
For the past five years, supercomputer maker Cray has been diligently at work not only creating a new system architecture that allows for a mix of different interconnects and compute for its future “Shasta” systems, but has also brought long-time Cray chief technology officer, Steve Scott, back into the company after two stints spent at Nvidia and Google to create a new interconnect, called “Slingshot,” that is the beating heart of the Shasta system and that signals a return of the Cray that we know and love.
The National Energy Research Scientific Computing Center at Lawrence Berkeley National Laboratory, one of the big HPC centers funded by the US Department of Energy and arguably its mission computing center (distinct from the nuclear simulation work done at Lawrence Livermore National Laboratory), with over 700 projects and more than 7,000 researchers wanting to play on its machinery.
The “Perlmutter” NERSC-9 system will be installed in late 2020 according to Nick Wright, leader of the Advanced Technologies Group at the NERSC, and it is a substantially different system than LBNL was pondering even two and a half years ago, when the lab proposed a compute architecture mixing different types of compute and memory onto a single compute element – something akin to a hybrid Xeon and Xeon Phi processor from Intel (which does not exist) or the Sunway processor in the TaihuLight system in China (which does).
(The future NERSC-9 machine is named after Saul Perlmutter, a Nobel Prize winning astrophysicist who works at LBNL.)
In the end, the successor to the current “Cori” NERSC-8 machine that Cray will build and support for $146 million will have its compute elements comprised of a future AMD Epyc processor and the next-generation Nvidia Tesla GPU accelerator. Presumably, this means the “Milan” kicker to next year’s “Rome” Epyc processors, which are sampling now and which are expected to launch in 2019. AMD is expected to reveal some of the feeds and speeds of the Rome Epycs next week in a big shindig in San Francisco alongside its launch of the “Vega+” GPUs for its Radeon Instinct accelerators. Nvidia has not put out a roadmap for its Tesla GPUs in years, but we hear the next one could be called “Einstein,” but that is a scary code-name because what do you do after that? Nvidia can ride the Volta architecture for quite a while if it needs to, doing a shrink to 7 nanometers from 12 nanometers at Taiwan Semiconductor Manufacturing Corp, beefing up the HBM memory capacity and bandwidth and maybe laying down some SMX modules of compute on the layer. It is hard to argue that Nvidia needs to do a big architectural leap after Volta, which is among the most complex and elegant chips ever made.
In any event, AMD, Nvidia, and LBNL are not talking specifics about the configuration of the Perlmutter machine.
“We are aiming for somewhere between 3X to 4X the peak theoretical and application performance of Cori – it is not precisely clear where we will end up right now,” Wright tells The Next Platform. It is, of course, the application performance that matters, not just cramming hundreds of peak petaflops or exaflops into a box. “NERSC has always procured its machines around application performance,” Wright adds. The idea is, of course, to get lots of performance in a system and try to utilize as much of it as possible.
The current Cori NERSC-8 machine at LBNL is a Cray XC40 system using the company’s “Aries” interconnect in a dragonfly topology that links together a bunch of “Haswell” Xeon E5 nodes to another bunch of “Knights Landing” Xeon Phi 7000 nodes. There are 14 cabinets of the Haswell iron, comprised of 2,388 nodes using E5-2698 v3 processors with 16 cores for a total of 2.81 petaflops of peak performance. The bulk of the compute capacity is on the Knights Landing nodes, of which there are 9,688 across 54 cabinets for a total of 29.5 peak petaflops. The Aries interconnect provides 45 TB/sec of global peak bi-section bandwidth across those nodes. Cori was one of the first machines to test out Cray’s DataWarp burst buffer, which is comprised of 288 nodes equipped flash that can deliver 1.7 TB/sec of throughput and that can deliver 28 million IOPS into and out of the system. The burst buffer, as the name suggests, sits between the Cray Sonexion Lustre parallel file system, which can only do 700 GB/sec of pushing and pulling.
It is probably not a good idea to assume that every Epyc server node of the Perlmutter system will include one or more GPUs, although that is a possibility. It is also possible that the Perlmutter system is based on single-socket Epyc nodes instead of the more traditional two-socket nodes, particularly if the economics work out and AMD jacks up the core counts bigtime with the Rome and Milan processors (as we suspect it will). Wright is not being specific at the moment, and that is most likely because the system details are still being worked out. After all, the Rome chips are probably six to nine months away, and Milan may come after that. We don’t expect a new high-end GPU from Nvidia until 2020, either. So there are, as Wright says, “a lot of moving parts here.”
