

A number of chip companies — importantly Intel and IBM, but also the Arm collective and AMD — have come out recently with new CPU designs that feature native Artificial Intelligence (AI) and its related machine learning (ML). The need for math engines specifically designed to support machine learning algorithms, particularly for inference workloads but also for certain kinds of training, has been covered extensively here at The Next Platform.
Just to rattle off a few of them, consider the impending “Cirrus” Power10 processor from IBM, which is due in a matter of days from Big Blue in its high-end NUMA machines and which has a new matrix math engine aimed at accelerating machine learning. Or IBM’s “Telum” z16 mainframe processor coming next year, which was unveiled at the recent Hot Chips conference and which has a dedicated mixed precision matrix math core for the CPU cores to share. Intel is adding its Advanced Matrix Extensions (AMX) to its future “Sapphire Rapids” Xeon SP processors, which should have been here by now but which have been pushed out to early next year. Arm Holdings has created future Arm core designs, the “Zeus” V1 core and the “Perseus” N2 core, that will have substantially wider vector engines that support the mixed precision math commonly used for machine learning inference, too. Ditto for the vector engines in the “Milan” Epyc 7003 processors from AMD.
All of these chips are designed to keep inference on the CPUs, where in a lot of cases it belongs because of data security, data compliance, and application latency reasons.
We have talked about the hardware, but we have not really taken a deep dive into what all of this math engine capability really means for those who are trying to figure out how to weave machine learning into their applications. So we are going to take a stab at that now. How do you program to allow my neural network to make use of what they are providing me AND get this range of performance numbers. IF you can do that, THEN you will be impressed, ELSE not so much. It turns out that, given what we know about AI today, their solutions are both a lot more elegant and expedient than, say, adding instructions like DO_AI.
So, to have everyone up at the same level before talking processor architecture, let’s start with the usual picture representing a small neural network.
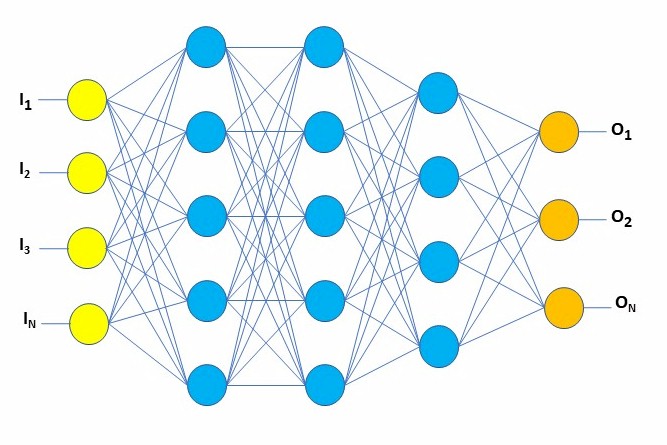 This represents today’s best representation of our model of what we think the neurons in our brain are doing. Where I think I understand that our brain’s neurons are using analog electrochemical messaging between neurons, here we are talking about numbers, links, and probabilities — stuff today’s computers are capable of working with. Inputs at the left are numbers, outputs at the right are numbers, each node above represents sets of numbers, and even these links between them are numbers. The trick is to introduce scads of numbers at the left, far more than shown there, run it through the blue filter, and kick out meaningful numbers at the right.
This represents today’s best representation of our model of what we think the neurons in our brain are doing. Where I think I understand that our brain’s neurons are using analog electrochemical messaging between neurons, here we are talking about numbers, links, and probabilities — stuff today’s computers are capable of working with. Inputs at the left are numbers, outputs at the right are numbers, each node above represents sets of numbers, and even these links between them are numbers. The trick is to introduce scads of numbers at the left, far more than shown there, run it through the blue filter, and kick out meaningful numbers at the right.
Allow me to stress that this picture is a tiny representation of what is often happening in AI models. As you will see in another relatively simple example shortly, picture this as being potentially many times taller, with far more nodes and therefore far more links — multi-megabyte or even hundreds of gigabyte data structures supporting this should not be considered uncommon. And this entire thing needs to be programmed — no, actually trained internally — with other numbers which are used to produce reasonable output from reasonable input. Why do I mention this here? Performance. This all can be done, and is being done today quite well thank you, without specialized hardware, but especially the training of this thing can take … well, way too long, and we all want it to be faster. Fast enough? Hmm, wait another ten to twenty years for the next revolution in AI.
