

Fujitsu has given us a peek at the future A64FX Arm server processor that it has forged for the future “Post-K” supercomputer that is being built by the Japanese government for the RIKEN laboratory, arguably the hotbed of HPC in the Land of the Rising Sun. Now, Fujitsu is revealing some details on the third generation of its Torus Fusion, or Tofu, interconnect for lashing together those Arm server nodes into a powerful, exascale class machine that will come to market sometime in 2021.
The Post-K system is being funded with $910 million through the Flagship 2020 project and was started back in 2014, two years after the “Project Keisuko” K supercomputer and the original Tofu interconnect went into production. After six years of being in the field, the K system, which cost $1.2 billion to develop and manufacture, is still one of the most efficient systems in terms of network and computational efficiency on a wide variety of workloads. The Post-K machine has to not only support traditional HPC simulation and modeling workloads, but must also support a certain amount of machine learning and data analytics workloads while also scaling to offer more than 100X the performance of the original K machine on applications. Some of the changes to the third generation of the Tofu 6D mesh/torus network, which is now being called Tofu D, appear to be aimed at this wider variety of workloads and to offering much greater node scalability than was available with Tofu 1 or Tofu 2.
Two years ago, Fujitsu and RIKEN made a lot of noise when they announced the Post-K machine would be based on an Arm architecture. We talked about the prototype of the Post-K system back in June in the wake of the ISC18 supercomputing conference in Germany, which was around the same time as when Fujitsu was showing off the prototype machine at a forum in Japan. Back then, we learned a bit about the 64-bit Arm processor, which has special vector instructions created in conjunction by Arm Holdings and Fujitsu and available for others to implement if they so choose, and we also discovered that the Post-K chip would have a single interconnect interface on the die that was labeled Tofu 3.
This week, at the IEEE Cluster 2018 conference, researchers working at the Next Generation Technical Computing Unit and the AI Platform Business Unit at Fujitsu presented the architecture of the Tofu D interconnect and also published a companion paper on the setup. It is the first look that Fujitsu has given of Tofu D. It is reasonable to expect that an exascale machine would require very high bandwidth – something on the order of 200 Gb/sec or even 400 Gb/sec interconnects with lanes running at 50 GHz or even 100 GHz – but oddly enough the Tofu D interconnect will only feature a modest 8.8 percent increase in clock speed of the communications circuits, yielding a data rate per lane of 28 Gb/sec compared to 25.8 Gb/sec for the Tofu 2 interconnect but still 4.5X more oomph per lane than the original Tofu interconnect.
The number of lanes coming out of the Tofu interconnect is intimately related to the number of channels coming out of main memory in the processor complex, which is one of the secrets of the outstanding performance that the K supercomputer and its successors in the PrimePower FX10 and FX100 commercial supercomputers made by Fujitsu deliver on real world applications. Take a look:
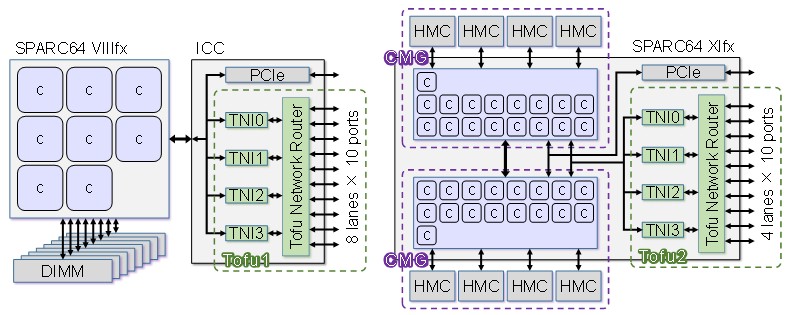
With the K supercomputer, the “Venus” Sparc64-VIIIfx processor had eight cores and eight memory channels running out to DDR3 DRAM memory. The Tofu 1 network router – that is what it really is, as opposed to a simple network interface card – was implemented as an external interconnect controller chip that had four network interfaces and a total of ten ports with 8 lanes each for a total of 80 signal lanes. (The diagram above does a bad job explaining this.) With a data rate per lane of 6.25 Gb/sec, the total link bandwidth across the Tofu1 network interface was 5 GB/sec and with four interfaces, that gave a total injection bandwidth of 20 GB/sec per node. The idea was to keep that DRAM main memory fed.
