

At this point in the history of datacenter systems, there can be no higher praise than to be chosen by Nvidia as a component supplier for its AI systems.
Which is why upstart interconnect chip maker Astera Labs, which is taking on the likes of Broadcom and Marvell for PCI-Express switches, PCI-Express retimers, and CXL memory controllers, was quite pleased with itself when Nvidia gave its blessing to have upcoming server nodes using “Blackwell” GPU accelerators uses its PCI-Express 6.0 switches and retimers to link X86 GPUs to its Blackwell GPUs and in some cases network interface cards and storage as well.
The MGX is a set of server reference designs that comprise the basic building blocks of Nvidia’s own AI beasts and the clones of them that OEMs and ODMs create so they can get a piece of the action.
At the GPU Technical Conference 2025 last week, Astera Labs did two things. First, it demonstrated the interoperability of its “Scorpio” P-Series PCI-Express 6.0 fabric switches and “Aries” PCI-Express 6.0 retimers with Nvidia’s “Hopper” H100 and H200 GPUs as well as various Blackwell B100 and B200 GPUs used in HGX setups (the familiar two CPU by eight GPU designs that are now called HGX NVL8 for Hoppers and DGX NVL16 for Blackwells. Second, Astera was showing off an inference server designed by ODM server maker Wistron that was based on Hopper GPUs and that used its switches and retimers to link components together.
It is not at all clear where Nvidia itself is using Astera chips in its systems, and we are really just using this announcement as an opportunity to look into what Astera is offering, but Andrew Bell, vice president of hardware engineering at Nvidia did say in a statement that the Scorpio switches integrated with the “Blackwell-based MGX platform,” so there you have it. The Aries retimers, which are based on DSPs were not mentioned by name, but if you need to extend a PCI-Express 5.0 or 6.0 link to space components out a bit, you need these things, too.
Conceptually, this is how it all looks:

In the center of that chart above, the fabric can be any PCI-Express switch, but Astera would no doubt prefer it to be own of its own Scorpio switches, which it shows as well. Using switches and retimers from two different vendors is probably asking for trouble.
As you can see, you can use the retimers to link a GPU to a network or storage fabric as well as to a different PCI-Express fabric that is used to lash the GPUs directly to each other, much as Nvidia does with NVLink ports and NVSwitch switches. At the moment, there is not memory addressing across this PCI-Express fabric for the GPU accelerators, but that is what the Ultra Accelerator Link (UALink) effort being spearheaded by AMD, Broadcom, Cisco Systems, Google, Hewlett Packard Enterprise, Intel, Meta Platforms, and Microsoft is all about.
While the Scorpio P-Series switches are used to link CPUs to GPUs, network interfaces, and storage, there is another variant of the Scorpio switch called the X-Series that is used to create a mesh of GPUs much as Nvidia’s NVSwitch does – obviously with a lot less bandwidth. This X-Series chip requires a custom engagement, and as you might expect, Astera was definitely not talking about this chip at GTC 2025.
Both the P-Series and the X-Series switches are backwards compatible with devices all the way back to PCI-Express 1.0.
Here is what Astera has been testing as far as PCI-Express 6.0 goes with Nvidia:

In this case, it is a PCI-Express 6.0 x16 link that is hooking an Aries retimer to a Blackwell GPU to extend the range of the PCI-Express link. The Scorpio P-Series switch in the box links to an Intel Xeon 5.0 processor and an Nvidia ConnectX-7 network interface stepping down to PCI-Express 5.0. A Micron Technology flash drive uses a single x1 lane running at PCI-Express 6.0 speed for storage. The Scorpio switch has 64 lanes of PCI-Express 6.0 signaling, and this setup uses 49 of those lanes, 32 of them running at the PCI-Express 5.0 half speed.
The Scorpio P-Series switch started sampling in September 2024 and its production is ramping now.
The machine that Astera was showing with ODM partner Wistron is an implementation of Nvidia’s MGX H100/H200 NVL inference server. The MGX lineup of modular machine was unveiled in May 2023, and the idea is to apply GPU acceleration to different kinds of workloads with form factors that are fit for purpose.
Here is what the MGX inference server looks like conceptually:

