

IT shops are notorious when it comes to avoiding risk, and this is something that we should be grateful for because it increases the odds that this increasingly compute-dependent world keeps working. This is why it takes any new compute engine so long to get established in the datacenter, and it can be frustrating for all parties – those who make the chips, those who make the systems, and those who want to buy them.
But eventually, if a technology can jump through all the hoops and qualifications, it can find a place and grow. This is the long term and patient plan that AMD has for both its Epyc processors and Radeon Instinct graphics coprocessors, and it looks like the company is executing to that plan in a way that is absolutely reminiscent of the “SledgeHammer” Opteron ramp back in the early 2000s.
AMD has not been shy about calling where it is going to blast the ball in 2018, and has declared that it believes it can exit this year with 5 percent of server unit shipment share based on the first generation “Naples” Epyc 7000 processors, and grow its business there to a natural market share in X86 compute in the datacenter. For the past decade, Intel’s Xeon processors have utterly dominated the X86 server market, and X86 servers have absolutely dominated in the datacenter, so taking share away from Intel is synonymous with eating datacenter market share.
To reach that 5 percent goal, AMD is going to have to have a killer fourth quarter. In a conference call with Wall Street analysts, Lisa Su, AMD’s president and chief executive officer, said that the company’s server business had “strong double digit” revenue growth sequentially from the second quarter to the third and that AMD was “about halfway” to that goal.
All it takes – and we think AMD will be able to do this – is for a few of the Super Eight hyperscalers and cloud builders to place some big orders before year end for lots of iron, and a few points of market share can shift in the snap of a finger. And it is reasonable to assume that this can happen, especially considering the nature of the code hyperscalers have – they write it and they can tune it very precisely to any architecture in a way that large enterprises can’t. Cloud builders run the workloads of other enterprises, and they are in some ways constrained by the code that those enterprise customers bring to the public cloud. So that means it is the hyperscalers and their peers in the HPC arena that will be setting the initial Epyc pace. None of this is a surprise, the strategy is sound. It will be important when it actually happens – and if it doesn’t. We shall see.
“We continue to build a strong pipeline and accelerate the ongoing ramps of Epyc-based offerings from the major OEMs, including Cisco Systems, Dell, and Hewlett Packard Enterprise,” Su said on the call. “In the third quarter, we added dozens of new end customers across oil and gas, healthcare, aerospace, banking and other industries, based on the superior performance of EPYC processors in both data analytics and general-purpose virtualized workloads. We began sampling our next generation Rome server chip broadly across our customer base in the third quarter. And the feedback on this leadership product is very strong. As a result, cloud and OEM customers are engaging earlier, deeper, and more collaboratively with us on both Rome, and our long-term data center roadmap. We remain on track to exit the year with mid-single digit server unit market share based on cloud customer adoption. And based on our strong competitive position and broad customer engagements, we believe we can achieve double-digit server unit share with Rome.”
We expect that AMD will soon raise the curtain a little on what goodies are coming in the Rome chip, perhaps at AMD’s Next Horizon event in San Francisco on November 6.
In the meantime, despite some excess inventory shipped into the reseller channel for its GPUs and a dramatic (and expected) decline in sales of GPUs geared for cryptocurrency customers, AMD is continuing to grow its revenues and is bringing money to the bottom line, which is what it has been able to do for the past five quarters running.
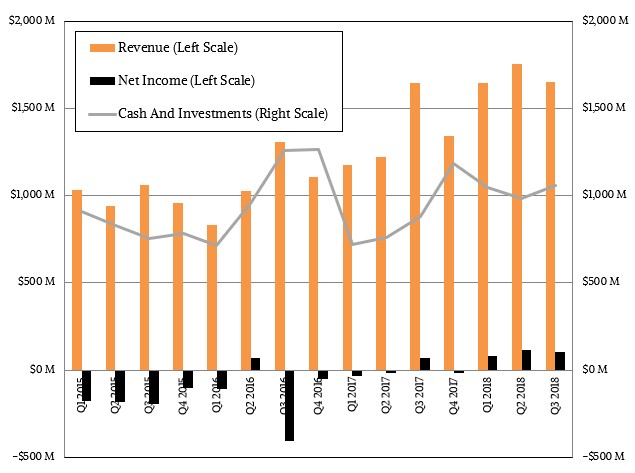
In the third quarter ended in September, AMD raked in $1.65 billion in sales, up 4.4 percent, and it brought $102 million of that to the bottom line, an increase of 67.2 percent compared to its net income in the year ago period.
The Computing and Graphics division of the company, which sells processors and GPUs for PCs, had a 12.3 percent revenue spike to $938 million in the quarter, thanks to the strength of sales of its Ryzen processors, which are based on the same Zen architecture as the Epyc server chips. The Ryzen line, in fact, comprised 70 percent of PC chip sales for AMD in the quarter, up from 60 percent in the second quarter, which is a nice jump. Operating income for the Computing and Graphics division came in at a flat $100 million, up 37 percent year on year.