With Tofu 2, which was available in the PrimeHPC FX100 systems, everything got cranked up a bunch of notches, but oddly enough, the number of signaling lanes on the Tofu interconnect went down. The PrimeHPC FX100 systems were based on the 32-core Sparc64-XIfx processor, as we have explained in detail here. The Tofu 2 router was brought onto the chip, which cut down on a lot of latencies, and at the same time the core complex on the chip was split into two Core Memory Groups, or CMGs, each sharing four Tofu network interfaces that split across them on the internal bus of the chip. Each of the core groups had four Hybrid Memory Cube (HMC) stacked memory interfaces, so once again, you had a Tofu network interface for each memory bank, albeit they were shared across the CMGs. Here’s the important architectural bit: The Sparc64-XIfx chip had HMC memory stacked eight chips high and had four Tofu network interfaces to attack those stacks.
The signaling rate on Tofu 2 was jacked way up to 25 GHz, but the lanes were can back to 40 to match the reduction in memory ports on the chip. The net was that the Tofu 2 link bandwidth went up to 12.5 GB/sec, a factor of 2.5X increase over Tofu 1, which may not have precisely match the quadrupling in cores but it was as close as Fujitsu could get it within a tight thermal envelope. The Tofu 2 interconnect had ten ports, moving in both directions, and that yielded 125 GB/sec into and out of the chip and an injection bandwidth of 50 GB/sec per processor, a factor of 2.25X larger than Tofu 1 in the K system.
(A little aside: The physical coding sublayer, or PCS, of the Tofu 2 interconnect was based on 100 Gb/sec Ethernet using 25 GHz signaling. Fujitsu did not start from scratch. We think that Tofu 1 borrowed heavily from InfiniBand, which was Fujitsu’s preferred interconnect in the late 2000s, but we can’t prove it. We do know that Fujitsu used to have its own InfiniBand adapters and switches back in the day with the PrimeHPC FX1 line that started shipping in 2009.)
Now, let’s take a look at how Tofu D is being implemented on the A64FX processor in the Post-K system, looking at Tofu 2 and Tofu D side by side:
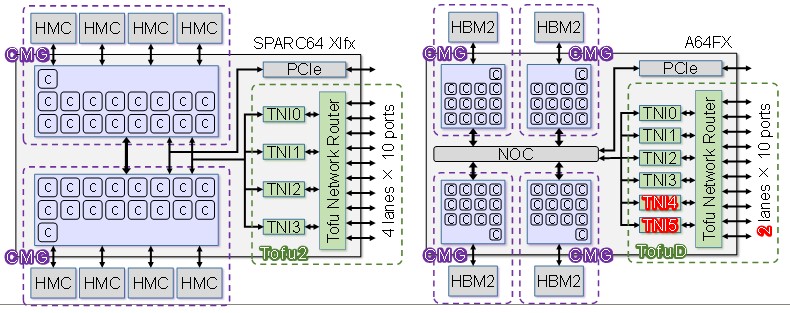
With the A64FX and its Tofu D interconnect, there are going to be four core groups, each with 12 worker cores and one helper core. (We think that there are three more latent cores in each group that are not activated because Fujitsu expects about that dud rate using the 7 nanometer processes from Taiwan Semiconductor Manufacturing Corp, its foundry.) The CMGs are all linked to each other over a ring bus, for a total of 48 worker cores, and the Tofu network interfaces hook into that same bus as a group and on the same die. Each processor has its own High Bandwidth Memory (HBM2) memory, which is stacked four chips high instead of eight with the HMC, and that means the number of off chip channels to memory were cut in half. Thus, Fujitsu could go to the other side of the chip with the Tofu interconnect and once again cut the number of lanes in half to 20.
Here’s the interesting bit. To better balance out the way these 20 lanes, which run at 28 GHz, operate, Fujitsu added two more network interfaces for a total of six. With fewer lanes per port and only a modest speed increase, the link bandwidth per port actually fell by 45.6 percent to 6.8 GB/sec, which is only 36 percent higher than the Tofu 1 interconnect used in the K machine. But because there are 50 percent more network interfaces with Tofu D compared to either Tofu 1 or Tofu 2, the injection bandwidth comes in at 40.8 percent – twice that of Tofu 1 and 81.6 percent that of Tofu 2.
