

In any chip design, the devil – and the angel – is always in the details. AMD has been burned by some architectural choices it has made with Opteron processors in the past, where assumptions about how code might exploit the hardware did not pan out as planned. The company seemed intent on not repeating mistakes with the follow-ons with the venerable Opteron processors, which had excellent designs at first, with the second generation of Epyc server chips.
Time – and customers – will tell, but this derivative kicker implemented in a much-improved multichip design with more advanced etching processes for the cores seems to be hitting the server market with precisely what it wants when it needs it most. And this bodes well for the future of the Epyc chips as an alternative to current and future Xeon chips from Intel.
We have been itching to get into the architectural details of the new “Rome” Epyc server chips, which we covered at the launch last week with the basic feeds, speeds, slots, watts, and pricing. Now, let’s jump into the architectural details of the Rome processors with Mike Clark, lead architect of the Zen cores and a corporate fellow at AMD as well. In many ways, Rome, with its Zen 2 core and mixed process multichip module design, is the processor that AMD must wish it could have put into the field two years ago. Everything about it is better, and it all starts with the etching of the cores and their associated L1 and L2 caches in the 7 nanometer processes from fab partner Taiwan Semiconductor Manufacturing Corp.
“It’s nice to be in the lead in process technology,” Clark said with a wry laugh, adding that Intel and AMD would be leapfrogging each other in the coming years so this victory would not be permanent even if it is undeniable and strategic right now. “That 7 nanometer process drives significant improvements. Interestingly, it gives us 2X the transistor density, but the frequency actually took a lot of work with TSMC and the tool guys. Typically, when