
It has been eight years since Arm announced its intentions to enter the server arena. But if you look at the processor landscape there today, you would have to conclude that the company’s efforts, along with that of its licensees who make the actual CPUs, thus far have not borne much fruit. Arm’s 2015 prediction that its chips would capture as much as 20 percent of the server market by 2020 looks like it will be off by about a little less than 20 percent. And Arm’s raising of the bar a year later to 25 percent of shipments seems truly ambitious.
However, if there is a potential bright spot for Arm in servers, it is in high performance computing. And the way the architecture is penetrating that space may illuminate a path to a broader server market.
Don’t get us wrong. Arm has not reached critical mass in HPC, either. Not by a long shot. Currently, there is exactly one Arm-based supercomputer on the TOP500 list – the Astra system at Sandia National Laboratories – plus a number of smaller, mostly experimental machines sprinkled here and there. At the Linaro Connect event last week, Arm’s Brent Gorda recapped some of those successes and offered a rationale on why he thinks the future is bright for the Arm architecture in supercomputing and elsewhere.
Gorda, who heads up the HPC business at the company, noted that high performance computing is actually a convenient entry point for Arm into the server arena. “HPC is a really good community to engage with when you have a new technology,” he explained. The community is exceptionally tolerant of stuff than almost works – but not quite.
Those remarks reflect Gorda’s three decades of HPC experience, some of which involved other non-mainstream technologies. That included a long stint at Lawrence Livermore National Lab where he headed up the BlueGene project using IBM’s iconic supercomputer architecture.
From his perspective, since the HPC community is in the business of pushing the boundaries of computing, they tend to be more willing to tolerate the rough edges on some of these early-stage technologies. And when it comes to adopting whole new processors like Arm, that can be a decided advantage.
At present, Arm’s biggest HPC success story is the aforementioned Astra system, built by Hewlett Packard Enterprise and powered by more than 5,000 of Marvell’s ThunderX2 processors. Gorda noted that ten years ago it would have been the fastest supercomputer in the world, but at 1.7 petaflops sustained on the Linpack benchmark, it is currently ranked at number 156. Nonetheless, it represents a milestone for Arm in HPC.