That is a good tradeoff and yields more balanced performance between the compute and memory complexes and the network; we think that the Post-K machine will have well north of 300,000 nodes, and it is therefore going to also have to take the power down in the network while extending its scalability, which is why Fujitsu did not go to 50 GHz or 100 GHz lane signaling as the Ethernet and InfiniBand crowd are. The D in Tofu D is has triple meaning: It will be a dual rail network, rather than single rail like Tofu 1 and Tofu 2; it is all about integrating more network resources in a smaller node to increase the density of the overall Post-K system; and there is dynamic packet slicing on the Tofu protocol to provide more fault resilience.
The K supercomputer and its follow-ons in the PrimeHPC FX100 line as well as the Post-K machine seek to have high injection bandwidth – which expresses how fast a near node in the cluster can jam data into a node or pull it out – as opposed to focusing on bi-section bandwidth – which expresses how a data exchange across the whole network would perform. Here is a neat table showing how K stacked up against relatively current supercomputers:
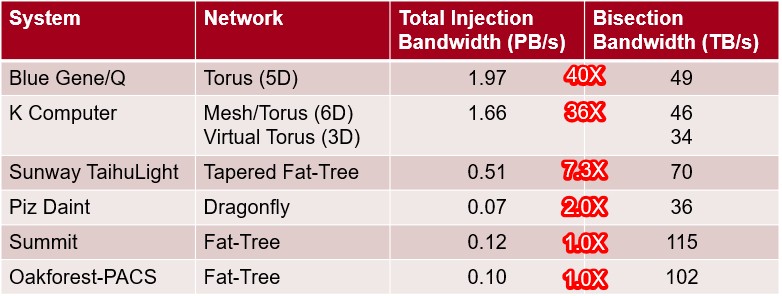
Some of these machines have very low injection bandwidth relative to their bi-section bandwidth, and Fujitsu seems to be in the camp, as IBM was with BlueGene/Q, that the injection bandwidth should be a lot higher than the bi-section bandwidth, not on the same order of magnitude. Without knowing how large the Post-K machine will be, it is hard to say what the bi-section bandwidth will be, and it will be interesting to see how this philosophy by Fujitsu might change a little, heading more toward the center of this pack.
Cutting Into The Tofu D
The Tofu family of interconnects have implemented various forms of offload from the servers as well as latency reduction techniques to get balanced performance out of the network. Fujitsu did not divulge the port-to-port hop latency that is commonly quoted for switches, but it has provided some benchmark results to show how these features have cut the time for nodes to communicate and to get something pretty close to peak throughput on the network doing real work.
Not only does the Tofu D interconnect have more network interfaces on the router, it has more barrier channels (which are the offload engines in the router for collective communication) as well as more barrier gates (which intakes two communication inputs and outputs two different communication outputs). The Tofu 1 and Tofu 2 chips only had a Tofu barrier in one of the network interfaces,
Here are how the resources stack up across the Tofu generations:
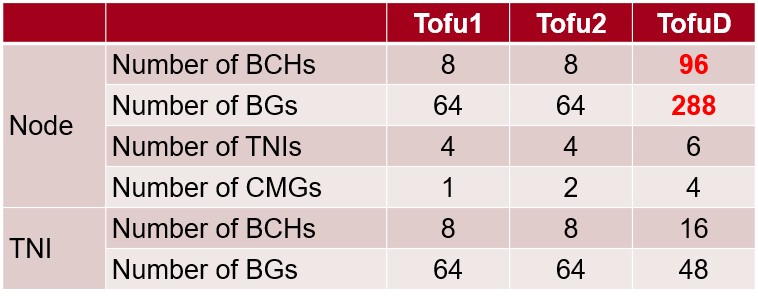
The Tofu network interface circuits allow for remote direct memory access, as is common in InfiniBand and Ethernet with RoCE protocols, and specifically allows for a CPU in the cluster to directly process memory on a remote node as well as to do Put and Get operations into and out of remote memories. The RDMA features also allow for a node to reach out an modify a shared variable in remote nodes. The key innovation for Tofu 1 was a feature called direct descriptor, which feeds communication commands from the CPU registers to cut latency. On a set of Put benchmark tests using 8 byte data chunks, the direct descriptor chopped latency by 240 nanoseconds, from 1,150 nanoseconds down to 910 nanoseconds. With Tofu 2, a cache injection booster, which takes data from the network and puts it directing into the cache on the processor, reduced this 8 byte Put operation by another 200 nanoseconds to 710 nanoseconds. Other tweaks with the Tofu D will reduce that Put operation latency to 540 nanoseconds on a CMG that is far from the network interface on the chip and to 490 nanoseconds to a CMG that is near to it.
