
Arm chip designers who make processors for mobile devices, such as Apple, Samsung, and Qualcomm, that do not have pre-existing server businesses have been skittish about entering the server fray with heftier versions of their Arm chips for datacenter compute.
As far as we know, Apple has never contemplated such a move, and in fact Apple shuttered its XServe system business eight years ago just as it was ramping up its infrastructure in its own datacenters to serve up customers with services and data; Apple is a quiet member of the Open Compute Project, and we suspect that it has tweaked versions of open servers running Intel, and now possibly AMD, X86 server processors in its datacenters.
Samsung, the world’s largest chip maker with a large mobile device and electronics business, formerly the foundry for Apple’s custom Arm chips, and now the foundry for IBM’s Power and System z processors, flirted with entering the Arm server fray seven years ago, but eventually backed off and stuck to mobile and embedded system-on-chips that are really not well suited to anything but the skinniest and highly parallel serving jobs. AWS, which has plenty of need for servers as well as burgeoning Alexa home assistant and Kindle tablet businesses, has gone for it with its first custom ARM server chip, called “Graviton,” that was previewed back in November. AWS has been designing its own Arm co-processors since it bought chip upstart Annapurna Labs four years ago, so it is not starting from scratch by any means.
Neither is chip maker and, importantly, telecommunication equipment provider and server maker Huawei Technologies, which has its own chip design subsidiary, called HiSilicon. The Chinese manufacturing giant has been working with Arm Holdings, the company that creates and maintains the Arm processor architecture, since 2004 and its first big HiSilicon chip was called the K3, which came out in 2009 for Huawei‘s smartphones and which is the predecessor for its current Kirin line of Arm-based smartphone chips.
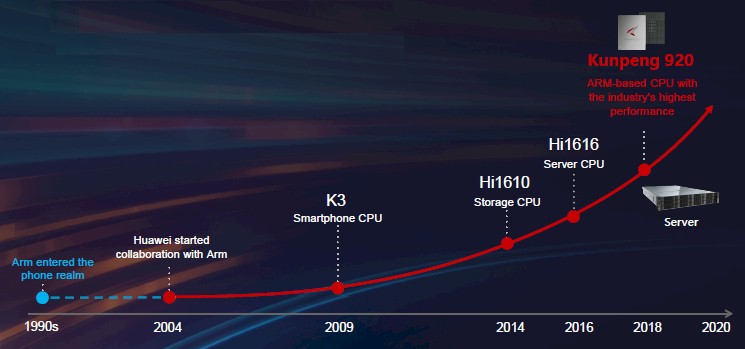
Back in 2015, driven by the demands of its telecommunications customers, Huawei had HiSilicon tweak a version of the Kirin chip to work as a storage controller, and in 2016 the company rolled out a tweaked Kirin chip aimed at relatively lightweight server workloads.
This is precisely the target workloads that Arm server chip upstarts Calxeda, Applied Micro (now Ampere), AMD (which has ceased its Arm development), and Cavium (now part of Marvell) all went after with their initial forays into server processors based on the Arm architecture. Cavium had a pretty beefy ThunderX2 chip, code-named unknown, in the field eventually, and is working on an even beefier “Triton” ThunderX3 processor, which we should see this year. Qualcomm took a leap into Arm servers back in 2014, and, after having an initial test chip that didn’t amount to much, put its “Amberwing” Centriq 2400 into the field in November 2017, we think with egging on and financial backing of Google and Microsoft but no one confirms anything about that. By May 2018, Qualcomm, which had bet heavily on the 10 nanometer node at foundry partner Taiwan Semiconductor Manufacturing Corp, had basically pulled the plug on the operation.
But with the Kunpeng 920 processor that Huawei and HiSilicon unveiled this week, it is going after much heavier workloads and also making it so HiSilicon is not dependent on any vendor for processors and controls a chip where telecom applications can be highly tuned to the infrastructure. (Kunpeng is the Chinese name of a mythical and powerful creature that has aspects of fish and birds – a kind of water dragon, we presume.)