So, numbers and size. Let’s start off with a story in order to lead up to a relatively simple example. My adult daughter borrowed our Minnesota pickup truck to pull a trailer in Iowa, where she subsequently was speeding, and had the truck’s picture taken as a result. We, in Minnesota, received an automated citation, demanding money, and included a picture. Peeved I was, but also intrigued. What process took that JPEG and converted it into a citation against me? I assumed that AI was involved.
So, let’s start with a Minnesota plate. Easily readable, but also higher resolution (512 horizontal pixels), perhaps larger than the camera is capable, but also likely much larger than is necessary for the neural network as an input. The point here, though, is to note that once the plate is found in the photo, the state and about 6-8 characters of text must be determined from these pixels.

At 1/8 of this size, the size which the speed camera might find, we’d have the following tiny image:
![]()
which when blown up for you to actually see we find:

An AI application might be able to sort out the license number – you, after all, obviously can – but perhaps not which state. So, let’s double that resolution and go to ¼ of the size (128 horizontal pixels) as in the following:

and then if blown up:

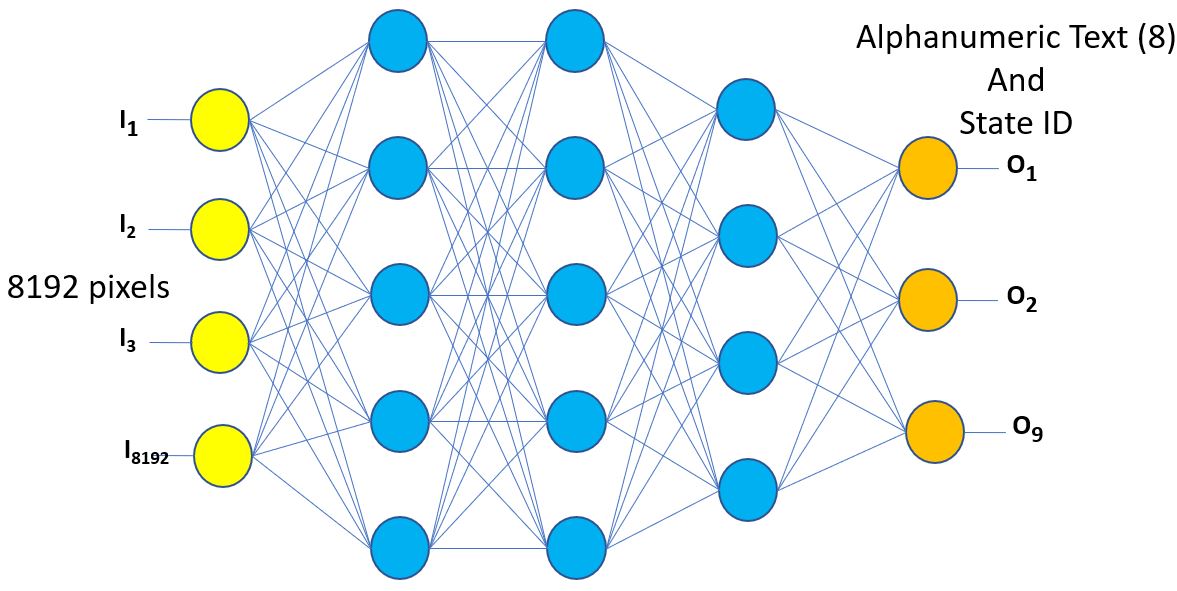
Maybe something less remains reasonable, but let’s go with this size. According to the file details, this image is 128 x 65 pixels in size. Let’s also assume some form of gray scale instead, so let’s say one byte per pixel. All told, let’s call it 8192 bytes to represent all of these pixels. Slightly smaller still if Iowa did not care that Minnesota is the land of 10000 lakes. Iowa’s AI model needs to convert those 8192 bytes representing pixels into characters of text — up to eight of them — and a state ID, for subsequent lookup in some Minnesota state database accessible to the state government of Iowa. That 8192 bytes, one byte per yellow vertical input node per the above graph, is your set of input parameters into Iowa’s neural network.