The best reason to believe that the Perlmutter machine will have some CPU-only nodes and some hybrid CPU-GPU nodes is that the prior Cori machine had distinct types of computing in different slices of the cluster, and that according to the latest report from NERSC, not all of its codes are GPU accelerated yet. And some of them may prove very difficult to move to GPUs. Take a look:
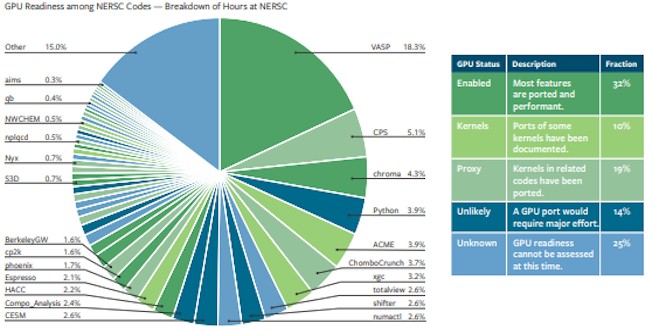
At this time, about 32 percent of its codes have been ported to GPUs and run pretty well, and another 10 percent have had some application kernels moved over; there are another 19 percent of NERSC’s codes that could be ported somewhat easily, and another 14 percent that can’t be moved and another 25 percent whose capability of running upon GPUs is unknown.
NERSC will no doubt have to balance the Perlmutter machine against how it thinks these numbers might move – or not.
“Some part of our workloads are not a great match for GPUs right now, for various reasons, so we will also be deploying CPU-based nodes in the system as well,” Wright explains. But there is also the potential to use other kinds of compute in the Shasta system from Cray, and this is not at all lost on LBNL. “If you look out into the future, you see a huge explosion in the number of kinds of processors that are viable to be used in a supercomputer, and because we have such a broad workload, one of the things that is very attractive about Shasta is that we can deploy more than one kind of computing architecture or element to address the broad needs of different components of the workload.”
When pressed about what compute elements were part of the Perlmutter bid, this is all Wright had only one comment: “All I can say is that we did a very thorough market survey as part of our procurement endeavors.”
The Cori system weighed in at 32.3 peak petaflops across those Xeon and Xeon Phi nodes, at a cost of $75 million, or $2,321 per teraflops. (Check out the HPC bang for the buck over time that we put together back in April for historical and future comparisons.) If the Perlmutter machine comes in at between 3X and 4X the performance of Cori, that is going to land it at somewhere between 96.9 petaflops and 129.2 petaflops of peak aggregate performance at a cost of $1,506 to $1,130 per teraflops. That is a pretty respectable improvement in bang for the buck and at the higher performance and lower range of cost, is consistent with what Oak Ridge and Lawrence Livermore paid for their respective “Summit” and “Sierra” hybrid IBM Power9-Nvidia Tesla clusters. In these two cases, however, the CPUs and GPUs are tightly coupled in all nodes of the system, and that is probably not going to happen with Perlmutter.
The Slingshot interconnect is the secret sauce of the Perlmutter machine – and so by design in that it marries a high radix Ethernet switch with 64 ports running at 200 Gb/sec, but also has an Ethernet protocol that has been enhanced with all kinds of HPC congestion control and adaptive routing that is the hallmark of the prior “Gemini” XT and Aries XC interconnects from Cray. (We have drilled down into the Shasta systems and the Slingshot interconnect in a separate article today.)
“That’s a really exciting aspect of the NERSC-9 architecture,” says Wright. “It has the Ethernet compatibility, so it is very easy to have the supercomputer talk to the outside world. One of the things we are doing more and more is connected supercomputers to telescopes or genomics sequencers or to other kinds of machines. The Ethernet capability of Slingshot actually makes this a heck of a lot easier because you can do some really sophisticated things with network packets to connect detectors directly to the memory or storage of the supercomputer.”
The Perlmutter system will have an all-flash file system based on Cray’s implementation of Lustre, with special optimizations for working on new non-volatile media and with more than 30 PB of capacity and more than 4 TB/sec of bandwidth.
“I think it is going to be one of the first supercomputers deployed that has an all-flash file system, so that’s really good for a lot of these experimental use cases because they are not like more traditional HPC checkpoint/restart file accesses with lots of sequential reads and sequential writes,” Wright says. “These applications have a fair amount of IOPS-bound access paths for data files, and you find that flash is much better than a traditional parallel file system based on spinning disk will be.”

Frontier: Step By Step, Over Decades, To Exascale
Any time you build anything with more than 60 million parts, it is going to be a headache. And if you have to create a space in a datacenter and build an exascale system with all of those parts, each of which is crucial, during a global pandemic, it gets …

Sneak Peek At “Sapphire Rapids” Xeons In “Crossroads” Supercomputer
Managing an aging nuclear weapons stockpile requires a tremendous – and ever-increasing – amount of supercomputing performance, and the HPC system business the world over is focused on this as much as trying to crack the most difficult scientific, medical, and engineering problems. Los Alamos National Laboratory has had its …
The AI Wave Finally Starts Lifting Dell And HPE
It is beginning to look like the Dell Technologies and Hewlett Packard Enterprose, the world’s two biggest original equipment manufacturers, are finally going to start benefitting from the generative AI wave, mainly because they are finally getting enough allocations of GPUs from Nvidia and AMD that they can start addressing …
Be the first to comment