you go into a new technology, the frequency goes down, you lose Vmax, and it takes some time to get that frequency back up. But we were able to work with them to create a really good frequency story for 7 nanometers and hold the power the same. And, of course, if you look at the transistors the other way, you can get half the power at the same performance level.”
Instructions per clock, or IPC, is also a big part of the Rome architecture. Jumping from the “Excavator” cores used in the last Opterons from several years ago to the Zen 1 cores used in the “Naples” Epyc chips, AMD was able to increase IPC by 50 percent on a constant clock basis, which is a huge jump. And akin to what Arm is promising with its “Ares” Neoverse designs. Arm is actually projecting a 60 percent increase in IPC, but to be fair, neither the Excavator Opterons nor the Cortex-A72 were very strong in IPC to begin with – at least not compared to a Xeon core from Intel. Now, AMD and Arm are catching up, and with the Zen 2 cores used in Rome, AMD is adding another 15 percent more IPC, clock for clock. Intel’s generational IPC improvements have been between 5 percent and 10 percent, or about half that rate on average.
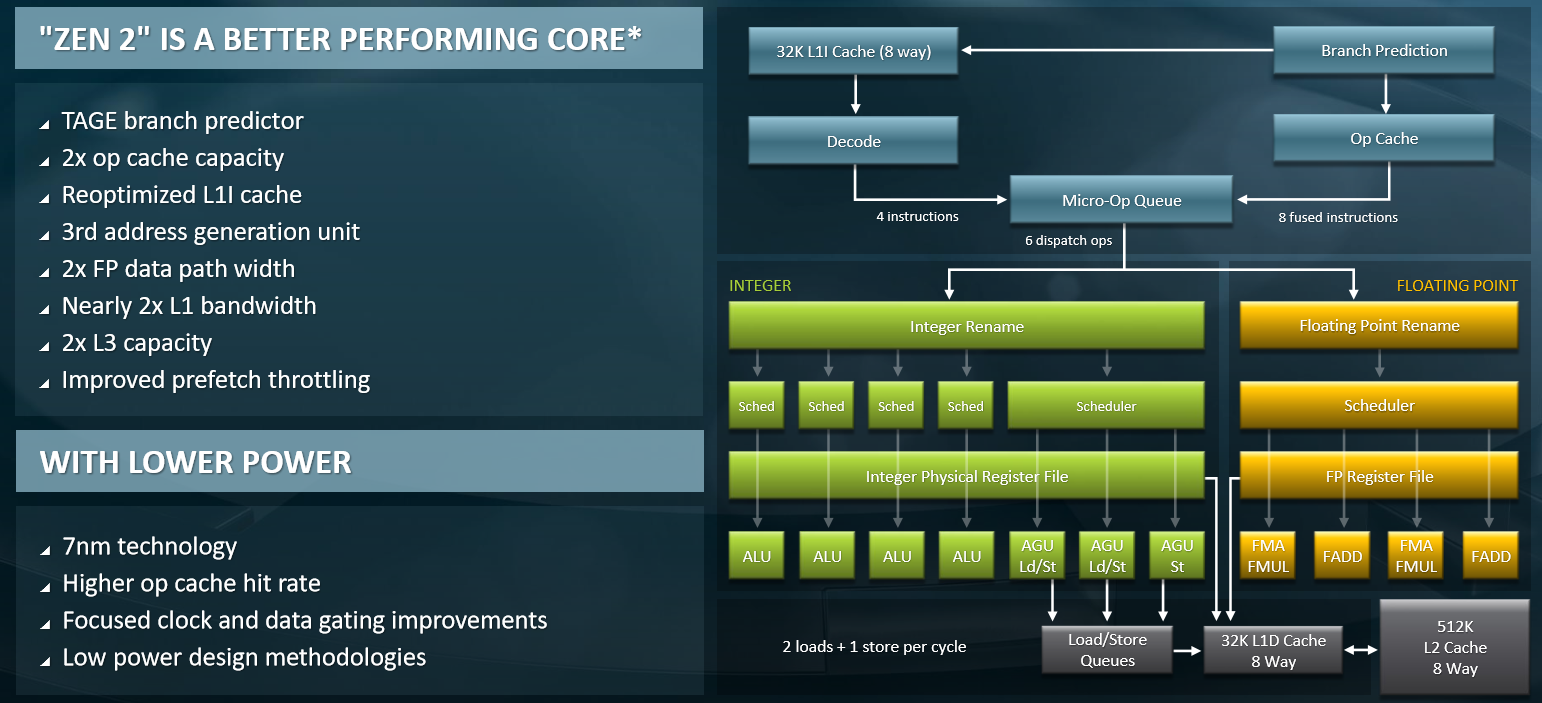
Clark said that when IPC goes up, chip architects often pay for that with higher power consumption, but that with the Zen 2 core design the goal was to keep it power neutral compared to Zen 1 in Naples. As it turns out, the Rome engineers tightened the screws and were able to reduce power consumption of the core by 10 percent, above and beyond what was attained through the shrink in process from 14 nanometers with Naples to the 7 nanometers used for the Zen 2 core complexes in Rome. One the big ways this was accomplished was by doubling the op cache in the core, which helped save power and also increased performance.