Referring back to the graph above, you will notice that each (yellow) input byte, with some mathematical munging, is to be passed to every node at the next (leftmost blue) layer. This munging is where the enhanced hardware comes in, but I need to build up a base enough to see why the enhanced hardware makes a difference. Please bear with me.
Next, that neural network is at first just a very large bunch of empty blue nodes. At first for the model, it’s “A license, what’s that?” It needs to be trained to recognize any license. Keep in mind that the yellow nodes input values change from license to license, and there are millions of different ones. Iowa is expecting that for a large percentage of all of those licenses, from — what(?) — 49 states that this network is capable of kicking out on the right up to eight characters along with the state ID. Clearly enough, an empty neural network is not going to be successful even in the least. The network needs to be primed — trained — and that is done by repeatedly showing the network hundreds of thousands of licenses and with each pass making subtle adjustments to the internals of the network based on the output. Obviously, I’m not going to take you through the science of tuning the individual nodes of this network here, but for now just picture it as an intensely iterative process with improving success rates as the process of adjusting the model’s internals continues. In short, the Machine needs to Learn (as in Machine Learning) how to interpret any car license plate, converting here grey scale pixels into characters.
Again, I am getting closer to the hardware.
In the following figure, I’ve taken the input layer from the neural network graph above and show these being mathematically munged to next produce output of here only two nodes of a next level — one green, one blue. Again, keep in mind that there are many vertical nodes in the next (and the next and the next) level(s). You’ll notice a function shown there. That function takes each individual input value (Ii), multiplies it by an associated weighting value (Wi) and then adds all these product values together. The addition of a bias value is used as an input to the next level of the network with a last step of the function doing a form of scaling. Said differently, given the green node, it takes as input the values represented by all of the yellow input nodes, multiplies each by an associated green weighting value (Wi), and then adds all of those multiplication products together. After biasing and other functional adjustments, this becomes the output of the green node. So, again, compare this to the overall graph which I am showing again below to get the bigger picture. This is just repeatedly done with each subsequent node, and there are lots of them. And then repeated nearly ad infinitum as more input is provided, with this process resulting in changing these weight values, ultimately leading to a high probability of success at the output.
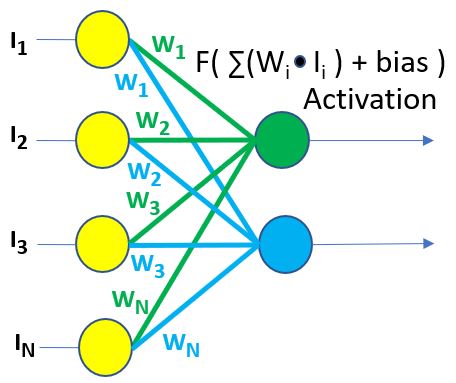
Keep those multiplies and subsequent adds in mind. There are a lot of them, and our toy license filter is a relatively small example. During the training part of this neural network, we are doing them over and over and over as each of the weighting values are adjusted. (That process of adjusting weight values is interesting in itself, but not really pertinent to the associated hardware enhancements. Training of a neural network is the process of changing these weights until the overall output is consistent with what you expect.) It’s the frequency of these operations that is the key to performance here. If you want the neural network’s training to be fast, you need the totality of this arithmetic to be fast.
I am sure that the Intel engineers would appreciate my showing off their architecture [@ 29:30] (and kudos folks), but if I may, I’m going to spend the next few paragraphs focusing on what IBM’s Power10 engineers did to enhance their recent processor in support of the above.
To get a mental image of what they did, perhaps start by focusing on any one of those blue nodes. You see that one type of input is the set of, say, 8192 yellow nodes’ gray scale values. (Remember, we are talking about that license plate above.) Another algorithm input then is the set of 8192 weighting values (the (Wi)) — one associated with each of the previous nodes. Let’s picture that as two arrays of byte values — one the gray scale bytes and the other weighting bytes.