The arguments that Huawei is making to develop its own server processors are much the same ones that we saw from Qualcomm in recent years. Both companies see am explosion in data as networks get more pervasive and applications get richer, and you need a processor with good integer performance to handle this rich media at both the edge and back in the datacenter; and because various kinds of complex analytics and machine learning techniques are rapidly becoming integral to applications, the datacenter and edge processors also need mixed precision floating point math capability as well.
“The future world will be an intelligent world where all things can sense, all things are connected, and all things are intelligent,” explained William Xu, director of the board and chief strategy marketing officer at Huawei, in launching the Kunpeng 920. “There will be massive amounts of information, and computing will be everywhere. Computing will be applied across a broad range of scenarios ranging from vacuum robots to smartphones, smart homes, the Internet of Things, and smart driving. The huge diversity of scenarios will lead to diverse data, including figures, text, photos, videos, images, and structured and unstructured data. Integer computing excels in text processing, storage, and big data analytics while floating point computing excels in scientific computing and other areas.”
Huawei’s prognosticators believe that the amount of new data generated worldwide will grow from 10 ZB (that’s zettabytes, or 1,000 exabytes or 1 million petabytes) in 2018 to 180 ZB by 2025. That’s a factor of 18X increase in new data, and it is roughly an average of 50 percent growth in new data each year and, importantly, results in a cumulative of 510 ZB of new data over the 2018 through 2025 time period. Presuming that people keep data around to chew on, it is no wonder then that OpenAI, which Huawei cited in its presentation, believes that machine learning and other computing related directly to artificial intelligence is growing at 10X per year. Part of this is driven by the rise of machine learning, which we reckon will ultimately represent somewhere on the order of 25 percent 30 percent of the aggregate computing in datacenters (as it does at the hyperscalers today using some rough estimates), and part of it is just the need to chew on ever-larger datasets to get better results on algorithms.
Just like every company has some sort of Web presence after two decades of e-commerce, everyone will have some kind of AI, whether they build it, buy it, or rent it. And as far as Huawei is concerned, the key is that the telecommunications companies, service providers, and cloud builders that it sells gear to are going to see a massive demand for media handling and AI computing, which it hopes to meet with the Kunpeng family of Arm server chips.
But don’t get the wrong idea. Huawei does not think by any stretch of the imagination that its Kirin and Kunpeng processors will alone be able to address all of the computing needs of the edge and the datacenter in the future.
“It is inevitable that the diversity of applications and data will drive diverse computing,” Xu explained. “There is no single computing architecture that can process every type of data in every scenario. We see the coexistence of CPU, DSP, GPU, FPGA, and AI chips. Heterogeneous computing, composed of multiple computing architectures, is the way to the future.”
We could not agree more.
To that end, Huawei has commissioned its HiSilicon subsidiary to create the Da Vinci architecture and the Ascend 310 and 910 processors that use it. The Ascend chips are embedded devices that were created to run machine learning inference. the Ascend 310 offers 8 teraops per second (TOPS) running inference at FP16 and 16 TOPS running it at INT8, all within an 8 watt thermal envelope; it is etched in the same 12 nanometer processes at TSMC that are being used to create the “Volta” GPU accelerator chips from Nvidia. Each Da Vinci core has 4,096 multiply-accumulate (MAC) units for doing matrix math at different precisions and with different data types (floating point or integer), and the architecture is designed to scale from handheld devices all the way up to datacenter accelerators. The Ascend 910 accelerators, which were previewed by Huawei last October, will be etched using 7 nanometer processes at TSMC (the same as the “Rome” Epyc server CPUs and “Navi” GPUs at AMD) and can do 250 TOPS at FP16 and 512 TOPS at INT8 within a 350 watt power envelope.
But this week’s launch from Huawei was about the HiSilicon Kunpeng 920 CPU, which it did not provide very much detailed information about. But here is what we know.