In fact, AMD actually shrank the L1 instruction cache on each Zen 2 core, from 64 KB back to 32 KB, and gave that transistor area back to the op and branch prediction units and also used some of it to add a third address generation unit. The associativity of the L1 data and instruction caches (both at 32 KB) was doubled to eight-way, and AMD doubled the floating point data path width and then doubled up the L1 cache bandwidth to keep up with it. (Clark said that an eight-way associative L1 cache at 64 KB was going to eat far too much power, and with 64 cores, that was going to be a big problem.) The L3 cache was doubled up on each chiplet to 16 MB a pop, and with twice as many chiplets on the package that is four times the L3 cache capacity, at 256 MB, as what was in the Naples processor. It is not precisely doubling of everything, but an attempt to get things into a better balance as the core count and chiplet count doubled up. This includes branch prediction, instruction fetching, and instruction decode units, as you can see here:
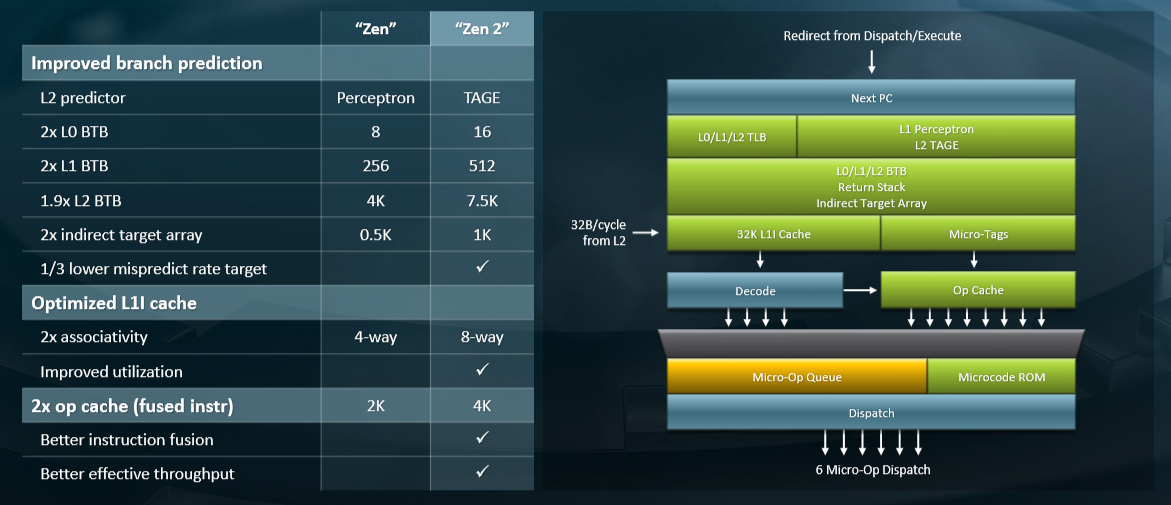
“We like features that improve both power and performance,” Clark elaborated. “Being on the right path more often is important because the worst use of power is executing instructions that you are just going to throw away. We are not throwing work away after we figure out dynamically that we were wrong to do it. This definitely burns more power on the front end, but it pays dividends on the back end.”
That brings us to the integer and floating point instruction units in the Zen 2 cores.
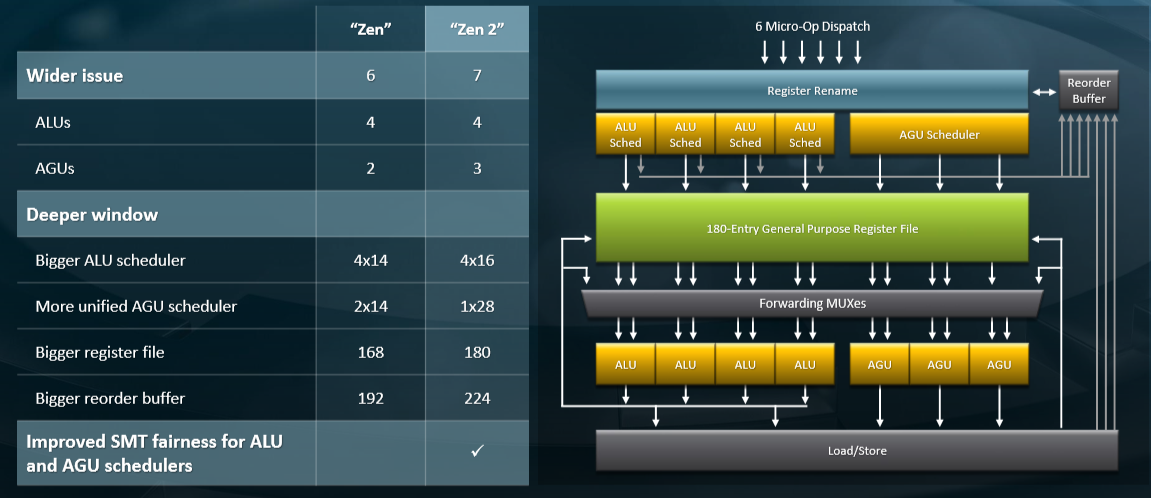
On the integer front, the arithmetic logic unit (ALU) count remains the same at four, but the address generation unit (AGU) count in the Zen 2 core is boosted by one to a total of three. The schedulers for the ALUs and AGUs are both improved, and the register file and reorder buffers are both boosted in size, too. And the fairness of the algorithms controlling simultaneous multithreading (SMT) with regards to the ALUs and AGUs has been tweaked as well to deal with imbalances in the Zen 1 design.
