

The HPC industry has been waiting a long time for the ARM ecosystem to mature enough to yield real-world clusters, with hundreds or thousands of nodes and running a full software stack, as a credible alternative to clusters based on X86 processors. But the wait is almost over, particularly if the Mont-Blanc 3 system that will be installed by the Barcelona Supercomputer Center is any indication.
BSC has been shy about trying new architectures in its clusters, and the original Mare Nostrum super that was installed a decade ago and that ranked fifth on the Top 500 list when it debuted is but one example when it adopted IBM’s PowerPC 970 processor instead of Intel Xeon chips, AMD Opterons, or regular Power5 chips from Big Blue. As we reported back in December, BSC is keeping its options open with the Mare Nostrum 4 production machine, which IBM is the prime contractor for and with the help of Lenovo and Fujitsu is building compute capability with that is comprised of 11 petaflops of servers based on Intel’s future “Skylake” Xeons, 1.5 petaflops of nodes based on the combination of IBM’s Power9 CPUs and Nvidia’s “Volta” Tesla GPU accelerators, 500 teraflops of nodes based on Intel’s current “Knights Landing” and future “Knights Hill” Xeon Phi parallel processors, and 500 teraflops of nodes based on the many-core ARM processor that Fujitsu is making for the Japanese government for the “Post-K” supercomputer.
This is not the first ARM-based system that BSC has deployed, and through the long-running Mont Blanc project, which has been testing out the idea of ganging up various embedded 32-bit ARM processors to run parallel workloads to help develop the HPC software stack. These machines were never intended for production use, but rather to push the envelope, as experimental supercomputers are supposed to. The current prototype, which is presumably going to be called Mont Blanc 2 in retrospect, consists of two racks of blade servers that make use of the BullX B505 blade server carrier from the Bull division of French IT supplier Atos, and BSC chose the Exynos 5 ARM chip from Samsung, which has two Cortex-A15 cores running at 1.7 GHz, for a CPU on each node. The Exynos 5 chip also has a quad-core Mali-T604 GPU, which supports the OpenCL hybrid programming framework that is commonly used on GPUs and increasingly on FPGAs as well. This Mont Blanc 2 machine has eight BullX blade enclosures, for 72 carrier blades with a total of 1,080 CPU-GPU cards in two racks, yielding 34.7 teraflops in a 24 kilowatt power budget.

With Mont Blanc 3, Atos is taking ARM for HPC up another notch with a real server chip, and in fact, with a special HPC variant of the future “ThunderX2” multicore processors from Cavium. When it comes to ARM processors, Cavium is one of the top contenders trying to take on Intel Xeons and the company is coming straight at the future Skylake Xeons with its second generation ThunderX2 chip, which was announced in June 2016, it is ratcheting up the memory bandwidth and cranking up the core count as well as switching to a new homegrown ARMv8 core that has out-of-order execution and can run at up to 3 GHz. The top-end 54-core ThunderX2 will deliver about twice the integer and floating point performance as the 48-core ThunderX that preceded it, and will also have about twice the memory bandwidth, too. (Cavium is shrinking the L3 cache and pumping up the cores to get a better balance.) In prior presentations, Cavium has suggested that the ThunderX2 chips will draw even, with some wiggle here and there, with a Skylake Xeon processor with 28 cores on integer and memory-intensive workloads and have a slightly larger performance bump when it comes to integrated networking and security algorithm processing.
The exact floating point and memory bandwidth performance for ThunderX2 has not been divulged yet, but Jean-Pierre Panziera, chief technology officer for HPC systems at Bull, which is making the Mont Blanc 3 machine for BSC, gave The Next Platform some insight into why BSC chose ThunderX2 for the third generation ARM HPC prototype.
“If you think that half of the HPC applications are memory bound, meaning they are limited by the memory bandwidth that the processors have, you can see that ThunderX2 could be a very good product for HPC,” explains Panziera. “High floating point performance is something that you can argue about, and this won’t be the peak of Linpack, but in terms of the average application, which uses extensive resources for accessing data from I/O and memory, this will have actually quite good performance. With the high bandwidth and out-of-order execution, this will be a substantial workhorse for HPC.”
The Mont Blanc 3 system will employ Bull’s Sequana HPC hardware, which was announced in the fall of 2015 and which is the liquid-cooled hardware platform that the French server maker has created to reach exascale. The Sequana X1000 hardware is at the heart of the Tera1000 supercomputer being installed at the Commissariat à l’énergie atomique et aux énergies alternatives (CEA), the French atomic agency that is equivalent to the US Department of Energy, and the basic Sequana design is expected to be used in systems for the next five years, and maybe longer, according to Panziera.
We profiled the Sequana system when it was launched, and for fun we will remind you that Sequana is the Latin name for the Seine River in Paris and is also the name of the goddess of abundance; both are appropriate given that the Sequana system is highly scalable while at the same time being water cooled. The Sequana system is based on a hardware aggregate that Bull calls a cell, which is a conglomeration of compute, networking, power distribution, and cooling that is installed as a unit in an HPC center. Each cell has three cabinets: two for compute and one for switching. Thanks to water cooling, there is no need for a hot aisle to get rid of heat, which means system elements can be packed into the back and the front of racks, like this:

Each compute cabinet in the Sequana system has 48 compute trays, each being 1U high and packing three server nodes. In a typical configuration, there are 24 trays in the front of each cabinet and 24 trays in the back, and the Sequana cell has two cabinets for a total of 96 trays and, at three compute nodes per tray, that works out to 288 nodes in a cell. (In some configurations that Atos shows, all of the nodes are facing front.) The switch modules are in the center of the Sequana cell and they provide the switches for linking the server nodes in the cell to each other and for linking multiple cells together to comprise a cluster. Bull supports InfiniBand and its own BXI interconnect. (We explained BXI in the Sequana profile.) The system can scale to over 64,000 nodes in theory, but no customers, not even CEA are pushing the limits yet. The Tera1000-1 supercomputer, which is the first phase of the Tera1000 project, has 85 blades crammed with Xeon Phi 7250 processors linked by a BXI network with a peak performance of 670 teraflops.
Bull has three Sequana sleds it is selling now: one with three pairs of “Broadwell” Xeon E5 v4 processors called the X1100; another with three “Knights Landing” Xeon Phi X200 processors called the X1210; and yet another with four “Pascal” P100 Tesla GPU processors called the X1115.
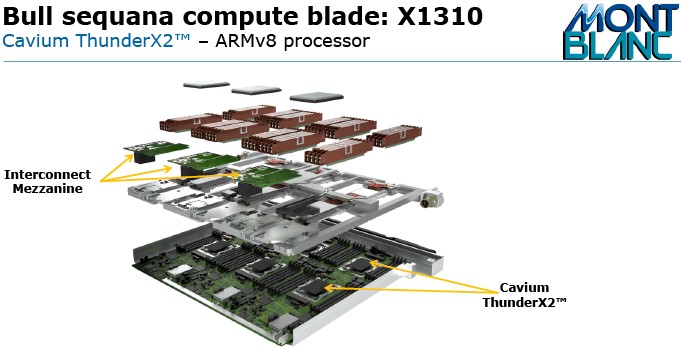
A fourth blade is now in the works thanks to the Mont Blanc 3 project and called the X1310, and as you might expect, it will have three pairs of the ThunderX2 processors on it. Mont Blanc 3 will use EDR InfiniBand on the mezzanine interconnect, which runs at 100 Gb/sec. (You would not expect Mont Blanc systems to use either Intel Omni-Path or Bull BXI interconnects, but nothing restricts this.)
The precise configuration of the Mont Blanc 3 system has not been determined yet, but Panziera says that it is a relatively small budget that is being set aside for the prototype, but it should have somewhere between 50 and 100 nodes of compute. If you do the math on that, and assuming that the top-end ThunderX2 with 54 cores will be used, that is somewhere between 5,000 and 10,000 cores.
“That size is what you need to demonstrate HPC applications,” says Panziera. “And, again, we expect this to be at the performance level of what you could get with an Intel Skylake Xeon or an AMD “Naples” Opteron. We think that for certain HPC applications ThunderX2 will be at that level – and sometimes, better.”
The current rollout plan for Mont Blanc 3 is to show a prototype at the International Super Computing (ISC 2017) conference in Frankfort in June, with Mont Blanc 3 being built out in the early fall. Panziera says that even though Atos has not committed to making the ThunderX2 variant of Sequana a commercial product yet, it already has two customers interested in buying them and these could be announced by the Super Computing (SC17) conference in November. It is a fair bet that Atos will indeed commercialize the ThunderX2 blades, having made the engineering investment on the hardware. But it really comes down to the maturity of the HPC software stack on ThunderX2 at this point – something that both ARM Holdings and Cavium are working on through the OpenHPC project.




Be the first to comment