I can hear the programmers in the crowd saying, no, I’d define the yellow nodes as an array or some list of objects. Yes, you very well might, but we are talking here about the software/hardware interface. You want it fast? Then you give your data to the hardware in the way that it wants to see it, arrays of input parameters and arrays of weights. So, please, humor me for now with a mental image of byte arrays. (Or, as it turns out, arrays of float, or small float, or short signed integer …)
A Hard Drop Into The Hardware
OK, as a starting point, we have a massive amount of data against which we are going to repeatedly execute the same operation over and over. And then, for training of our model, we tweak that data and do it again and again. And, of course, you want the whole blasted thing to be done fast — much faster than without enhanced hardware. Somehow we additionally need to pull all of that data out of the DRAM and into the processor, and then present it to the itty-bitty piece of the chip within a core to do this actual math against it.
Some of you are seeing what I am hinting there: an obvious use for a vector processor. Yup. So, for those of you not familiar with the notion of a vector processor, hang on, here’s your hard drop.
You know that processor cores have multipliers and adders, and instructions that take a couple of data operands and pass them through each. You are hopefully sort of picturing it as one multiply and then an add at a time. (It’s not quite that, but good enough for a start.) Each takes time — time that adds up when repeated ad infinitum. So, given the data is right there close to the hardware’s arithmetic units, done one at a time, how do you make that run any faster? If it’s the same operation over and over again against data which is now right there in the hardware and available, you pass multiples of that available data at the same time through multiple arithmetic units, and then all of those results are saved in the hardware — in registers — in parallel in the very next moment. A vector unit. Not one at a time, many at a time — in parallel. One of a set already in the processor cores. The new news for AI? New hardware to do multiple multiplies and adds, all as though a single operation.
I mentioned registers in the previous paragraph, a form of storage capable of feeding its data directly (in picoseconds) into the vector hardware. So, another hard drop, intended to give you a picture of what is going on. We’ve been talking in our little license-based example about an array of bytes. We could just as well be talking about units of 16 or 32 bits in size and for these both integer and floating-point numbers. (To be more specific, in IBM’s Power10 each core has eight vector units doing these operations and in parallel if that level of throughput is required, each supporting FP32, FP16, and Bfloat16 operations and four that support INT4, INT8, and INT16 operations.) To feed that data into the vectorized multiply-add — in this example