to run in that second datacenter and in the event of a failure they hope it spins up. “It is not normally active, it is on standby mode, and in that case, things often rot and they won’t stand up,” explains Kimball. “This is problematic from a production perspective.”
But there is an even more insidious problem in this high availability failover mode: there is a lag in the data that is being replicated between the datacenters because it uses an asynchronous process. You can write something across the wire to the remote facility, but that takes time and if there is a failure they might not see all of the data they had originally written in the old datacenter because it did not make it over to the new datacenter before the failure.
This is why Google implemented Paxos consensus and multi-active availability with Spanner. With this setup, a minimum of three sets of compute (they can be single nodes or clusters of nodes) have to be set up and linked by LANs or WANs with very strict timekeeping. Google uses atomic clocks and GPS receivers in its datacenters as well as a protocol called TrueTime to keep precise timestamps on write transactions coming into any of the compute portions of the nodes or clusters. For any write to commit to the distributed database, at least two out of the three nodes have to agree that they have the data and have successfully written it. If Google has a database that spans more nodes or clusters or regions, it can dial up the consensus level.
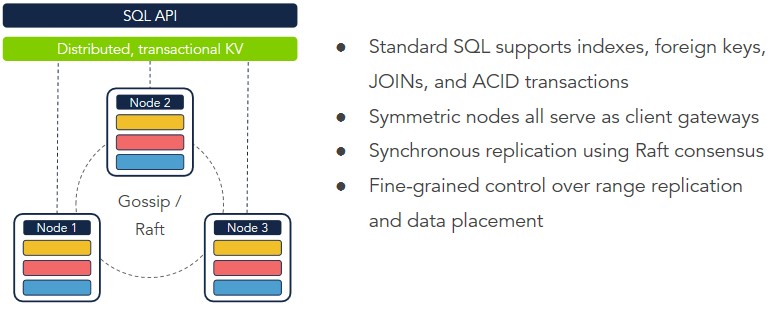
“Cockroach and Spanner are very similar when you look at them in terms of their capabilities,” says Kimball. “The biggest difference is that we are building something that needs to run in many different environments, and we cannot rely on atomic clocks and specialized hardware. So that very much changed the subtle guarantee we give. With atomic clocks everywhere, Google is able to offer linearizable isolation, and CockroachDB provides serializable isolation, which is still a very strong guarantee but it is still not as strong as what you can get with atomic clocks. It is important to note that CockroachDB can behave exactly like Spanner if you give it atomic clocks. The difference between CockroachDB and Spanner is that Spanner is able to operate with a much smaller bound on the possible offset between any two clocks in the system, and Cockroach needs to rely on Network Time Protocol, which is not nearly as accurate as having an atomic clock in each datacenter. That is the big difference and a fairly subtle one.”
There are other big differences, which we will get to in a moment.
Kimball, Mattis, and Darnell did not start completely from scratch in creating CockroachDB. Like other open source projects, CockroachDB relies on prior work done by others – including some database luminaries at Google and Facebook, as it turns out.
CockroachDB is based on the RocksDB low-level storage engine that was created by Facebook and that is the interface to disk and flash storage on server nodes that comprise the CockroachDB cluster. This RocksDB storage engine is itself derived from the LevelDB key/value storage engine that was created by and open sourced by Google and that was based on ideas embodied in Google’s BigTable and Spanner databases services. (BigTable is a single instance of a horizontally scalable SQL database, and Spanner is a geographically distributed one using Paxos consensus for replication.)
The bulk of CockroachDB is written in Go, which is a language created by Rob Pike, one of the Bell Labs programmers that brought us Unix and C and who more recently works at Google. Go is popular with Googlers. Kubernetes and TensorFlow are both written in Go, which is a dramatic simplification of C++ that Kimball says is very opinionated in how code is structured and therefore there are few different ways of writing that code, which makes open source code line up well across and within projects. It also has sophisticated services for integrating with C++ code, which is often used in spots to get code as close to the iron as possible to boost performance. RocksDB, by the way, is itself written in C++ and has been tweaked a little bit by Cockroach Labs.