Probably the second-most notable Arm system up and running today is Isambard, a Cray-built machine that is using these same ThunderX2 processors. Gorda observed that Isambard is doing real production codes, including biomolecular simulations that are being used to study diseases like Parkinson’s disease and osteoporosis. Another Isambard project, this one being performed in conjunction with Rolls-Royce, involved running fluid dynamic simulations for jet engine designs.
The system is has also been used to benchmark a number of HPC applications and, as we reported last year, the ThunderX2 silicon outran Skylake CPUs on a couple of these codes (OpenFOAM and OpenSBLI), while getting beat by various margins on the others. Our conclusion was that these processors were definitely competitive on these workloads, and even more so from a performance per dollar perspective.
The Mont-Blanc project being run out of the Barcelona Supercomputing Center has been on the Arm bandwagon for almost as long as Arm the company has had designs on the server market. BSC’s three generations of pre-exascale prototypes all have had Arm silicon in them of one sort or another. The third iteration is in form of an actual production machine, in this case a Bull Sequana system outfitted with standard ThunderX2 processors.
But the real action for Arm-powered HPC is still to come. Japan’s first exascale supercomputer, now known as Fugaku (formerly Post-K), will be powered by Fujitsu’s 52-core A64FX Arm processor. As the first Arm chip implementing the Scalable Vector Extension (SVE) technology, the A64FX will deliver more than 2.7 teraflops at 64 bits, and multiples of that for 32-bit, 16-bit and 8-bit computation. Fugaku is slated to be up and running in 2021, which may make it the world’s first supercomputer to attain exascale status. (We drilled down into the Fugaku prototype here and into the Tofu D interconnect there.)
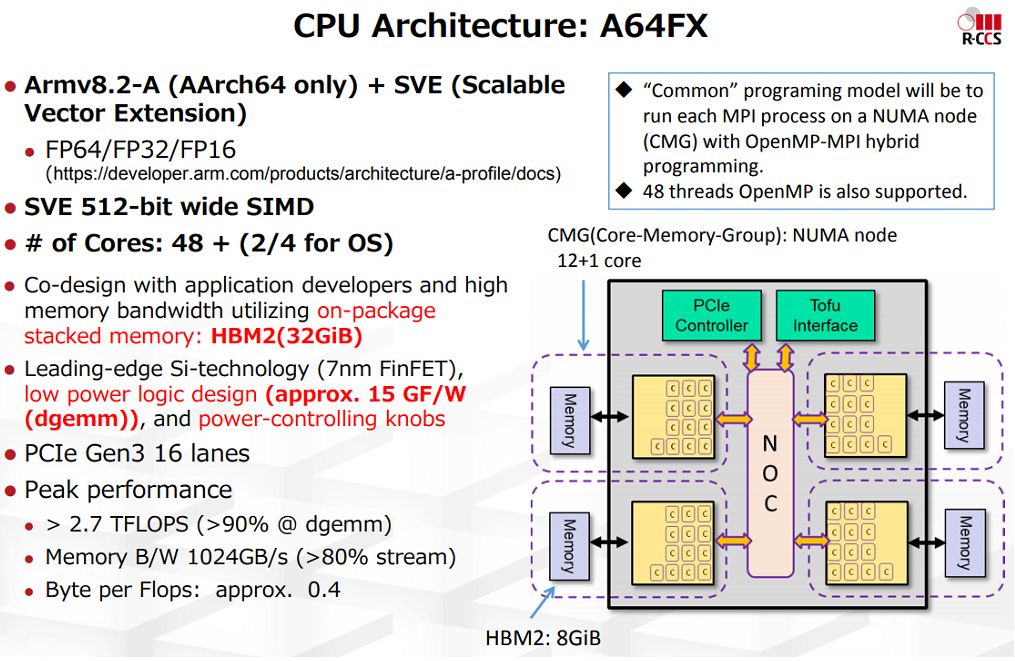
One of China’s three initial exascale supercomputers is also said to be powered by Arm processors. As we have speculated in the past, this is most likely to be the Tianhe-3 machine, even though the National University of Defense Technology (NUDT) has not been too forthcoming about the details. That system could be up and running as early as 2020, although that seems unlikely considering NUDT has only reported building a very modest-sized prototype (512 nodes) as of 2019.
As Gorda noted, the European Union will also be relying on Arm for its first exascale machines. Like the Fujitsu A64FX CPU, the Arm processor will be implemented as custom-designed SoC that includes SVE technology. However, unlike the A64FX, the EPI design will also include an RISC-V-based HPC accelerator in the package along with some other specialized chiplets.
While most of the important system software, such as the Linux operating system, C/C++ and Fortran compilers, MPI, and other runtime libraries have been ported to Arm, Gorda conceded that the long pole continues to be application code. In his conversations with potential users, they’re interested in having their particular application ported and tested on the processor before committing to switching architecture. Gorda said Arm is working to help “prime the pump” for such efforts and believes ISVs will benefit from downstream opportunities from such ports.
The company’s broader server strategy though will continue to rely on its hardware IP. The latest development here is the Neoverse line, a new family of Arm processors announced last year that will span the edge and datacenter. That will leave the Cortex line to focus exclusively on the mobile and embedded space. The first iteration of Neoverse, the “Ares” N1 design, was detailed by us here.
According to Gorda, the rationale behind this is that the nature of the Internet and scale-out processing more generally is undergoing a paradigm shift. Whereas the Internet has traditionally been used as a platform for delivering text, audio and video to client devices, pretty soon it will be used to ingest content of all sorts from a trillion devices sending data upstream. As a result, “the data flow on the Internet is about to turn around,” predicted Gorda.
He believes the opportunity here is huge since software will be able to migrate freely across a common instruction set between these two worlds, enabling users to select where best to run their workloads. And from his perspective, a lot of these workloads running outside the datacenter on edge-type servers are going to require supercomputing levels of performance. “We are going to be seeing HPC-like activities moving out to the edge – for latency purposes, for data movement purposes, for running algorithms that can do prediction better than your phone,” he explained.
That points to the real promise of the Arm, which is that its IP can be licensed by anyone to create customized implementations. While that model may be of dubious value for the modest volumes demanded by HPC or other high-end servers, for edge computing environments, it’s a more natural fit. And if the Neoverse IP can be leveraged between higher volume edge servers and the lower volume datacenter servers, that could turn out to be a winning formula. It really all depends on having one or more of the Arm licensees actually building processors that can be delivered in volume.

Other Than Nvidia, Who Will Use Arm’s Neoverse V2 Core?
We are still plowing through the many, many presentions from the Hot Interconnects, Hot Chips, Google Cloud Next, and Meta Networking @ Scale conferences that all happened recently and at essentially the same time. And we intend to take our usual, methodical approach of finding the interesting bits and doing …

AMD Will Need Another Decade To Try To Pass Nvidia
Lisu Su has turned in her first ten years at the helm of AMD, and what a hell of a run it has been. The company was a mess when she came on board two years prior to being named chief executive officer, and she took her knowledge of the …
You Can Load Up On Cheap Cores With Updated Milan Epycs
There are two ways that CPU makers can deliver more bang for the buck, and those running distributed computing workloads can go either way – or somewhere in between – as they build out their server clusters. The first is to push the process technology and architecture envelope to get …
Be the first to comment