This chart shows all of the tweaks that Fujitsu has done to bring down the latency with each Tofu generation:
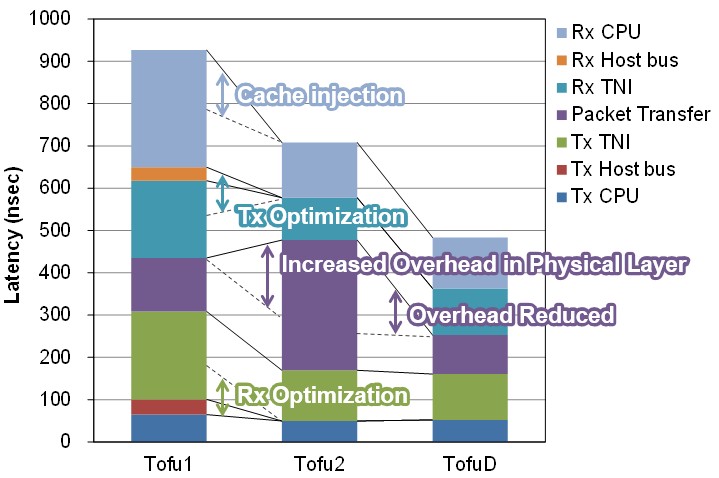
The Tofu interconnect has been very efficient, and it continues to be with the Tofu D based on early benchmark results.
On a one-way Put transfer with message sizes over 1 MB, the Tofu 1 could do a node to node transfer on the same system board at 4.76 GB/sec, which was 95 percent of peak throughput; the Tofu 2 could do 11.46 GB/sec, which was 92 percent of peak; and the Tofu D will be able to do 6.35 GB/sec, which is 93 percent of peak. The injection rates are also close to peak, according to Fujitsu. The Tofu 1 had some bottlenecks in the port that was used to link the Tofu 1 chip with the Sparc64-VIIIfx processor, and the injection rate for a nearest neighbor Put operation only came in a 15 GB/sec, which was 77 percent of peak. With a tweaked Tofu 1 used in the PrimeHPC FX10 commercial systems based on the K supercomputer design was able to get 17.6 GB/sec, which was 88 percent of peak. The Tofu 2 interconnect used in the PrimeHPC FX100 systems, which was integrated onto the Sparc64-XIfx processor, was able to drive 45.8 GB/sec, or 92 percent of peak. And finally, on early tests on the Tofu D interconnect, the nearest neighbor put test shows an injection rate of 38.1 GB/sec, which is 93 percent of peak. As we have pointed out, the Tofu D had nearly the same injection rate of Tofu 2, but will presumably burn a lot less juice because it has far fewer lanes in the router and doesn’t clock all that much higher. And that means Fujitsu can scale up the Post-K system with more nodes to add more compute.


With Fugaku Supercomputer Installed, RIKEN Takes On Coronavirus
Supercomputers are designed for a number of big jobs that can only be done by massively powerful machinery, and one of those jobs has been the modeling of chemical compounds and biological systems, often in concert to model diseases and to help find cures for them. The “Fugaku” exascale-ish system …

Isambard 2 Is About Driving Technology Diversity
It’s been just more than a decade since Arm executives began to talk about bringing the company’s system-on-a-chip (SoC) architecture, which has long been the dominant design for processors found in billions of smartphones and other mobile device, into the datacenter. They boasted that within years they would be chipping …

Fujitsu Cloud Service to Put Fugaku Supercomputer in Reach
For those looking to try out Fujitsu’s Arm-based PRIMEHPC FX1000 system, the company is opening up the same capabilities via its own cloud service. Access to the Fujitsu A64X-based systems, which are at the heart of the top-ranked Fugaku supercomputer in Japan, will begin in October in-country, with global rollout …
Be the first to comment