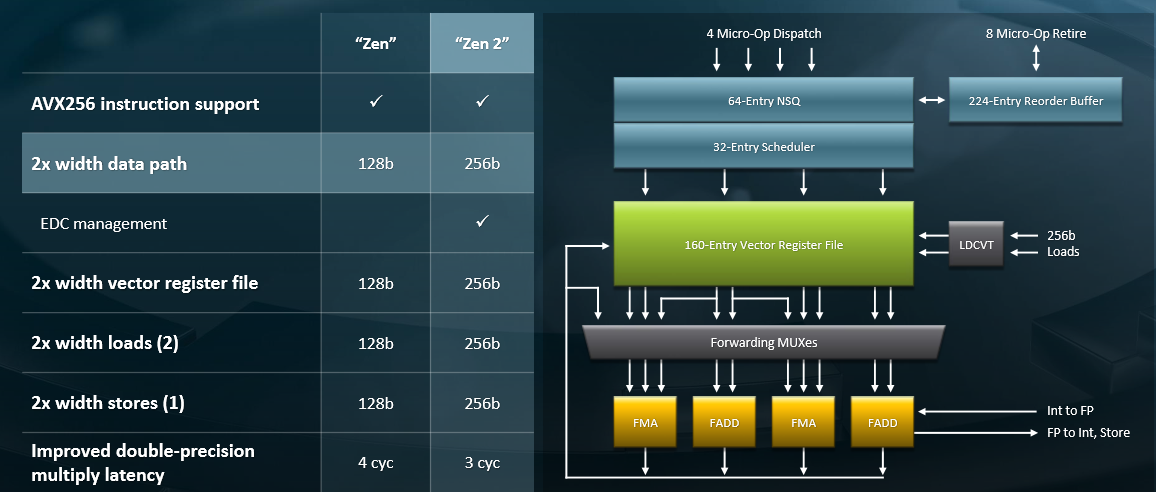
Intel, of course, implemented a very elegant 512-bit wide AVX-512 vector unit in the “Knights Landing” Xeon Phi processors four years ago, and brought a variant of it – some would say a less elegant variant because it is harder to keep it fed due to the way it was implemented – to the “Skylake” Xeon SP processors and that has been brought forward essentially unchanged with the current “Cascade Lake” Xeon SP chips, excepting the ability to cram half precision instructions through it for machine learning inference workloads.
Clark said that AMD was looking at possibly doing 512-bit vectors in future Epyc chips, but at this point was not convinced that just adding wider vectors was the best way to use up the transistor budget. For one thing, Clark added that there are still a lot of floating point routines that are not parallelizable to 512 bits – and sometimes not even to 256 bits or 128 bits, for that matter – so it is a question of when moving to 512 bits on the vector engines in the Epyc line makes sense. AMD will probably be a fast follower and do something akin to the DLBoost machine learning inference instructions, we reckon. Perhaps that capability is already in the architecture, waiting to be activated at some future date when the software stack is ready for it.
With the Zen 1 core, which had a pair of 128 bit vectors, it took two operations to do an AVX-256 instruction, but Zen 2 can run that AVX-256 instruction in one clock; this obviously takes a lot less power. A double precision multiply took four cycles on Zen 1 and it takes only three cycles on Zen 2, which improves the throughput and power efficiency of the floating point units. (IPC figures cited above are for integer instructions, not floating point ones.)