contiguous bytes — in parallel, the data is read from individual registers in parallel, all together in the same moment. You’ll see this in a moment below. Fine, that’s the hardware. But the key is having loaded those registers with those multiple bytes from the cache/DRAM all also as a single operation. The hardware can execute the operations in parallel, it just needs software to ensure that the operands — contiguous bytes — are being presented to the hardware registers in parallel as well. There are load/store instructions related to the vector units for doing this as well. Notice that that last is a function of the structure of the data held within your AI models.
I’ve tried to represent that below, with the top figure representing bytes in an array (and contiguous bytes continuing on indefinitely). It is the bytes you see here — X[0][0] through X[3][3] ‚ which are loaded in a single operation into a single register (called in the Power architecture a VSR).
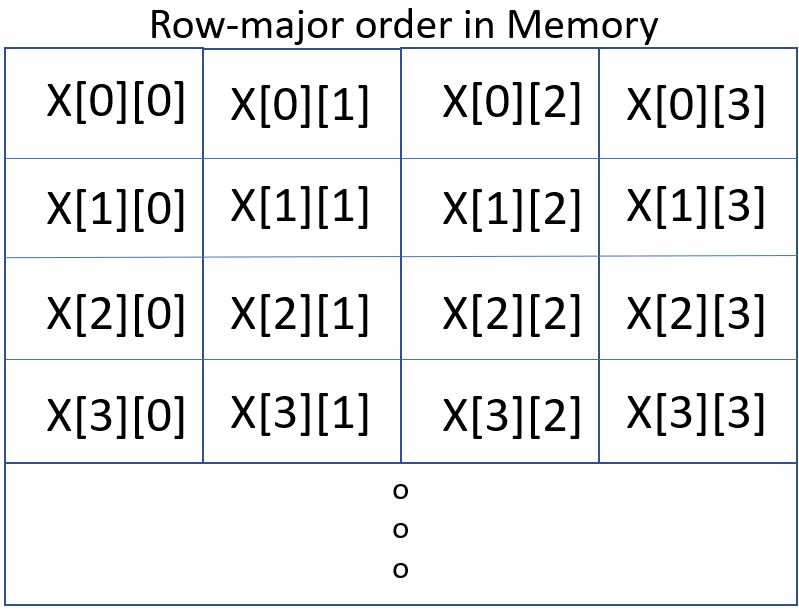
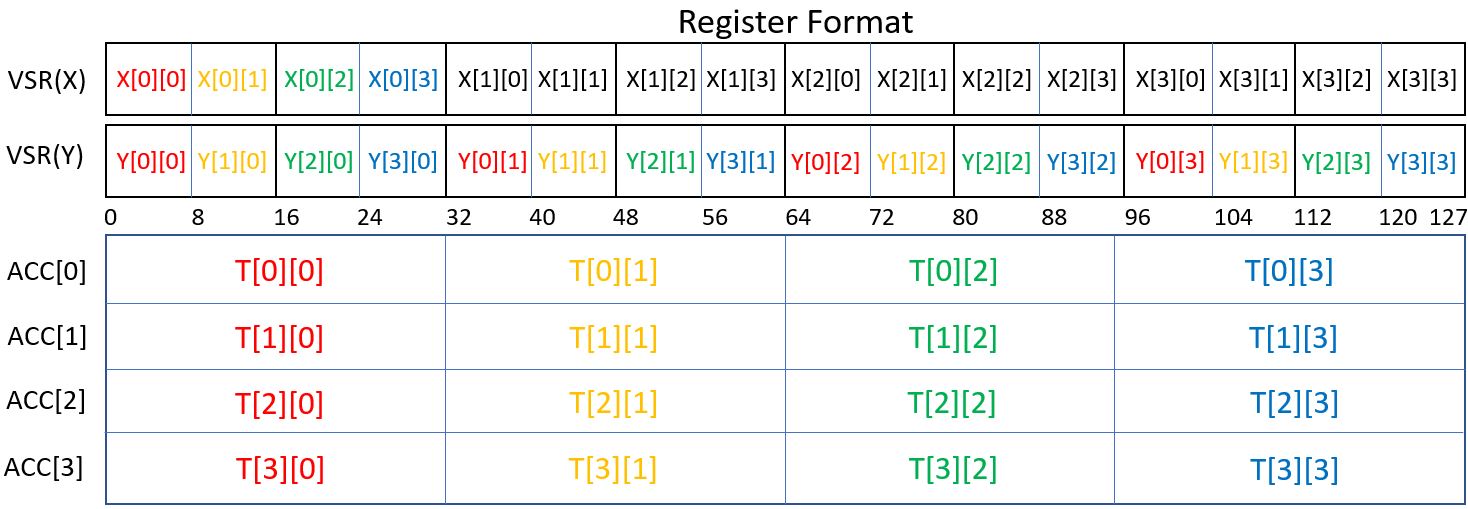
As to the remainder of the latter figure, getting back to the hardware’s vector operations again for a moment, a single instruction takes all the data in VSR(X) and does the multiply-add using all the data in VSR(Y) with the result(s) being placed into a set of four registers called accumulators (ACC). As perhaps too much detail, although done as a single operation, you can think of red parameter in VSR(X) as being multiply-added with all of the red parameters in VSR(Y), orange with all of the orange, green with green, and blue with blue, and then repeated to the right with the same coloration scheme throughout VSR(X). Essentially multiple of the blue nodes found in the graph at the same time. All in one operation. Continuing down through the prior array just means the parallel looping over the loading of the subsequent parts of the array(s) and executing another instruction which folds in previously accumulated results. A loop of operations doing an entire set of, here, 16 items at a time. All fed efficiently in parallel from the cache, and results returned efficiently to the cache.
An impressively elegant addition. But, yes, it takes some awareness of the relation between the data’s organization and the hardware to make full use of it.
And Then There Is The Cache
What I am going to observe here is not really so much an addition for AI/ML as it is a prerequisite to allow the data structures residing in the DRAM to make their way into that tiny bit hardware of each core on a processor chip to actually do the math — doing that efficiently and in parallel as well. You see, the cores don’t ever actually touch the DRAM. No, they don’t. The cores access their cache (multi-megabyte caches per core BTW, and far more per chip), cache(s) consisting of contiguous byte blocks of the contents of the DRAM memory. And once in the cache, if such blocks are reused in the relatively near future, we’re not suffering from DRAM access latencies.