This is a 4U rack enclosure with a two socket X86 server in the back as the system host with PCI-Express switches to link out to two BlueField 3 DPUs (in the front on the right) and eight H100 or H200 PCI-Express 5.0 GPUs (in the front eating up most of the space). There is no NVSwitch memory interconnect, but there are NVLink memory ports on each GPU card and bridges can be used to link two or four adjacent GPUs in a shared memory configuration for sharing memory and calculation against that larger memory.
There are configurations of this MGX reference architecture that have one BlueField 3 DPU and four ConnectX-7 SmartNICs one for each pair of GPUs.
Here are the schematics of An MGX inference system that has two GPUs and one NIC per Scorpio switch:
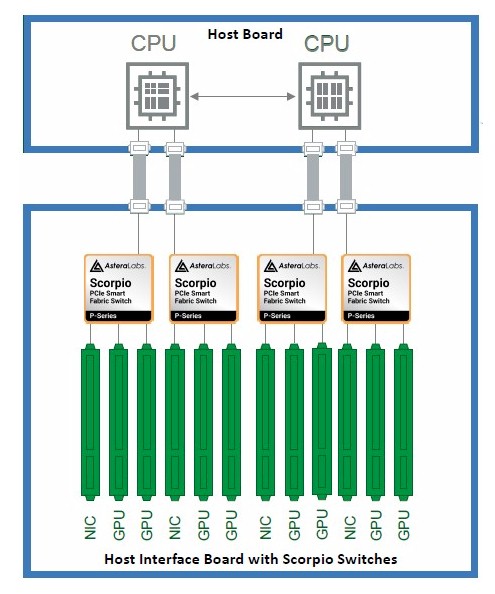
Each pair of GPUs, which are linked by NVLink bridges, has a ConnectX-7 NIC that they share with the outside world and that they talk to over the Scorpio P-Series switch. The pair of GPUs could also communicate over that Scorpio switch, we presume, at PCI-Express 6.0 speeds, which come to 256 GB/sec for x16 lanes if the GPUs can speak 6.0, and only 128 GB/sec if they only speak 5.0.
How much bandwidth you need between the host CPUs and the GPUs, and what level of NVLink NUMA – NVL2 or NVL4 – depends on the kind of AI you are doing.
One of the important things about this MGX inference server design is that it is modular. (Hence the Modular GPU in the MGX name – we are not sure what the X stands for, but it is probably not a kiss or the defensive players on a football team. . . .)
The host compute and memory board in the back can be upgraded independently of the GPU/NIC/DPU board in the front. So, for instance, if you use Scorpio P-Series PCI-Express 6.0 switches in the GPU compute board, then you can run it in PCI-Express 5.0 mode for now and link to any X86 or Arm server node now and swap that out with a new server card with PCI-Express 6.0 slots when such processors come to market. And if you have older Hopper GPUs with PCI-Express 5.0 x16 slots today, you can use them in this MGX design today and swap in new Blackwell PCI-Express 6.0 GPUs at some future time.
Here is what the actual xWing inference server GPU system board looks like from Wistron:

This design has two GPUs per Scorpio switch and a single slot of a NIC on the left side of the board.
None of the MGX inference server designs are going to be able to do inference for GenAI models with trillions of parameters. But they are the right size for a lot of AI inference workloads.

Nvidia Unifies AI Compute With “Ampere” GPU
The in-person GPU Technical Conference held annually in San Jose may have been canceled in March thanks to the coronavirus pandemic, but behind the scenes Nvidia kept on pace with the rollout of its much-awaited “Ampere” GA100 GPU, which is finally being unveiled today. All of the feeds and speeds …

Nvidia Datacenter Revenues Still Booming, “Blackwell” Platforms On Track
We have said it before, and we will say it again as everyone is chewing on the financial results that Nvidia just turned in for its third quarter of fiscal 2025 ended in October. Nvidia does not have to be in any hurry to deliver its “Blackwell” GPU platforms, which …
The Separate But Equal AI Realms Of China And The US
China has lots of coal but it does not have a lot of GPUs or other kinds of tensor and vector math accelerators appropriate for HPC and AI. And so as it has done with exascale-class HPC supercomputers, it is going to trade density and power efficiency for scale and …
“we are not sure what the X stands for”
I guess that’s the Elon MuX edition.
HA!
In the two pictures of the 4U server with 8 GPUs and a pair of DPUs the cards are upside down.
Do they do negative or imaginary flops then?
Quantum perhaps?