For consensus replication, CockroachDB does not use the Paxos method employed by Google but makes use of etcd, which was created by CoreOS, the maker of its eponymous (and Android-inspired) Linux distribution and the commercial Kubernetes platform called Tectonic. Strictly speaking, this consensus mechanism is based on a method called Raft.
In addition to this multi-active availability mechanism, CockroachDB automagically shards data and spreads it around local nodes as the datasets grow. You just add server nodes to a network and it figures this out all by its lonesome, which provides the horizontal scalability.
“Scale is very important, and a lot of companies feel like they don’t need scale, that they can keep everything and keep scaling up in a single instance of the database,” Spencer admonishes. “But the reality is that there is a ton of data that companies are generating that they are not storing with in their operational systems, and they are often putting that in other systems which complicates their data architecture. Scale is actually more of a common need than people let on, I would say. And then of course you have companies out that that are desperate for scale and they are struggling and sharding databases and for them it is very clear that a system that lets you have SQL and also scale it is an important innovation.”
This is a lot trickier than it sounds, obviously, and it allows for servers to be replicated locally within a rack as well as across racks and across datacenters and regions to provide increasing resilience to certain kinds of failures. This is how Spanner and CockroachDB are similar. But they are very different in some important ways.
One is the way they are packaged, and this is something that has made it difficult for Google to open source a variant of its Borg/Omega cluster and container management system.
Google takes a layered approach to everything. Spanner is not just one system that runs in isolation, it runs on top of other systems. It uses Chubby, which is very much like Zookeeper, and it uses an atomic clock system called TrueTime, and it uses Colossus, which is a distributed file system underneath it. And Colossus is built on top of a system called D, which is a service that exports disk capacity from server nodes to the wider Google ecosystem.
“When you have something as complex as Spanner, it is dependent on many things that are competently created and managed and maintained by exceptional teams, and within Google that is a big advantage because they are not reinventing technology,” says Kimball. “If you want to replicate data within datacenters, you just use the distributed file storage, which is Colossus, and Colossus is not reinventing the wheel on how to efficiently export disk resources, this is done by D. They are able to leverage previous work.”
This doesn’t work so well out there in the open source world because setting something like Spanner up is incredibly difficult.
“The number of services that are needed to set up Spanner would probably defeat a single person, even someone at Google. It would be very difficult to stand that up, if not impossible. And that is the real challenge if Google wanted to open source Spanner. They would be open sourcing many services, and we are probably talking about hundreds of millions of lines of code. That is not really practical, and that is why they are taking a different approach. From the ground up, with new things, they are trying to make them stand up on their own.”
Kubernetes and TensorFlow are examples of Google software that has not only been open sourced, but which has been turned into software (sometimes by a community as is the case with Kubernetes) into something that can be stood up as a free-standing application.
“The backbreaking work is making CockroachDB deployable,” Kimball explains. “In fact, CockroachDB is more deployable than any other distributed database out there. It is an incredibly simple model in that every single node – we call them roach nodes – is symmetric and self-contained with a single binary. There are no external dependencies, so you don’t need Zookeeper running, you don’t need etcd or a distributed or shared file system underneath like Oracle needs with its Real Application Clusters. It is simple as taking one statically linked binary with no dependencies and putting that out on some VM somewhere and pointing it at any other node in a CockroachDB cluster and it joins up and they self organize. So making that work with a single binary was a huge challenge and a big departure from the way Google chose to build Spanner.”
Another big difference is support for SQL, and Kimball had plenty to say about this.
“This is a really interesting point,” he says excitedly. “We have had to build CockroachDB to be deployable as open source in a way that doesn’t need TrueTime and that meets all of the needs of these companies. With open source and there being such a low barrier to try it out and kick the tires, you really need to have a very comprehensive, compatible interface with the outside world. You can’t really cut corners. So we decided to make CockroachDB look like Postgres because it is a better thought out database than MySQL. The nice thing about making it look like Postgres is that all of the applications and languages have drivers for it.”

Postgres was chosen for another reason over MySQL or some other database management system to emulate. The open source Postgres database has a better implementation of the higher-level abstraction called Object Relational Mapping, which creates a translation layer between SQL and the programmer. Kimball says programmers and database designers have very different ways of thinking about objects placed in-memory data structures, and that the ORMs give programmers a way to do what the database designers want using a standard SQL interface.