As for the caches feeding the Zen 2 cores, all of the structures supporting the caches are bigger and provide more throughput, driving up that IPC:
Here’s what the Zen 2 CPU complex and cache hierarchy looks like:
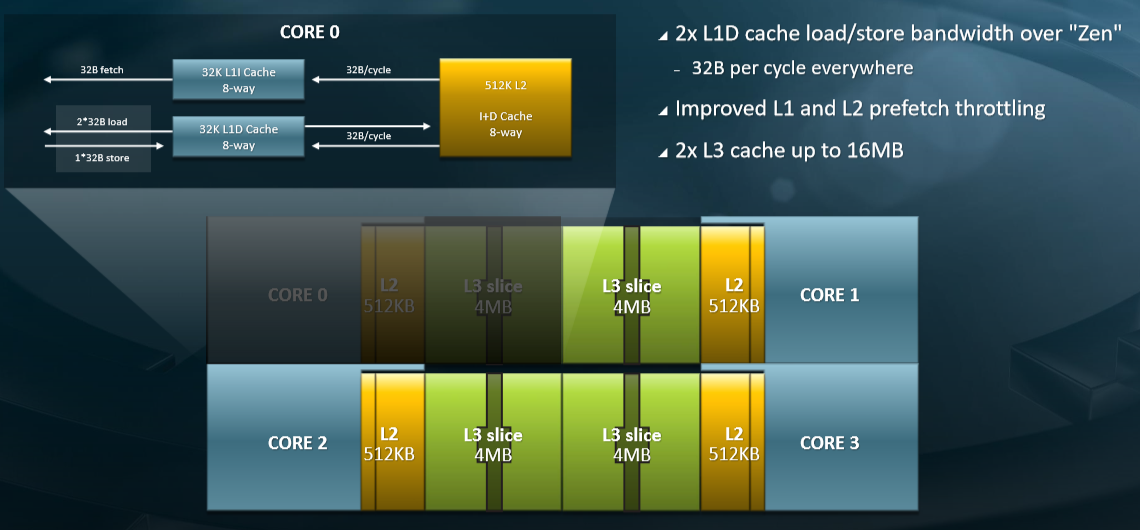
That increased L2 cache in each core and L3 caches across the cores are a key to allowing that potential IPC in the Zen 2 core to be actualized, because as Clark correctly puts it: “The best way to reduce the latency to memory is to not go there in the first place.”
Add it all up, and you put eight CPU complexes and the I/O and memory hub – a total of nine chips – onto the package to make a top-end Rome Epyc. Lower bin SKUs have fewer core chiplets on the package and sometimes fewer cores activated on each die present, and this yields the breadth of the Rome Epyc 7002 series chips, as we detailed last week.
This is a teardown of the Naples and Rome MCMs, which obviously are architected in very different ways:
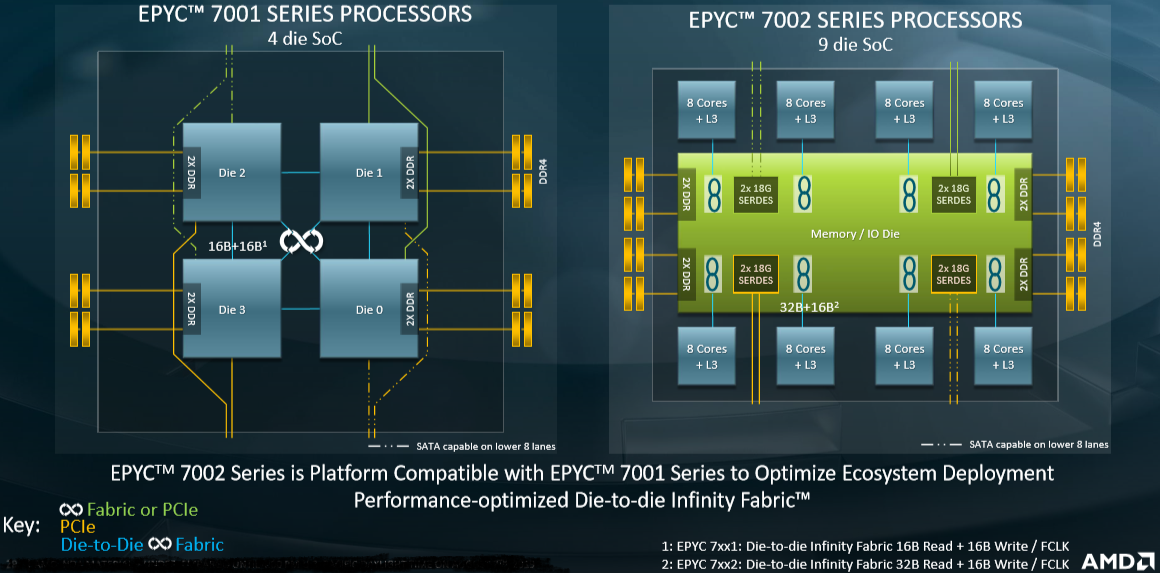
There are some important changes with the second generation Infinity Fabric variant of PCI-Express that is used to link the chiplets in the Naples and Rome sockets, respectively, to each other. The Naples chiplets could do a 16 byte read and a 16 byte write across the Infinity Fabric in one clock – FCLK in the fine print is short for fabric clock – while the Infinity Fabric in the Rome chips can do a 32 byte read and a 16 byte write per fabric clock.