Huawei’s HiSilicon subsidiary is held at arm’s length (pun intended) so that others can buy its chips to use in devices of their own or license the HiSilicon designs to compete against Huawei or other equipment suppliers in some fashion. HiSilicon is an Armv8 license holder, and we presume that these chips are in fact based on the future “Ares” Neoverse platform that Arm rolled out last October along with its three-year roadmap going forward to attack the edge and the datacenter in a better fashion than it has done. The Kunpeng 920 chip is completely homegrown.
“Huawei independently developed the ARM core based on the ARMv8 architecture license for uses cases like data centers, big data, distributed storage, and ARM-native applications,” said Xu. “The ARM core significantly improves processor performance by optimizing branch prediction algorithms, increasing the number of OP units, and improving the memory subsystem architecture.”
Well, having 64 cores running at 2.6 GHz certainly helps, and is clearly enabled by the 7 nanometer shrink. Having eight memory controllers on the chip, as the Kunpeng 920 does, and running the DDR4 memory at 2.93 GHz instead of 2.67 GHz means that the aggregate memory bandwidth on the chip is 1.5 Tb/sec (192 GB/sec), which is 46 percent higher than what Intel can do with the current “Skylake” Xeon SPs.
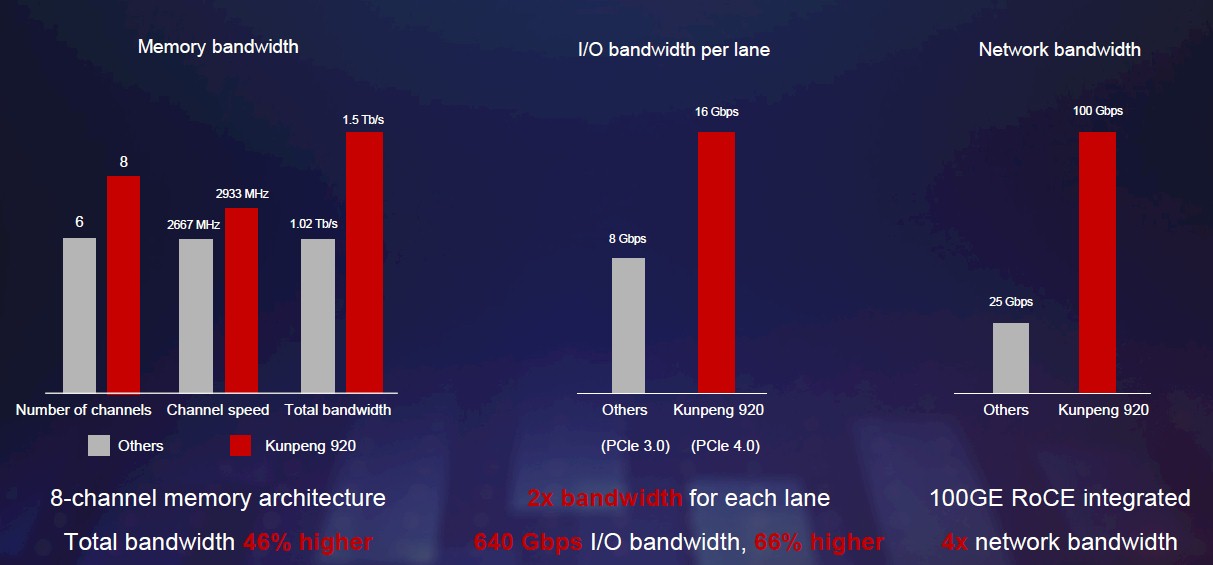
The Kunpeng 920 chip will also have integrated PCI-Express 4.0 controllers, offering double the bandwidth per lane as the PCI-Express 3.0 controllers on the Skylake. Huawei says that the aggregate PCI-Express 4.0 bandwidth coming out of the Kunpeng 920 will be 640 Gb/sec (80 GB/sec), which is 66 percent higher than with mainstream processors sold today. (This is not true of the IBM Power9 chip, which has integrated PCI-Express 4.0 controllers as well as NVLink and Bluelink peripheral ports.) The PCI-Express 4.0 ports will be able to support the CCIX cache coherency protocol that was created and championed by FPGA maker Xilinx and that Arm is weaving into its Neoverse Arm server chip roadmaps.