“There is an impedance mismatch there, and it is fairly extreme,” says Kimball. “So it is very awkward to use SQL from a programming environment to access your data – to read it and to write it. So this Object Relational Map creates a translation layer between SQL and the programmer, and these require that CockroachDB or any other database that supports them to have a very standard SQL interface. Spanner – and this is a very interesting decision on Google’s part and hints at the mindset that has persisted in terms of the early failures of BigTable in the cloud – does not have a standard SQL interface. On the one hand with read only queries, it is very standard, using a SELECT mechanism. They created some good, modern SQL syntax and introduced some new stuff. But what they haven’t done is create enough of a familiar surface area in the APIs that the Spanner servers are presenting to the applications in order to enable the huge number of tools that expect SQL in some dialect or another. They have a completely proprietary, RPC-based interface for doing inserts and updates, and it is a strange choice and it will obviously prove to be a barrier to adoption. I am not sure what their roadmap is, and it might be to very much improve that and make standard ORMs work. But that was an interesting product decision on their part. We took a very different route and saw that we needed to make these ORMs work, and possibly to delay our 1.0 release to make that happen. This is crucial, this is how people use these databases, and you don’t just want to cut the legs out from under the developers out there. I am not going to prognosticate about their plans, but they have so many resources and so many programmers that they can take Spanner anywhere.”
CockroachDB supports most of the important SQL 92 standard and has some capabilities of SQL 2011 as well as some Spanner functions that are unique to Google. Cockroach Labs will be adding NoSQL functions such as native JSON support, which will help with full text indexes, and will be adding geo-partitioning capabilities, probably in the wake of the 1.0 release. As for pricing, Kimball has not set it as yet, but says with a certain amount of tongue in cheek that it will not cost less than an enterprise subscription to the MongoDB NoSQL database and will cost less than Oracle’s eponymous database plus its RAC extensions.
As for performance, using plain old Ethernet networking of reasonable speed on nodes with SSDs for storage, Cockroach Labs has been able to scale the database up to a hundred nodes and deliver around 50,000 transactions per second of throughput without any optimizations of the code yet; this equates to around 7 billion transactions a day, and working over a WAN that is not exceptional in bandwidth or low latency, it can deliver a mix of read and write transactions in no more than 50 milliseconds and often does it in under 1 millisecond.
Perhaps the most important thing about CockroachDB is that it can be deployed in private or public clouds, or across both, and because of the automatic replication, this is not just a way to replicate data across different sets of infrastructure, but moving it to different infrastructure. You can set up a CockroachDB cluster, get data on it, and then turn something off and not do anything else to port the data. Enterprises are going to love this portability.
“The experience of Dropbox with S3 on AWS shows just how risky it is to trust what is essentially the most important asset of a modern corporation to the proprietary storage system of one of these cloud vendors,” says Kimball. “Dropbox spent probably an engineer-century architecting an alternative to S3, and that was a choice they made very deliberately because of the economics – and despite the massive volume discount that AWS was giving them on S3. At some point, those cost curves invert. It is very inexpensive to install an incremental service like storage, but at some point, you still have to accommodate Amazon’s profit margin in there. You have economies of scale, and eventually it points to doing it yourself.”


Datacenter Infrastructure Report Card, Q3 2023
It is hard to keep a model of datacenter infrastructure spending in your head at the same time you want to look at trends in cloud and on-premises spending as well as keep score among the key IT suppliers to figure out who is winning and who is losing. And …

OpenPower Puts Open Source Software Guru In Charge
If you want to build a successful hardware ecosystem around a chip architecture that has recently been open sourced, as the Power chip instruction set was last August, then it probably makes a lot of sense to put someone at the helm of the project who has deep and broad …

What We’re Getting Wrong About Efficient AI Training at Scale
Famed computer architect, professor, author, and distinguished engineer at Google, David Patterson, wants to set the record straight on common misconceptions about carbon emissions and datacenter efficiency for large-scale AI training. First, the picture is not quite as bleak as it seems for energy consumption and AI training at hyperscale. …
Be the first to comment