While the Rome chips plug into the same sockets as the Naples chips, the way the elements are lashed together inside of that socket is very different. The memory controllers are moved off the CPU complex chiplets and onto that central hub, which is etched in 14 nanometer processes where it runs better than it would at 7 nanometers because I/O and memory have to push signals off the package and into the motherboard where DRAM and PCI-Express peripherals plug in. There are a total of eight DDR4 memory controllers on this hub chip, the same number in total that were on the Naples complex; both support one DIMM per channel and have two channels per controller, but Rome memory runs slightly faster – 3.2 GHz versus 2.67 GHz – and therefore with all memory slots filled, yields a maximum of 410 GB/sec of peak memory bandwidth per socket. That’s 45 percent higher than the Cascade Lake Xeon SP processor, which has six memory controllers for a total of 282 GB/sec of memory bandwidth running at 2.93 GHz and 21 percent higher than the 340 GB/sec that Naples turns in running that 2.67 GHz DRAM. (Those are ratings for two-socket servers.)
The real big change with the Rome Epycs, and one that is going to have a beneficial effects on performance for a lot of different workloads, is the way NUMA domains are created in the chips and the fewer NUMA hops – distances in the chart below – that is required to move from one part of the processor complex to another. Take a look:
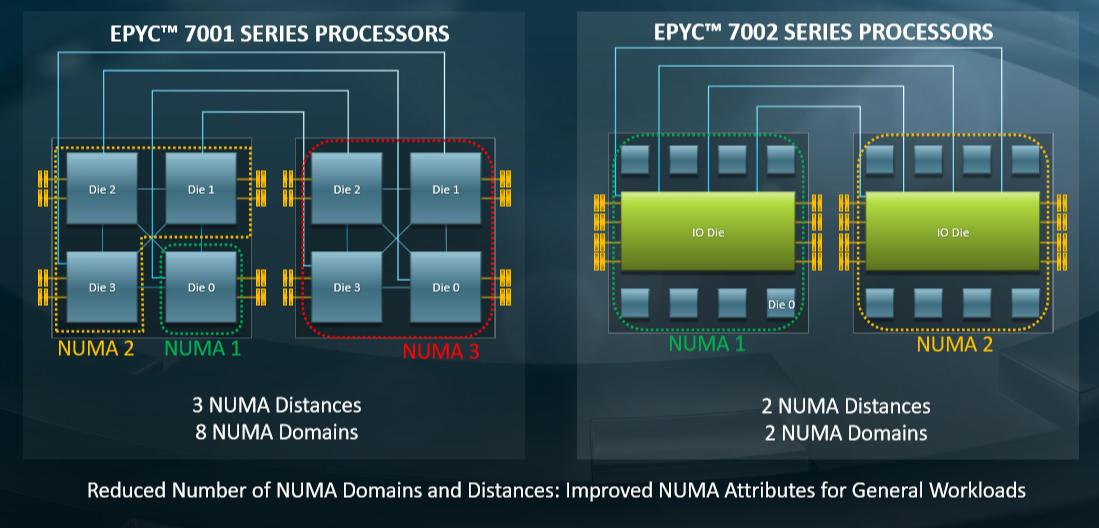
This is basically a NUMA server, with that central hub being a chipset to link the chiplets (sockets in this analogy) together into a baby shared memory system using non-uniform memory access techniques to lash the caches and main memories together.