The Huawei server chip will support an integrated 100 Gb/sec Ethernet controller that supports the RoCE implementation of RDMA. The Kunpeng 920 also has its I/O southbridge chip and SAS storage controller integrated on the die, and will likely support two-way NUMA shared memory as well, just like the Hi1616 predecessor to the Kunpeng 920 did.
As far as we know, this is all being done on a single piece of silicon, not with chiplets for different functions all packaged with an interconnect within one socket. We would love to see a die shot of the Kunpeng 920. These Kunpeng processors will presumably be offered in the TaiShan line of servers that are currently being sold with the Hi1616 chips as their motors.
Add it all up, and based on the SPECint2006 CPU benchmarks running the open source GNU compilers, with a rating of 930 or higher on early lab results, Huawei reckons that the 64-core Kunpeng 920 running at 2.6 GHz can deliver 25 percent better performance than mainstream processor rated at 750. The SPECint2006 numbers do not make any sense to us, after reviewing the SPEC CPU benchmarks. They seem to be a factor of 10X higher than SPECint_2006 and nowhere near as high as for the SPECint_rate_2006 test. It is hard to see what the proper comparison might be. If you take the 25 percent integer performance cited by Xu at face value, the gap between the Kunpeng and the Xeons will no doubt close a bit with the impending “Cascade Lake” and future “Cooper Lake” Xeons, and will close even further with the “Ice Lake” Xeons due next year.

As you can see from the chart above, Huawei is not going to have a big advantage when it comes to floating point math, such as the 64-bit math used on the Linpack test. But for storage and analytics, the processor is said to have advantages, and thanks to tuning, it really shows off well on a benchmark test created from a mobile game application running in cloudy infrastructure.
When this Kunpeng 920 chip starts shipping next year, aside from the specifics of the architecture, the big question will be not who wants to buy it, but who will be allowed to buy systems employing it. There is a desire among companies in Asia, particularly China, to buy indigenous components and systems wherever possible and there is some pressure in Europe and tons in the United States to buy systems that have Intel, AMD, IBM, or Marvell processors in them. There is plenty of talk about the security of these chips, with chatter about backdoors and security holes, and none of it within our purview to either confirm or deny. We have no idea, but we know the talk and we know the politics. Huawei has a strong infrastructure business in China, a pretty good one in Asia, a growing one in Africa, a foothold in Europe, very little chance in North America, and who knows about Central and South America. But if the server is fast and cheap, you can bet plenty of customers, no matter where they are located, will find a way to acquire it.

The Prospects For An Arm Server Insurrection
If you want to break into datacenter compute in a sustainable way, it takes the patience of a glacier. And not just any glacier, but one that predates the Industrial Revolution. The reason is that IT shops are a conservative lot, and change comes slowly, even when they seem to …
Intel Gets Its Chiplets In Order With 6th Gen Xeon SPs
Based on what Intel has been saying for the past several weeks in various events, but especially the Hot Chips 2023 a few weeks ago and the more recent Intel Innovation 2023 extravaganza, the company’s foundry process roadmap and its server processor roadmaps are going to align harmoniously to make …
AMD’s Instinct GPU Business Is Coiled To Spring
Timing is a funny thing. The summer of 2006 when AMD bought GPU maker ATI Technologies for $5.6 billion and took on both Intel in CPUs and Nvidia in GPUs was the same summer when researchers first started figuring out how to offload single-precision floating point math operations from CPUs …
The Chinese government is also pushing hard (and backing it with plenty cash) to move Chinese national hero companies away from any reliance on “foreign” CPU/GPUs. It wants to move into having the next big foundry. Hence the pressure to move gifted tech persons away from low national value business (games/ecommerce) and be attracted into making china independent from chip shortages or foreign reliance. I also doubt that any non chinese firm will want to have Chinese gov backed firm installing their own chips into the data servers they rely on to remain competitive. Like ICBMs controlled by chinese chips