The Epyc server chips are a multichip module version of the Ryzen chips, with extra goodies thrown in that specifically address the needs of a server, much as Intel’s Xeon processors are a superset of its Core processors for PCs. The uptick in Ryzen chip sales is due to a certain extent to Intel having issues making enough processors for its PC clients, but it is also due to AMD’s execution on its own strategy of creating a competitive PC chip and fighting hard to get the design wins from the major PC makers that is absolutely necessary for AMD to succeed. And just like Intel needs a healthy PC processor business to be able to afford to be in the server chip business – or at least to command the very large profits it extracts from the datacenter – AMD’s success in the datacenter is founded on its ability to sell PC chips. Which is the only reason we care about how the Ryzen chips are doing.
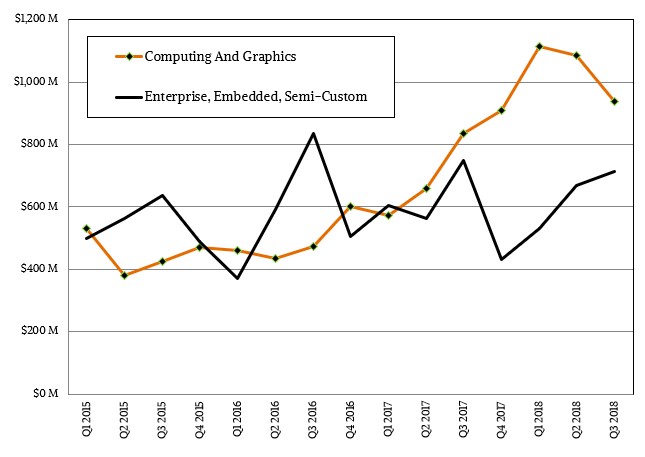
At the moment, AMD’s server business is buried inside of its Enterprise, Embedded, and Semi-Custom division, a hodge podge of businesses that are separate from the PC and includes its sales of custom processors for game consoles made by Sony and Microsoft as well as many other embedded applications as well as sales of the Epyc processors and Radeon and Radeon Instinct GPU coprocessors that are sold in servers. All told, this business pushed $715 million, down 4.5 percent mainly due to the end of the product cycle for those Sony and Microsoft game consoles; operating profits were nonetheless up 16.2 percent to $86 million, even with increased investments for the future “Rome” and “Milan” Epyc follow-ons to the current Naples chips as well as for the impeding 7 nanometer update to the “Vega” Radeon GPUs, which are widely expected to be announced at AMD’s Next Horizon event. The updated Vega will start shipping by the end of this year.
The exact details of the updated Vega 20 GPU are not known, but we covered the speculation back in June 2017 when the CPU and GPU roadmaps were first divulged by AMD. If the Vega 20, as the chip was sometimes called in earlier roadmaps, had the same 4,096 streaming processors and 64 compute units as the current Vega 10 chip used in the Radeon Instinct cards, then the shrink from 14 nanometer processes to the 7 nanometer processes alone would increase performance by around 20 percent, which would work out to around 15.7 teraflops at single precision. If AMD lets the clock rates go higher and the wattages rise, it could boost performance as high as 20 teraflops at single precision. AMD could shift to four stacks of HBM2 memory for a total capacity of 32 GB – this is widely rumored and puts AMD on par with Nvidia’s latest “Volta” GPUs used in its Tesla coprocessors; bandwidth could double or more, depending on how AMD turns the dials on memory speed, power draw, and heat dissipation. We hear that the updated Vega GPU will deliver 1 TB/sec bandwidth into and out of the HBM2 memory stacks. AMD could graft on CCIX coherency ports on the updated Vega to give Radeon Instinct cards something that looks and smells like NVLink ports on the high-end Tesla cards; we expect that the updated Vega GPU will plug into PCI-Express 4.0 x16 slots, which means a lot more bandwidth between the CPU and the GPU.
In the long run, the important thing is that the Radeon GPU eventually needs double precision, suitable for certain HPC codes – something that AMD has been lacking. This might have been slated for the future “Navi” Radeon GPU, which we also think needs to support 16-bit half precision, which is important for certain inference workloads, and we would not be surprised if other mixed precisions and formats are supported, too. We had hoped that such a GPU would come out in late 2018, to be frank, whether it is a Vega or Navi design, and it looks like AMD has managed to hack double precision running at half single precision into the architecture. Which is good.