With the Naples chips, there were three different distances from any one die to another, which is where the memory was hanging. There was one hop to two adjacent dies, and sometimes two hops to the die diagonally across and three to the dies in the second socket in a two socket setup. Now, there are two NUMA domains and only two different distances. It is one hop from one chiplet through the central hub to the memory attached to any processor, and then one other hop across the Infinity Fabric to a second central hub and the memory that hangs off of it. And to simplify matters further, there are only two NUMA domains – one for each Rome complex. This should make Windows Server and Linux both run better on both single-socket and two-socket systems, and Clark said that Windows Server had a bit more trouble on Naples than did Linux the way the NUMA was implemented. The upshot of these changes to the NUMA architecture with Rome is that performance should be better and more even, and across a broader array of workloads to boot.
That I/O and memory controller hub chip also implements the PCI-Express 4.0 lanes that are used to lash peripherals to the system and in the case of two-socket servers, lash a pair of Rome compute complexes to each other.
As with the Naples chips, each Rome chip has 128 lanes of PCI-Express that is configurable in many different ways, as illustrated below:

As with Naples, half of the total PCI lanes are used to implement the NUMA links between two sockets, so both a single-socket and dual-socket Rome has only 128 PCI-Express lanes to serve peripherals. The ones in Rome have twice the bandwidth and can actually drive 100 Gb/sec and 200 Gb/sec adapters, which PCI-Express 3.0 has trouble doing with the former and cannot do with the latter in a normal x8 slot. The lanes can be used singly, are often ganged up in a pair (x2) for storage devices, potentially leaving room for maybe 56 NVM-Express drives plus a high speed network interface card in a Rome system.
Technically, the Naples chip had a single x1 lane separate from all of this for Infinity Fabric control. This x1 lane is also available for other traffic now that there is a central hub. So that means a single-socket Rome server technically has 129 lanes of PCI-Express 4.0 and a two-socket Rome server has 130 lanes. The Intel Xeons only scale down to x4 lanes; they can’t do x2 or x1 lanes, according to Clark. We had not heard this before.
Finally, the Zen 2 cores have some architectural extensions, which are outlined here and which are not being backcast into the Zen 1 cores of the Naples chips:

Next up, we will be taking a look at how AMD stacks up the Rome Epycs against its Xeon rivals and at Intel’s initial and then long-term response to the Rome chips.




Yes and in response to AMD going even wider order superscalar with Zen-2 in Rome to get the IPC higher Intel has widened Their Sunny Cove core designs as well for the client and the server markets but that’s not RTM currently on the server side in any Server SKUs.
So Intel’s Sunny Cove will probably have Zen-3 and Epyc/Malian to contend with and hopefully that’s and even wider order superscalar design than Zen-2 and we can look forward to a wider order superscalar arms race in the x86 market because those clock speed increases are not forthcoming at the 7nm smaller process nodes as easily as they were from the above 28 to 14/older process nodes shrinks of the past.
There is one thing that the process node shrinks are still producing that is scaling relatively well and that’s transistor density increases and that’s good for adding more Instruction Decoders, FP/Int, and Load/store, execution ports as well as larger reorder buffers, TLBs, and larger caches and such. All features that can increase IPC no matter the clock speeds utilized.
Sure going wider order superscalar will use more power if some other metrics like clock speeds not are reduced or the power efficiency of the process node shrink is enough to offset the power budget increase from going wider. Wider order superscalar cores for the mobile market are good news as those designs run at lower clocks anyways and Apple’s and Samsung’s A series and Mongoose M3/M4 designs respectively have Six decoders on the front end compared to AMD’s 4 decoders and Intel’s 5(Sunny cove) but RISC ISA decoders are less complex to implement than CISC decoders.
So it appears that with higher core clocks no longer being as readily available with process node shrinks as it was in the past there is now the impetus for AMD and Intel to have to go wider order superscalar and move more in the IBM Power 8/9/10 direction with some very wide order superscalar offerings in order to get the IPCs higher with with that clock speed increase low hanging fruit non longer there as an easy way to get more performance.