The cores read their data from those cache lines — those memory blocks — as units of bytes or units all the way up through 16 bytes (128 bits are you saw above), but DRAM is accessed by cores as those blocks which are considerably larger. Since it takes a lot more time to access the DRAM than to access the cache, a key to performance is to minimize the number of DRAM accesses (a.k.a., cache fills). And the trick to doing that is to ensure that those blocks being accessed contain only what is wanted. So, again, back to those byte arrays, you want the hardware accessing — say — 128-byte portions of those arrays into it caches, and then almost immediately streaming the next and the next with no real delay until done. The hardware wants to stream those arrays — and nothing else — into its cache. Then, from those cached blocks, quickly load the registers 16 bytes at a time — also, BTW, in parallel.
The entire process of working through that AI graph as it resides in memory, and then to process it as you have seen above, has the feel of a well-tuned orchestra. It just flows. The hardware and software engineers planned this architecture all out to be exactly that. Of course, it is all well-tuned if the software’s data structures are well matched with the architecture of the processor. If not, it is as though the orchestra is playing staccato and the violin is playing in the range of the bass. I’m impressed with any good bass player, but in this case it’s better to be playing violin.
AI/ML At The Edge
Given the hopefully slow rate at which speeders are ticketed in my toy example, I can imagine that the speed sensors/cameras at the edge are merely passing full — albeit crypto-protected — JPEGs up to a single server for processing, and that the previously trained AI model used there is relatively static. Sure, those edge processors could have been sent today’s static model, with the actual filtering of the JPEG through that model being done at the edge. But those models are not always static in the more general world of AI/ML. Nor can all applications accept the implied longer latencies. Moreover, the edge processors may well need to do some adjustment of the model within their own local environment; the environment in which it finds itself might dictate a subtly different and actively changing model.
Maybe it is not so much machine learning and full out training there, but there are instances where the model needs to be changed locally. The (re)training game, though, is not all that different than what we’ve looked at above and often a lot bigger. And, again, this training needs to be done at the edge. Is the model used there at the edge producing correct results and, if it’s off somehow, how does it bring it back within expectations? And, of course, we need to do that on the fly without impacting normal use of the AI model, and within the compute capacity and the power envelope that I have available at the edge. We’re not necessarily talking HPC-grade systems here — something with specialized system add-ins to focus exclusively on machine learning. This newer type of processing implied by AI/ML is increasingly part of the game in which we all find ourselves, and Intel and IBM — and I know others — already seem to know that.


Talking System Architecture With AMD CTO Mark Papermaster
It is funny to think that in a certain light, AMD has Big Blue to thank for its resurgence in the datacenter. And not because IBM is not good at crafting processors and interconnects, but because some of the seasoned executives who honed their skills in semiconductors at IBM ended …
Ampere Computing Buys An AI Inference Performance Leap
Machine learning inference models have been running on X86 server processors from the very beginning of the latest – and by far the most successful – AI revolution, and the techies that know both hardware and software down to the minutest detail at the hyperscalers, cloud builders, and semiconductor manufacturers …

AMD Datacenter Sales Break Through $1 Billion In Q3
Here is a moment that Lisa Su, the chief executive officer who has lead the team that brought AMD back into the datacenter with the vigor the market needs, has been waiting six years for. In the third quarter ended in September, AMD’s datacenter CPU and GPU business broke through …
IBM has a public paper and another ISCA paper describing the benefits of their MMA architecture. Fast, efficient computation,minimozing data movement. The power10 rocks.
Would you mind linking that paper here? (And I agree.)
Real AI/analysis on a[ny] Database doing a CUBE on its contents will choke anything above 10GB. So…. what effectively remains are data models tightly coupled with some more or less-refined data algorithms projecting through prehashed patterns, if anything. We don’t need another row of shifty registers. IBM knows that. IBM knows what it needs to do real AI. IBM has a bunch of QCs. Hilbert space awaits.
So cute Big Blue toying with this. Power? Try some infinity if you want to create a being in your own image! But why stay in that loop? There is no new thing under the sun. All is vanity and vexation of spirit.