We think that CCIX ports might come with Navi as well, which will be the second GPU chip from AMD implemented in 7 nanometer processes. In those roadmaps from last year, there was no 7 nanometer Vega chip, which was slotted in as it became apparent that Globalfoundries, which had made the Radeon cards, was not going to be able to deliver on its 7 nanometer promises. Globalfoundries spiked its 7 nanometer efforts, which included both traditional water immersion lithography as well as new extreme ultraviolet (EUV) approaches, supposedly to mitigate risk, back in August. So now AMD is all-in with Taiwan Semiconductor Manufacturing Corp and its 7 nanometer etching, and we will soon see what kind of advantage this really is.


The Impending AMD Milan Versus Intel Ice Lake Server Showdown
What a strange server CPU world we live in. The dozen or so biggest customers in the world command something on the order of 45 percent of the server CPU shipments, but significantly lower share of the revenue because of the volume discounts they can command, and they not only …

Porting to AMD GPUs in the Corona Age
“Times were simpler not so long ago” is an understatement these days, but when it comes to supercomputing, this has yet another meaning. The early days of GPUs brought some challenges, but dedication from developers and Nvidia to make sure as many HPC codes were ported and CUDA-ready over the …
Pondering That Rumored $30 Billion AMD Acquisition Of Xilinx
You can have a strategy, but you can’t buy one. Nothing illustrates this principle more than the networking buying binges that both Intel and AMD went on nearly a decade ago, which did not really amount to much in the end but which made some sort of sense in the …
It better hurry as my stock portfolio is taking a huge beating
“AMD could graft on CCIX coherency ports on the updated Vega to give Radeon Instinct cards something that looks and smells like NVLink ports on the high-end Tesla cards”
No Vega 20 will support(1) what is called xGMI(Infinity Fabric Based) for GPUs so that’s what will be similar to Nvidia’s Nvlink IP. Also AMD is a founding member of OpenCAPI so maybe there can be that support also for any OpenPower Power CPU to AMD GPU interfacing. Maybe AMD will offer a dual Vega 20 DIEs on a single PCIe card variant similar to the dual GPU variants that AMD has offered in the past, and currently(Radeon Pro V340 uses 2 Vega 10 DIEs in a Binned Vega 10/3584-SPs-enabled-per-die configuration), to get more Compute onto a single PCIe card.
That TSMC 7nm process node should afford greater power savings at the same clock speeds so maybe AMD can double up the Vega 20 DIEs at 7nm and still make the power budget while doubling the SP counts to 8192 and get double the compute that way. xGMI(infinity fabric) could be used to wire up 2 Vaga 20 dies across the PCIe card’s PCB instead of using PCIe. The same route as AMD does in a similar manner on Epyc with each Zen/Zeppelin die making us of GMI(Infinity Fabric Based) coherency traffic across the sockets on Epyc/SP3 motherboards via taking over some PCIe PHY lanes.
It’s the Infinity Fabric that’s AMD’s answer to Nvidia’s NVLink and IF is similar to IBM’s BlueLink in scope. So xGMI for GPUs just like GMI is for Epyc to bring the Infinity Fabric across the socket for Epyc/SP3.
Vega has always had the Infinity Fabric IP included so Vega 20 will finally bring that support for cross GPU DIEs coherecy via an external IF protocol interface called xGMI. And Infinity Fabric is similar to NVLink in that ability to have 2/or more GPUs interfaced in such a coherent manner as to appear more like one logical larger GPU to the software.
“XGMI is a peer-to-peer high-speed interconnect and is based on Infinity Fabric. XGMI is basically AMD’s alternative to NVIDIA’s NVLink for inter-connecting GPUs. ” (1)
[Note: All of AMD’s Current large Desktop/Accelerator Discrete GPUs are based on that one “Vega 10” Base die Tapeout with 4096 SPs. So that’s the Radeon Pro WX 9100 and Radeon instinct MI25, Vega 64(the full 4096 SPs enabled) and Vega 56(3584 SP enabled/binned Vega 10 die). And there already is a dual Vega 10 die based SKU, the Radeon Pro V340 dual(3584 SPs enable dies) for a total of 7168 SPs on one PCIe card and that SKU is for Datacenter Visualization Workloads. The only reason that AMD has not offered any Full Vega 10(4096 SP enabled) Dual GPU/Single PCIe card variants at 14nm is power delivery and power budget constraints, but that may change at 7nm if TSMC’s process affords AMD the opportunity of creating a dual Vega 20 on one PCIe card Compute/AI variant if the power delivery and power budget constraints allow, thermal constraints also]
(1)
“Radeon Vega 20 Will Have XGMI – Linux Patches Posted For This High-Speed Interface”
https://www.phoronix.com/scan.php?page=news_item&px=AMDGPU-XGMI-Vega20-Patches
“We had hoped that such a GPU would come out in late 2018, to be frank, whether it is a Vega or Navi design, and it looks like AMD has managed to hack double precision running at half single precision into the architecture. Which is good.”
Seriously? DO you actaully believe your own BS or have you drunk your own kool-aid?